初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据
通过requests、re(正则表达式) 爬取“古诗文”网页数据。
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/7/31 22:01
# 爬取古诗文网页数据
import re
import requests def getHtml(page):
'''
获取网页数据
:param page: 页数
:return: 网页html数据(文本格式)
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
url = 'https://www.gushiwen.org/default_{}.aspx'.format(page) # 获取几页数据
respons = requests.get(url,headers=headers)
html = respons.text
return html def getText(html):
titles = re.findall(r'<div class="cont">.*?<b>(.*?)</b>',html,re.DOTALL) # 获取标题 re.DOTALL 匹配所有字符,包含\n(.无法匹配\n)
caodai = re.findall(r'<p class="source">.*?<a.*?>(.*?)</a>',html,re.DOTALL) # 获取朝代
author = re.findall(r'<p class="source">.*?<a.*?>.*?<a.*?>(.*?)</a>',html,re.DOTALL) # 获取朝代
contents = re.findall(r'<div class="contson".*?>(.*?)</div>',html,re.DOTALL) # 获取内容,包含标签符号
con_texts =[] # 内容,不含标签符号
for i in contents:
rsub = re.sub('<.*?>','',i)
con_texts.append(rsub.strip()) # strip 去空格
si = []
for v in zip(titles,caodai,author,con_texts):
bt, cd, zz, nr = v
s = {
'标题':bt,
'朝代': cd,
'作者': zz,
'内容': nr
}
si.append(s)
return si def main():
p = int(input('您想要获取多少页的数据?\n'))
for page in range(1,p+1):
print('第{}页数据:'.format(page))
html = getHtml(page)
text = getText(html)
for i in text:
print(i) if __name__ == '__main__':
main()
爬取“古诗文”网页数据
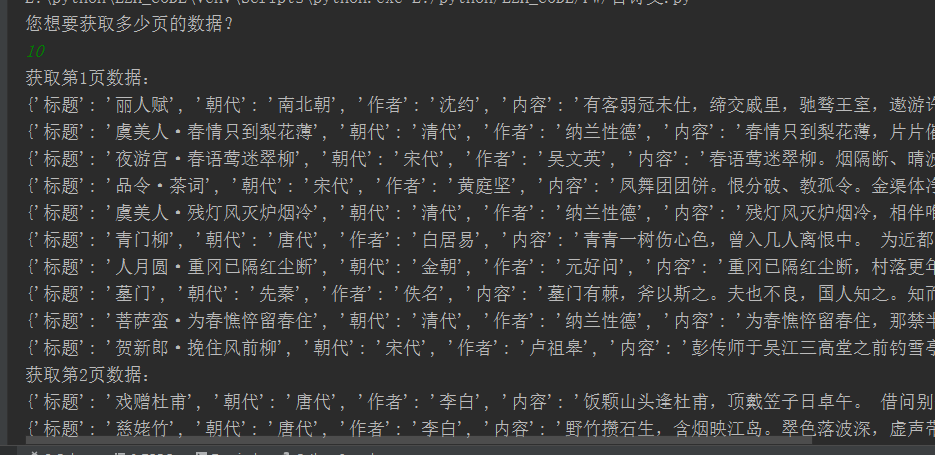
执行结果:

初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据的更多相关文章
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- 【Python网络爬虫三】 爬取网页新闻
学弟又一个自然语言处理的项目,需要在网上爬一些文章,然后进行分词,刚好牛客这周的是从一个html中找到正文,就实践了一下.写了一个爬门户网站新闻的程序 需求: 从门户网站爬取新闻,将新闻标题,作者,时 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- 精通python网络爬虫之自动爬取网页的爬虫 代码记录
items的编写 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
随机推荐
- cookie,sessionStorage,loclaStorage,HTML5应用程序缓存
cookie Cookie 是一些数据,由服务器生成,发送给浏览器,一旦用户从该网站或服务器退出,Cookie 就存储在用户本地的硬盘上,下一次请求同一网站时会把该cookie发送给服务器.Cooki ...
- BigDecimal 中 关于RoundingMode介绍
RoundingMode介绍 RoundingMode是一个枚举类,有以下几个常量:UP.DOWN.CEILING.FLOOR.HALF_UP.HALF_DOWN.HALF_EVEN.UNNECESS ...
- 商城项目的购物车模块的实现------通过session实现
1.新建购物车的实体类Cart public class Cart implements java.io.Serializable{ private Shangpin shangpin;//存放商品实 ...
- 【Matlab】线性调频信号LFM 仿真
[知识点] 生成序列 i = a:step:b 举例: i = 1:1:9 画图(子图) subplot(m,n,p)或者subplot(m n p) 总结起来就是,画一个m行n列的图. p表示在第p ...
- JavaOOP对象和封装
对象: 前言: 在程序员眼中,世界万物皆为对象.世界上有两种人,一种是懂二进制的人,一种就是不懂二进制的人. 面向对象设计的过程就是抽象的过程. 步骤: 第一步:发现类 第二步:发现类的属性 第三步: ...
- Mysql从头部署多个版本
目录 一.环境准备 二.下载安装包 三.Mysql-5.6单独部署 四.Mysql-5.7单独部署 五.添加到多版本控制 六.muliti使用 一.环境准备 系统:centos7.3一台 软件版本:m ...
- for循环中的变量泄漏
经典的案例 let arr = [] for(var i =0;i<=5;i++){ arr[i]= function fn(){ console.log(i) } } arr[0]() //6 ...
- [BUUCTF]PWN3——warmup_csaw_2016
[BUUCTF]PWN3--warmup_csaw_2016 题目网址:https://buuoj.cn/challenges#warmup_csaw_2016 步骤: 例行检查,64位,没有开启任何 ...
- 分组依据(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 [视图]选项卡下,[筛选器]楼下,住着个[分组依据]. 这个功能,说白了,就是指定个"组",把同一组的 ...
- wordpress的.htaccess很容易就被挂马啊
wordpress的.htaccess很容易就被挂马啊 修改成这样吧: # BEGIN WordPress<IfModule mod_rewrite.c>RewriteEngine OnR ...