神经网络之卷积篇:详解单层卷积网络(One layer of a convolutional network)
详解单层卷积网络
如何构建卷积神经网络的卷积层,下面来看个例子。
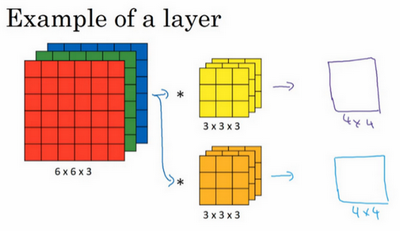
已经写了如何通过两个过滤器卷积处理一个三维图像,并输出两个不同的4×4矩阵。假设使用第一个过滤器进行卷积,得到第一个4×4矩阵。使用第二个过滤器进行卷积得到另外一个4×4矩阵。
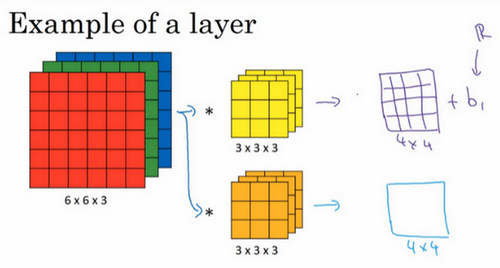
最终各自形成一个卷积神经网络层,然后增加偏差,它是一个实数,通过Python的广播机制给这16个元素都加上同一偏差。然后应用非线性函数,为了说明,它是一个非线性激活函数ReLU,输出结果是一个4×4矩阵。
对于第二个4×4矩阵,加上不同的偏差,它也是一个实数,16个数字都加上同一个实数,然后应用非线性函数,也就是一个非线性激活函数ReLU,最终得到另一个4×4矩阵。然后重复之前的步骤,把这两个矩阵堆叠起来,最终得到一个4×4×2的矩阵。通过计算,从6×6×3的输入推导出一个4×4×2矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
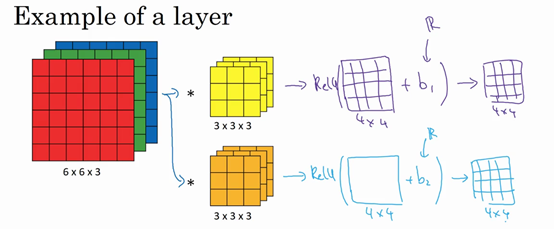
注意前向传播中一个操作就是\(z^{[1]} = W^{[1]}a^{[0]} + b^{[1]}\),其中\(a^{[0]} =x\),执行非线性函数得到\(a^{[1]}\),即\(a^{[1]} = g(z^{[1]})\)。这里的输入是\(a^{\left\lbrack 0\right\rbrack}\),也就是\(x\),这些过滤器用变量\(W^{[1]}\)表示。在卷积过程中,对这27个数进行操作,其实是27×2,因为用了两个过滤器,取这些数做乘法。实际执行了一个线性函数,得到一个4×4的矩阵。卷积操作的输出结果是一个4×4的矩阵,它的作用类似于\(W^{[1]}a^{[0]}\),也就是这两个4×4矩阵的输出结果,然后加上偏差。
这一部分(图中蓝色边框标记的部分)就是应用激活函数ReLU之前的值,它的作用类似于\(z^{[1]}\),最后应用非线性函数,得到的这个4×4×2矩阵,成为神经网络的下一层,也就是激活层。
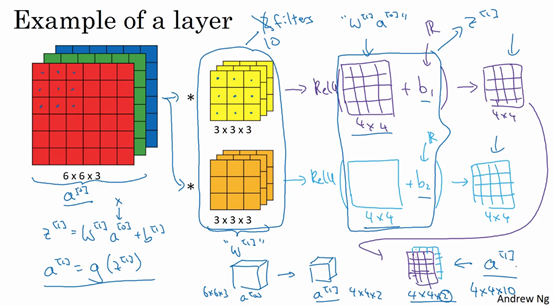
这就是\(a^{[0]}\)到\(a^{[1]}\)的演变过程,首先执行线性函数,然后所有元素相乘做卷积,具体做法是运用线性函数再加上偏差,然后应用激活函数ReLU。这样就通过神经网络的一层把一个6×6×3的维度\(a^{[0]}\)演化为一个4×4×2维度的\(a^{[1]}\),这就是卷积神经网络的一层。
示例中有两个过滤器,也就是有两个特征,因此才最终得到一个4×4×2的输出。但如果用了10个过滤器,而不是2个,最后会得到一个4×4×10维度的输出图像,因为选取了其中10个特征映射,而不仅仅是2个,将它们堆叠在一起,形成一个4×4×10的输出图像,也就是\(a^{\left\lbrack1 \right\rbrack}\)。
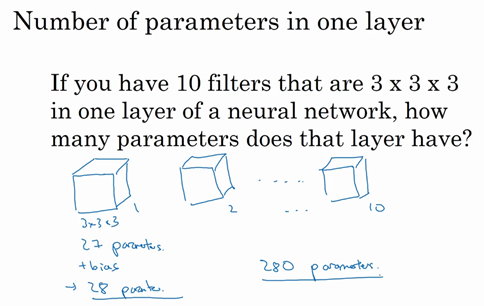
为了加深理解,来做一个练习。假设有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数\(b\)表示,现在参数增加到28个。里画了2个过滤器,而现在有10个,加在一起是28×10,也就是280个参数。
请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。用这10个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作“避免过拟合”。这时已经知道到如何提取10个特征,可以应用到大图片中,而参数数量固定不变,此例中只有28个,相对较少。
最后总结一下用于描述卷积神经网络中的一层(以\(l\)层为例),也就是卷积层的各种标记。

这一层是卷积层,用\(f^{[l]}\)表示过滤器大小,说过过滤器大小为\(f×f\),上标\(\lbrack l\rbrack\)表示\(l\)层中过滤器大小为\(f×f\)。通常情况下,上标\(\lbrack l\rbrack\)用来标记\(l\)层。用\(p^{[l]}\)来标记padding的数量,padding数量也可指定为一个valid卷积,即无padding。或是same卷积,即选定padding,如此一来,输出和输入图片的高度和宽度就相同了。用\(s^{[l]}\)标记步幅。
这一层的输入会是某个维度的数据,表示为\(n \times n \times n_{c}\),\(n_{c}\)某层上的颜色通道数。
要稍作修改,增加上标\(\lbrack l -1\rbrack\),即\(n^{\left\lbrack l - 1 \right\rbrack} \times n^{\left\lbrack l -1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack}\),因为它是上一层的激活值。
此例中,所用图片的高度和宽度都一样,但它们也有可能不同,所以分别用上下标\(H\)和\(W\)来标记,即\(n_{H}^{\left\lbrack l - 1 \right\rbrack} \times n_{W}^{\left\lbrack l - 1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack}\)。那么在第\(l\)层,图片大小为\(n_{H}^{\left\lbrack l - 1 \right\rbrack} \times n_{W}^{\left\lbrack l - 1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack}\),\(l\)层的输入就是上一层的输出,因此上标要用\(\lbrack l - 1\rbrack\)。神经网络这一层中会有输出,它本身会输出图像。其大小为\(n_{H}^{[l]} \times n_{W}^{[l]} \times n_{c}^{[l]}\),这就是输出图像的大小。
前面提到过,这个公式给出了输出图片的大小,至少给出了高度和宽度,\(\lfloor\frac{n+2p - f}{s} + 1\rfloor\)(注意:(\(\frac{n + 2p - f}{s} +1)\)直接用这个运算结果,也可以向下取整)。在这个新表达式中,\(l\)层输出图像的高度,即\(n_{H}^{[l]} = \lfloor\frac{n_{H}^{\left\lbrack l - 1 \right\rbrack} +2p^{[l]} - f^{[l]}}{s^{[l]}} +1\rfloor\),同样可以计算出图像的宽度,用\(W\)替换参数\(H\),即\(n_{W}^{[l]} = \lfloor\frac{n_{W}^{\left\lbrack l - 1 \right\rbrack} +2p^{[l]} - f^{[l]}}{s^{[l]}} +1\rfloor\),公式一样,只要变化高度和宽度的参数便能计算输出图像的高度或宽度。这就是由\(n_{H}^{\left\lbrack l - 1 \right\rbrack}\)推导\(n_{H}^{[l]}\)以及\(n_{W}^{\left\lbrack l - 1\right\rbrack}\)推导\(n_{W}^{[l]}\)的过程。
那么通道数量又是什么?这些数字从哪儿来的?来看一下。输出图像也具有深度,通过上一个示例,知道它等于该层中过滤器的数量,如果有2个过滤器,输出图像就是4×4×2,它是二维的,如果有10个过滤器,输出图像就是4×4×10。输出图像中的通道数量就是神经网络中这一层所使用的过滤器的数量。如何确定过滤器的大小呢?知道卷积一个6×6×3的图片需要一个3×3×3的过滤器,因此过滤器中通道的数量必须与输入中通道的数量一致。因此,输出通道数量就是输入通道数量,所以过滤器维度等于\(f^{[l]} \times f^{[l]} \times n_{c}^{\left\lbrack l - 1 \right\rbrack}\)。

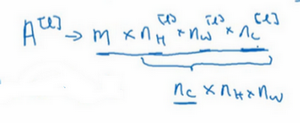
应用偏差和非线性函数之后,这一层的输出等于它的激活值\(a^{[l]}\),也就是这个维度(输出维度)。\(a^{[l]}\)是一个三维体,即\(n_{H}^{[l]} \times n_{W}^{[l]} \times n_{c}^{[l]}\)。当执行批量梯度下降或小批量梯度下降时,如果有\(m\)个例子,就是有\(m\)个激活值的集合,那么输出\(A^{[l]} = m \times n_{H}^{[l]} \times n_{W}^{[l]} \times n_{c}^{[l]}\)。如果采用批量梯度下降,变量的排列顺序如下,首先是索引和训练示例,然后是其它三个变量。
该如何确定权重参数,即参数W呢?过滤器的维度已知,为\(f^{[l]} \times f^{[l]} \times n_{c}^{[l - 1]}\),这只是一个过滤器的维度,有多少个过滤器,这(\(n_{c}^{[l]}\))是过滤器的数量,权重也就是所有过滤器的集合再乘以过滤器的总数量,即\(f^{[l]} \times f^{[l]} \times n_{c}^{[l - 1]} \times n_{c}^{[l]}\),损失数量L就是\(l\)层中过滤器的个数。
最后看看偏差参数,每个过滤器都有一个偏差参数,它是一个实数。偏差包含了这些变量,它是该维度上的一个向量。为了方便,偏差在代码中表示为一个1×1×1×\(n_{c}^{[l]}\)的四维向量或四维张量。
卷积有很多种标记方法,这是最常用的卷积符号。大家在线搜索或查看开源代码时,关于高度,宽度和通道的顺序并没有完全统一的标准卷积,所以在查看GitHub上的源代码或阅读一些开源实现的时候,会发现有些作者会采用把通道放在首位的编码标准,有时所有变量都采用这种标准。实际上在某些架构中,当检索这些图片时,会有一个变量或参数来标识计算通道数量和通道损失数量的先后顺序。只要保持一致,这两种卷积标准都可用。很遗憾,这只是一部分标记法,因为深度学习文献并未对标记达成一致,但会采用这种卷积标识法,按高度,宽度和通道损失数量的顺序依次计算。
神经网络之卷积篇:详解单层卷积网络(One layer of a convolutional network)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 神经网络基础部件-BN层详解
一,数学基础 1.1,概率密度函数 1.2,正态分布 二,背景 2.1,如何理解 Internal Covariate Shift 2.2,Internal Covariate Shift 带来的问题 ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
- CentOS 7 下编译安装lnmp之MySQL篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.MySQL下载 MySQL ...
- CentOS 7 下编译安装lnmp之nginx篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:CentOS Linux release 7.5.1804 (Core),ip地址 192.168.1.168 ...
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- java提高篇-----详解java的四舍五入与保留位
转载:http://blog.csdn.net/chenssy/article/details/12719811 四舍五入是我们小学的数学问题,这个问题对于我们程序猿来说就类似于1到10的加减乘除那么 ...
随机推荐
- [好物推荐] Rime的86五笔输入法配置
一个比较好用的Rime五笔输入法配置文件, 个人已经使用很多年了. 官网: https://github.com/KyleBing/rime-wubi86-jidian 安装方式: /home/xxx ...
- Freertos学习:07-队列
--- title: rtos-freertos-07-队列 EntryName : rtos-freertos-07 date: 2020-06-23 09:43:28 categories: ta ...
- 手把手教你解决spring boot导入swagger2版本冲突问题,刘老师教编程
手把手教你解决spring boot导入swagger2版本冲突问题 本文仅为个人理解,欢迎大家批评指错 首先Spring Boot 3 和 Swagger 2 不兼容.在 Spring Boot 3 ...
- Mysql与Redis如何保证数据的一致性?
问题分析: 当MySQL中的数据发生更新时,就面临一个问题,如何确保MySQL与Redis数据的一致性,我们有两个选择: 先更新MySQL,后删除(或更新)Redis 先删除(或更新)Redis,后更 ...
- HBase 在统一内容平台业务的优化实践
作者:来自 vivo 互联网服务器团队-Leng Jianyu.Huang Haitao HBase是一款开源高可靠性.扩展性.高性能和灵活性的分布式非关系型数据库,本文围绕数据库选型以及使用HBas ...
- SMOTE与SMOGN算法R语言代码
本文介绍基于R语言中的UBL包,读取.csv格式的Excel表格文件,实现SMOTE算法与SMOGN算法,对机器学习.深度学习回归中,训练数据集不平衡的情况加以解决的具体方法. 在之前的文章S ...
- [oeasy]python021_赛博宝剑铭文大赏_宝剑上的铭文_特殊符号和宝物
继续运行 回忆上次内容 上次修改了 程序 将 石中剑 变成了 红色 爱之大剑 添加图片注释,不超过 140 字(可选) 可以 让宝剑 具有 更多 铭文符号 和 颜色 吗? 铭文 亚 ...
- vue小知识~注入provide!
注入表示的是将该组件的相关值,方法,实例向后代组件注入. 祖先元素中定义注入: export default { provide() { return { provideName: provideVa ...
- 【JavaScript高级01】JavaScript基础深入
1,数据类型 JavaScript将数据分为六大类型,分别为数值类型(number).字符串类型(string).布尔类型(boolean).undefined(定义未赋值).null(赋值为空值). ...
- 03-springboot使用单元测试和日志框架
目录 1,springboot使用单元测试 2,使用日志框架 1,springboot使用单元测试 A:springboot使用单元测试需要引入一个单元测试启动器,该启动器的坐标为: <depe ...