Classification and Decision Trees
分类和决策树(DT)。
决策树是预测建模机器学习的一种重要算法。
决策树模型的表示是二叉树。就是算法和数据结构中的二叉树,没什么特别的。每个节点表示一个单独的输入变量(x)和该变量上的左右孩子(假设变量为数值)。
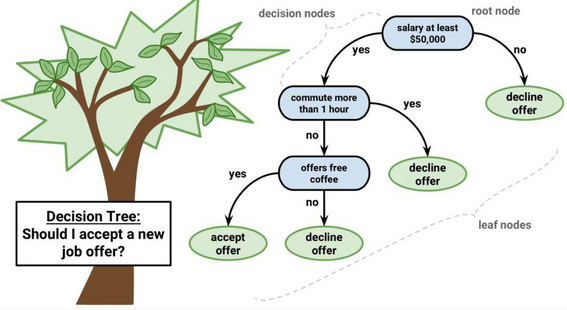
树的叶节点包含一个输出变量(y),用于进行预测。通过遍历树,直到到达叶节点并输出叶节点的类值,就可以做出预测。
树的学习速度很快,预测的速度也很快。它们通常也适用于广泛的问题,不需要对数据进行任何特别的准备。
决策树有很高的方差,并且可以在使用时产生更准确的预测。
特点及应用
决策树的特点是它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。
虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。
举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
因为DT能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
优点:
1.概念简单,计算复杂度不高,可解释性强,输出结果易于理解;
2.数据的准备工作简单, 能够同时处理数据型和常规型属性,其他的技术往往要求数据属性的单一。
3.对中间值得确实不敏感,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
4.应用范围广,可以对很多属性的数据集构造决策树,可扩展性强。决策树可以用于不熟悉的数据集合,并从中提取出一些列规则 这一点强于KNN。
缺点:
1.容易出现过拟合;
2.对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
3. 信息缺失时处理起来比较困难。 忽略数据集中属性之间的相关性。
Classification and Decision Trees的更多相关文章
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- Logistic Regression Vs Decision Trees Vs SVM: Part I
Classification is one of the major problems that we solve while working on standard business problem ...
- Machine Learning Methods: Decision trees and forests
Machine Learning Methods: Decision trees and forests This post contains our crib notes on the basics ...
- 壁虎书6 Decision Trees
Decision Trees are versatile Machine Learning algorithms that can perform both classification and re ...
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
随机推荐
- drf源码系列
过滤器 对查询出来的数据进行筛选可写可不写 from rest_framework.filters import BaseFilterBackend 源码 ''' def filter_queryse ...
- HTTP: Request中的post和get区别
* GET和POST之间的主要区别 1.GET是从服务器上获取数据,POST是向服务器传送数据. 2.在客户端, get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段 ...
- 国内P2P网贷行业再次大清理,仅剩646家
最近有网贷行业头部网站流出消息,国内网贷行业再次迎来大洗牌 清扫之后网贷的平台数量仅剩646家,数量陡降 根据小编了解.自2007年国外网络借贷平台模式引入中国以来,由于国家一时没有做出相应规定个条例 ...
- 全栈项目|小书架|服务器端-NodeJS+Koa2 实现点赞功能
效果图 接口分析 通过上面的效果图可以看出,点赞入口主要是在书籍的详情页面. 而书籍详情页面,有以下几个功能是和点赞有关的: 获取点赞状态 点赞 取消点赞 所以项目中理论上与点赞相关的接口就以上三个. ...
- Linux生产环境上,最常用的一套“AWK“技巧【转】
最有用系列: <Linux生产环境上,最常用的一套“vim“技巧> <Linux生产环境上,最常用的一套“Sed“技巧> <Linux生产环境上,最常用的一套“AWK“技 ...
- JavaScript之定时器
(1)单次定时器 setTimeout(function(){执行的动作},时间:ms) 单次定时器,一般用于函数节流 案例: var timer=setTimeout(function(){ doc ...
- Mac版StarUML破解方法
StarUML是用nodejs写的.确切的说是用Electron前端框架写的.新版本中所有的starUML源代码是通过asar工具打包而成.确切的代码位置在“%LOCALAPPDATA%\Progra ...
- jstorm了解—应用场景
JStorm处理数据的方式是基于消息的流水线处理, 因此特别适合无状态计算,也就是计算单元的依赖的数据全部在接受的消息中可以找到, 并且最好一个数据流不依赖另外一个数据流. 因此,常常用于: 日志分析 ...
- sql 查询某个字段最长的记录
sql 查询文本字段中值的长度最长的记录 一.函数1.SQL ServerLEN() 函数返回文本字段中值的长度.SELECT LEN(column_name) FROM table_name;2. ...
- Hive使用过程中踩过的坑
hive启动时错误1 Cannot execute statement:impossible to write to binary long since BINLOG_FORMAT = STATEME ...