Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么?
爬虫就是获取网络上各种资源,数据的一种工具。具体的可以自行百度。
二,如何写简单爬虫
1,获取网页内容
可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载。实现起来很简单
import urllib.request url="http://www.baidu.com"
response=urllib.request.urlopen(url)
html_content=response.read()
还可以使用三方库 requests ,实现起来也非常方便,在使用之前当然你需要先安装这个库:pip install requests 即可(Python 3以后的pip非常好使)
import requests html_content=requests.get(url).text
2, 解析网页内容
获取的网页内容html_content,其实就是html代码,我们需要对其进行解析,获取我们所需要的内容。
解析网页的方法有很多,这里我介绍的是BeautifullSoup,由于这是一个三方库,在使用前 还是要先安装 :pip install bs4
form bs4 imort BeautifullSoup soup= BeautifullSoup(html_content, "html.parser")
更多使用方法请参考官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
三,实例分析
弄懂爬虫原理的最好办法,就是多分析一些实例,爬虫千变万化,万变不离其宗。废话少说上干货。
===================================我是分割线===================================================
需求:爬取小米应用商店的TOP n 应用
通过浏览器打开小米应用商店排行棒页面,F12审查元素
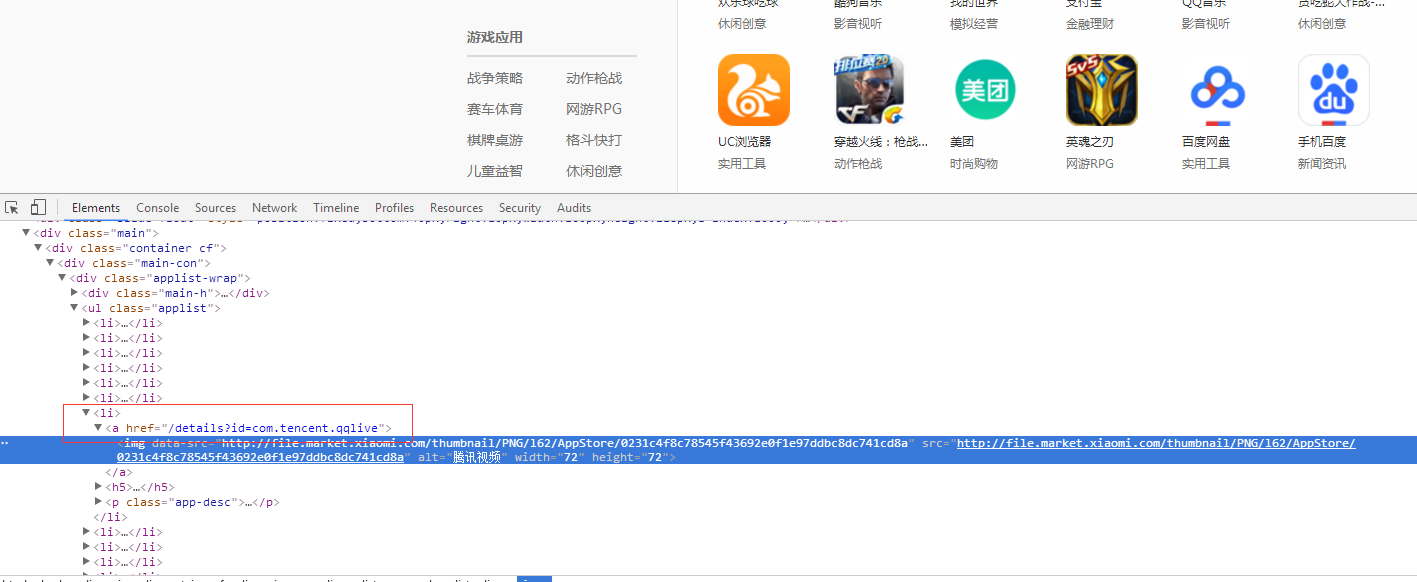
#coding=utf-8
import requests
import re
from bs4 import BeautifullSoup def parser_apks(self, count=0):
'''小米应用市场'''
_root_url="http://app.mi.com" #应用市场主页网址
res_parser={}
page_num=1 #设置爬取的页面,从第一页开始爬取,第一页爬完爬取第二页,以此类推
while count:
#获取排行榜页面的网页内容
wbdata = requests.get("http://app.mi.com/topList?page="+str(page_num)).text
print("开始爬取第"+str(page_num)+"页")
#解析页面内容获取 应用下载的 界面连接
soup=BeautifulSoup(wbdata,"html.parser")
links=soup.body.contents[3].find_all("a",href=re.compile("/details?"), class_ ="", alt="") #BeautifullSoup的具体用法请百度一下吧。。。
for link in links:
detail_link=urllib.parse.urljoin(_root_url, str(link["href"]))
package_name=detail_link.split("=")[1]
#在下载页面中获取 apk下载的地址
download_page=requests.get(detail_link).text
soup1=BeautifulSoup(download_page,"html.parser")
download_link=soup1.find(class_="download")["href"]
download_url=urllib.parse.urljoin(_root_url, str(download_link))
#解析后会有重复的结果,下面通过判断去重
if download_url not in res_parser.values():
res_parser[package_name]=download_url
count=count-1
if count==0:
break
if count >0:
page_num=page_num+1
print("爬取apk数量为: "+str(len(res_parser)))
return res_parser
def craw_apks(self, count=1, save_path="d:\\apk\\"):
res_dic=parser_apks(count) for apk in res_dic.keys():
print("正在下载应用: "+apk)
urllib.request.urlretrieve(res_dic[apk],save_path+apk+".apk")
print("下载完成")
if __name__=="__main__":
craw_apks(10)
运行结果:
开始爬取第1页
爬取apk数量为: 10
正在下载应用: com.tencent.tmgp.sgame
下载完成
.
.
.
以上就是简单爬虫的内容,其实爬虫的实现还是很复杂的,不同的网页有不同的解析方式,还需要深入学习。。。
Python 爬虫入门实例(爬取小米应用商店的top应用apk)的更多相关文章
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门(一)——爬取糗百
爬取糗百内容 GitHub 代码地址https://github.com/injetlee/Python/blob/master/qiubai_crawer.py 微信公众号:[智能制造专栏],欢迎关 ...
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- python爬虫+正则表达式实例爬取豆瓣Top250的图片
直接上全部代码 新手上路代码风格可能不太好 import requests import re from fake_useragent import UserAgent #### 用来伪造爬头部信息 ...
- Python爬虫入门:爬取pixiv
终于想开始爬自己想爬的网站了.于是就试着爬P站试试手. 我爬的图的目标网址是: http://www.pixiv.net/search.php?word=%E5%9B%9B%E6%9C%88%E3%8 ...
- python 爬虫入门1 爬取代理服务器网址
刚学,只会一点正则,还只能爬1页..以后还会加入测试 #coding:utf-8 import urllib import urllib2 import re #抓取代理服务器地址 Key = 1 u ...
随机推荐
- IDEA无法下载plugin的解决办法
有些时候我们在用IDEA安装plugins的时候,会因为各种原因搜索不到想要的依赖,或者搜索到却无法安装,针对这个问题,现在这里有两种方法可以尝试一下. 第一种: 找到settings->sys ...
- mysql用一个表更新另一个表的方法
Solution 1: 修改1列(navicate可行) update student s, city c set s.city_name = c.name where s.city_code = ...
- [maven] 实战笔记 - 构建、打包和安装maven
① 手工构建自己的maven项目 Maven 项目的核心是 pom.xml.POM (Project Object Model,项目对象模型)定义了项目的基本信息,用于描述项目如何构建,声明项目依赖等 ...
- 深入浅出 Java Concurrency (5): 原子操作 part 4 CAS操作
在JDK 5之前Java语言是靠synchronized关键字保证同步的,这会导致有锁(后面的章节还会谈到锁). 锁机制存在以下问题: (1)在多线程竞争下,加锁.释放锁会导致比较多的上下文切换和调度 ...
- probably another instance of uWSGI is running on the same address (127.0.0.1:9090). bind(): Address already in use
probably another instance of uWSGI is running on the same address (127.0.0.1:9090). bind(): Address ...
- excel拼接数据宏
将sheet2的A2 和 G2 加上 sheet5的A2和B2合一起生成新的sheet--就是将两个sheet的指定列前后拼接一起作为一个新的sheet Sub addwork() Sheets ...
- Spring Boot下Druid连接池的使用配置分析
https://blog.csdn.net/blueheart20/article/details/52384032
- the difference between fopen&open
[the difference between fopen&open] fopen是C标准API,open是linux系统调用,层次上fopen基于open,在其之上.fopen有缓存,ope ...
- shell中的字符串操作和数学运算
字符串操作 变量赋值: 说明:变量值可以用单引号.双引号.或者不加任何引号来赋值给变量 变量名="变量值" 变量名='变量值' 变量名=变量值 例如:str="hel ...
- json的例子
{ "Code": 200, "Msg": "", "Result": "{\"Platfor ...