python系列:二、Urllib库的高级用法
1.设置Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。
打开我们的浏览器,调试浏览器F12,出现一个新的界面,实质上这个页面包含了许许多多的内容,这些内容也不是一次性就加载完成的,实质上是执行了好多次请求,一般是首先请求HTML文件,然后加载JS,CSS 等等,经过多次请求之后,网页的骨架和肌肉全了,整个网页的效果也就出来了。
拆分这些请求,我们只看一第一个请求,你可以看到,有个Request URL,还有headers,下面便是response。
其中,agent就是请求的身份,如果没有写入请求身份,那么服务器不一定会响应,所以可以在headers中设置agent。

这样,我们设置了一个headers,在构建request时传入,在请求时,就加入了headers传送,服务器若识别了是浏览器发来的请求,就会得到响应。
另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
headers = { 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' , 'Referer':'http://www.zhihu.com/articles' }
同上面的方法,在传送请求时把headers传入Request参数里,这样就能应付防盗链了。
另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
2. Proxy(代理)的设置
urllib 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理。

3.Timeout 设置
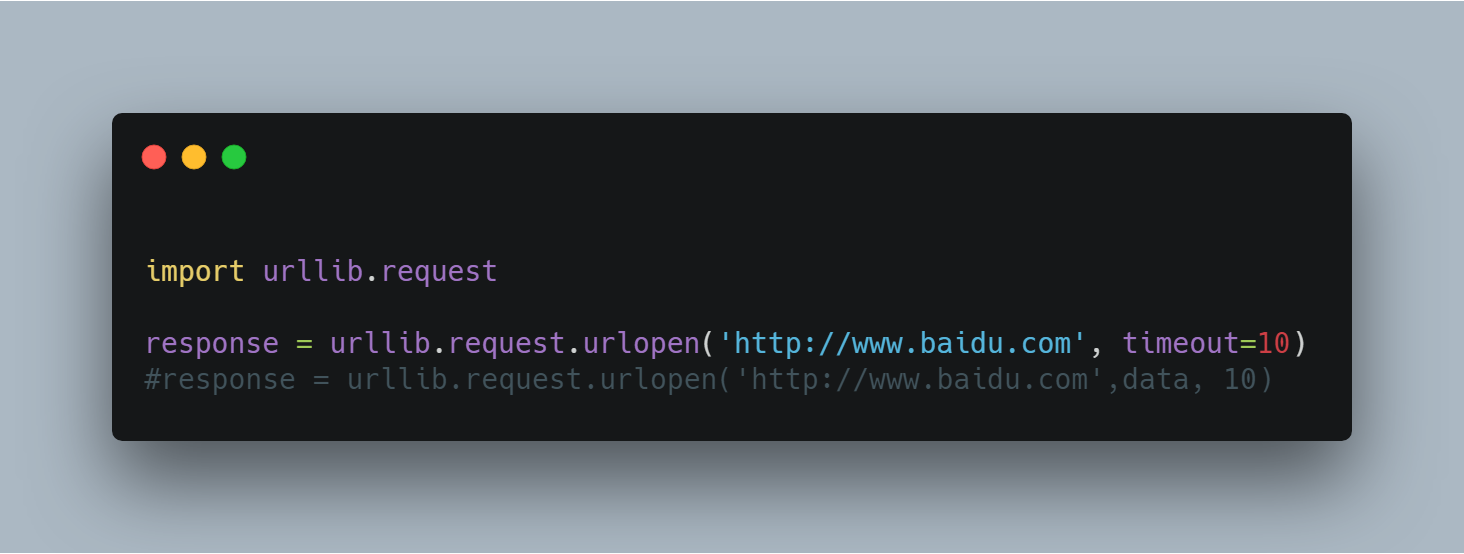
如果第二个参数data为空那么要特别指定是timeout是多少,写明形参,如果data已经传入,则不必声明。
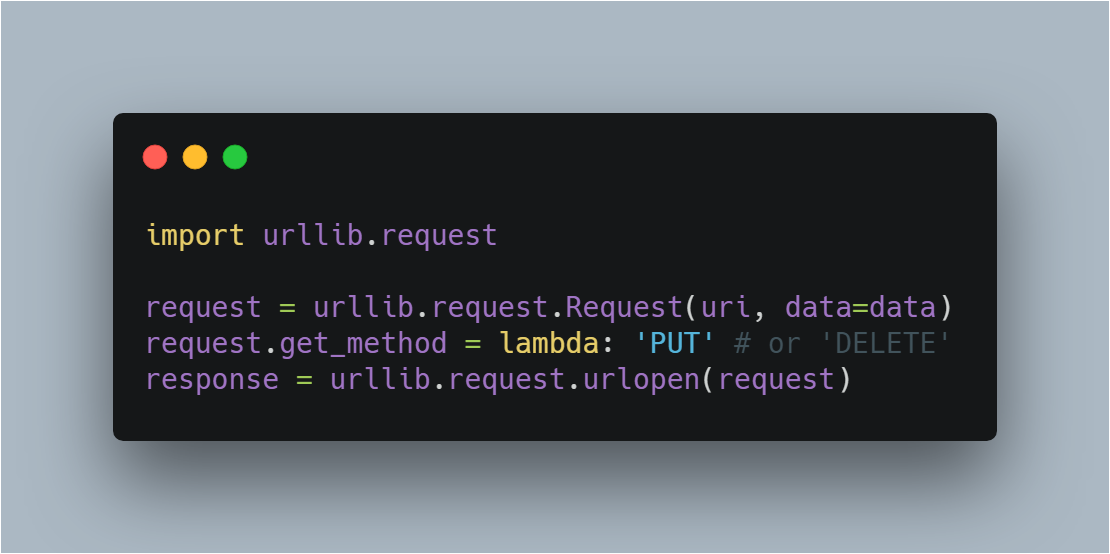
4.使用 HTTP 的 PUT 和 DELETE 方法
http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求。
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求,不过用的次数的确是少,在这里提一下。
5.使用DebugLog
可以通过下面的方法把 Debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,这个也不太常用,仅提一下

以上便是一部分高级特性,前三个是重要内容,在后面,还有cookies的设置还有异常的处理。
python系列:二、Urllib库的高级用法的更多相关文章
- python 爬虫2 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. import url ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- angular的路由例子
app.routing.module.ts里面,关键部分 const routes: Routes = [ { path: '', redirectTo : 'c3/c2/mmc', pathMatc ...
- layui flow loading占位图实现方法
如果流图片要加载失败, 就会显示找不到图片的裂痕 代码如下: <!DOCTYPE html> <html> <head> <meta charset=&quo ...
- 【iCore4 双核心板_FPGA】实验二十:NIOS II之UART串口通信实验
实验指导书及源代码下载地址: 链接:https://pan.baidu.com/s/1g_tWYYJxh4EgiGvlfkVu1Q 提取码:dwwa 复制这段内容后打开百度网盘手机App,操作更方便哦 ...
- linux安装nvm和nodejs
下载nvm包: [root@centos ~]# wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.33.11/install ...
- Ubuntu 上多版本软件管理方法
https://linuxize.com/post/how-to-install-gcc-compiler-on-ubuntu-18-04/ sudo apt install software-pro ...
- 开发日记:Windows进程守护工具
近期,中心应用服务无故关闭.在检查系统和应用程序日志无果后采取了进程守护的方法.测试期内,脚本未出现系统资源占用过多的情况. 使用说明:1.进程守护.vbs 使用时需修改运行周期(10行).守护进程 ...
- C++11 并发编程库
C++11 并发编程 C++11 新标准中引入了几个头文件来支持多线程编程,他们分别是: <atomic>:该头文主要声明了两个类, std::atomic 和 std::atomic_f ...
- swoole实验版聊天室
“swoole实验版聊天室”是依据一堂swoole培训课内容改编的,结合了bootstrap前端框架.redis数据库.jquery框架等实现基本功能,只是体现了swoole的应用,并不是为了专门写个 ...
- 常用的js片段
1.检查是否为微信浏览器 function isWxBrowser() { var ua = navigator.userAgent.toLowerCase(); if (ua.match(/Micr ...
- 【Spring Cloud学习之一】微服务架构
一.网站架构模式发展 单体应用-->SOA-->微服务 1.分布式项目与项目集群分布式项目:根据业务需求进行拆分成N个子系统,多个子系统相互协作才能完成业务流程子系统之间通讯使用RPC远程 ...