Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的
使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据
爬虫工具
使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文档对象,并提取职位信息。
爬取过程
1.请求地址
https://www.lagou.com/zhaopin/Python/
2.需要爬取的内容
(1)岗位名称
(2)薪资
(3)公司所在地
3.查看html
使用FireFox浏览器,登陆拉勾网,按F12可以进入开发者工具页面:
这时候会看到该页面的html网页源码。
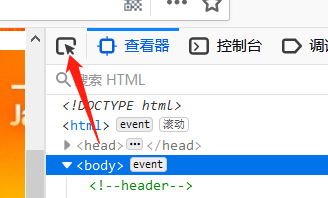
接下来需要寻找岗位信息对应的源码,比如岗位名称:

在开发者工具页面左上角有个箭头标志,点击它,然后再点击岗位名称,就能看到对应的源码。
知道对应的源码后,还需要知道请求头:
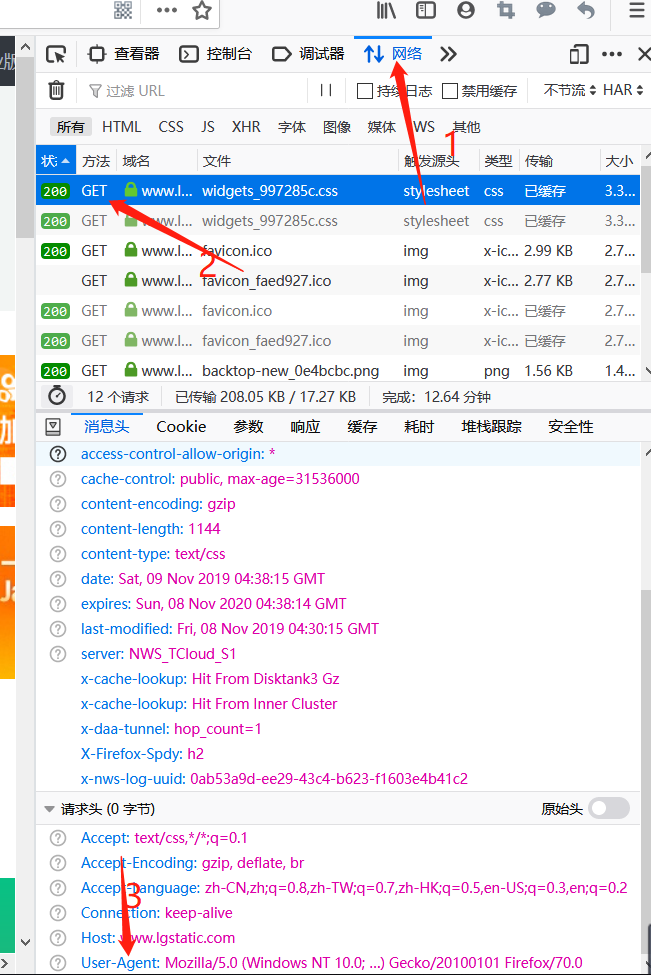
点击“网络”,之后点击“get”,在最下方User-Agent中的内容就是请求头
(如果是使用Chrome浏览器或者其它浏览器方法会有所不同)
完成上述操作后就可以利用BeautifulSoup4提取里面的文本。
利用requests发出数据请求
import requests
import io
import sys
from bs4 import BeautifulSoup
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',}
r = requests.get('https://www.lagou.com/zhaopin/Python/',headers=headers) #设置请求头
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser') #创建一个BeautifulSoup对象
利用BeautifulSoup提取网页数据
b=[] #创建空列表用来存储爬取的数据
a=[]
d=[]
name = bs.find_all('h3') #获取所有包含'h3'标签的内容
’
for h3 in name:
b.append(h3.string)
money = bs.find_all('span',attrs={'class':'money'})
for span in money:
a.append(span.string) #获取字符串形式的数据
ltd=bs.find_all('em')
for em in ltd:
d.append(em.string)
i=0
print("职业:"," 薪资:"," 地点:")
try:
while True:
print(b[i],a[i],d[i])
i+=1
except IndexError:
print()
Python爬虫入门——使用requests爬取python岗位招聘数据的更多相关文章
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么? 爬虫就是获取网络上各种资源,数据的一种工具.具体的可以自行百度. 二,如何写简单爬虫 1,获取网页内容 可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载. ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
随机推荐
- .NET Core开源Quartz.Net作业调度框架实战演练
一.需求背景 人生苦短,我用.NET Core!作为一枚后端.NET开发人员,项目实践常遇到定时Job任务的工作,在Windows平台最容易想到的的思路Windows Service服务应用程序,而在 ...
- C#反射机制(转自Binfire博客)
一:反射的定义 审查元数据并收集关于它的类型信息的能力.元数据(编译以后的最基本数据单元)就是一大堆的表,当编译程序集或者模块时,编译器会创建一个类定义表,一个字段定义表,和一个方法定义表等. Sys ...
- 【springcloud】【idea】启动服务报错Command line is too long. Shorten command line for XXXApplication or also for Spring Boot default configuration.
在workspace.xml 在标签<component name="PropertiesComponent">里 添加<property name=" ...
- find和grep的使用
1.find命令的使用 在Linux中可以使用find命令在指定的目录下查找文件.任何位于参数之前的字符串都将被视为欲查找的目录名,当使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目 ...
- Angular 修改路由策略,改为使用hash路由,即带#号URL
修改app.module.ts如下
- PHP 跨域资源共享 CORS 设定
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing). 它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从 ...
- Referenced file contains errors (http://www.springframework.org/...解决
今天打开老项目出现如下错误: Referenced file contains errors (http://www.springframework.org/schema/context/spring ...
- JSON学习(一)
JSON: 1. 概念: JavaScript Object Notation JavaScript对象表示法 Person p = new Person(); p.setName(" ...
- day49——圆形头像、定位、z-index、js
day49 今日内容 圆形头像 <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- Linux系统 关机/重启/用户切换/注销,用户管理(用户创建/修改,用户组增加/删除),Linux中 / 和 ~ 的区别
1.关机/重启命令 shutdown命令 shutdown -h now :立即关机 shutdown -h 1 :1分钟后关机 shutdown -r now :立即重启 shutdown -r 1 ...