初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据
通过requests、re(正则表达式) 爬取“古诗文”网页数据。
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/7/31 22:01
# 爬取古诗文网页数据
import re
import requests def getHtml(page):
'''
获取网页数据
:param page: 页数
:return: 网页html数据(文本格式)
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
url = 'https://www.gushiwen.org/default_{}.aspx'.format(page) # 获取几页数据
respons = requests.get(url,headers=headers)
html = respons.text
return html def getText(html):
titles = re.findall(r'<div class="cont">.*?<b>(.*?)</b>',html,re.DOTALL) # 获取标题 re.DOTALL 匹配所有字符,包含\n(.无法匹配\n)
caodai = re.findall(r'<p class="source">.*?<a.*?>(.*?)</a>',html,re.DOTALL) # 获取朝代
author = re.findall(r'<p class="source">.*?<a.*?>.*?<a.*?>(.*?)</a>',html,re.DOTALL) # 获取朝代
contents = re.findall(r'<div class="contson".*?>(.*?)</div>',html,re.DOTALL) # 获取内容,包含标签符号
con_texts =[] # 内容,不含标签符号
for i in contents:
rsub = re.sub('<.*?>','',i)
con_texts.append(rsub.strip()) # strip 去空格
si = []
for v in zip(titles,caodai,author,con_texts):
bt, cd, zz, nr = v
s = {
'标题':bt,
'朝代': cd,
'作者': zz,
'内容': nr
}
si.append(s)
return si def main():
p = int(input('您想要获取多少页的数据?\n'))
for page in range(1,p+1):
print('第{}页数据:'.format(page))
html = getHtml(page)
text = getText(html)
for i in text:
print(i) if __name__ == '__main__':
main()
爬取“古诗文”网页数据
执行结果:
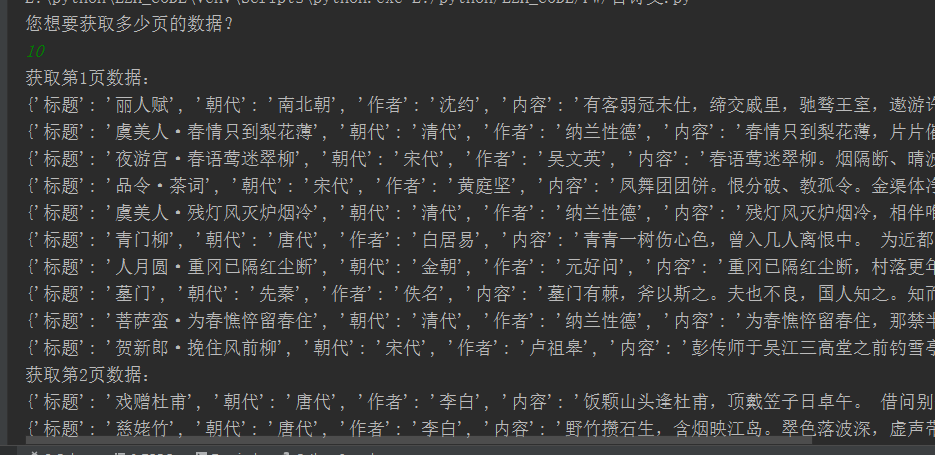

初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据的更多相关文章
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- 【Python网络爬虫三】 爬取网页新闻
学弟又一个自然语言处理的项目,需要在网上爬一些文章,然后进行分词,刚好牛客这周的是从一个html中找到正文,就实践了一下.写了一个爬门户网站新闻的程序 需求: 从门户网站爬取新闻,将新闻标题,作者,时 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- 精通python网络爬虫之自动爬取网页的爬虫 代码记录
items的编写 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
随机推荐
- Spring Boot中使用Servlet与Filter
在Spring Boot中使用Servlet,根据Servlet注册方式的不同,有两种使用方式.若使用的是Servlet3.0+版本,则两种方式均可使用:若使用的是Servlet2.5版本,则只能使用 ...
- Java-如何合理的设置线程池大小
想要合理配置线程池线程数的大小,需要分析任务的类型,任务类型不同,线程池大小配置也不同. 配置线程池的大小可根据以下几个维度进行分析来配置合理的线程数: 任务性质可分为:CPU密集型任务,IO密集型任 ...
- FindUserByPageServlet
package com.hopetesting.web.servlet;import com.hopetesting.domain.PageBean;import com.hopetesting.do ...
- 解决在进行socket通信时,一端输出流OutputStream不关闭,另一端输入流就接收不到数据
输出的数据需要达到一定的量才会向另一端输出,所以在传输数据的末端添加 \r\n 可以保证不管数据量是多少,都立刻传输到另一端.
- 『与善仁』Appium基础 — 21、元素的基本操作
目录 1.元素的基本操作说明 (1)点击操作 (2)清空操作 (3)输入操作 2.综合练习 1.元素的基本操作说明 (1)点击操作 点击操作:click()方法.(同Selenium中使用方式一致) ...
- react功能实现-组件创建
这里主要从两个角度来分析创建一个组件需要怎么做,一个是元素,一个是数据.整理向,大量借鉴,非原创. 1.渲染组件. 我们先明确一点,所有的元素都必须通过render方法来输出渲染.所有,每个组件类最终 ...
- Sentry 开发者贡献指南 - 后端服务(Python/Go/Rust/NodeJS)
内容整理自官方开发文档 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Map ...
- AtCoder Beginner Contest 148 题解
目录 AtCoder Beginner Contest 148 题解 前言 A - Round One 题意 做法 程序 B - Strings with the Same Length 题意 做法 ...
- JDK安装错误问题总结。
Windows10安装JDK,测试java -version时出现could not open XXX\jvm.cfg的解决方法. 1. 切记,环境变量修改后重新测试时一定要关闭命令再重新打开才生效 ...
- CF60A Where Are My Flakes? 题解
Content 有人发现他的麦片不见了,原来是室友把它藏在了 \(n\) 个盒子中的一个,另外还有 \(m\) 个提示,有两种: \(\texttt{To the left of }x\):麦片在第 ...