Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名、图片链接、名称、主演、上映时间。
思路:1.定义一个获取网页源代码的函数;
2.定义一个解析网页源代码的函数;
3.定义一个将解析的数据保存为本地文件的函数;
4.定义主函数;
5.使用多进程爬取。
步骤一:首先,导入相关的库:
import requests
import re
import json
from multiprocessing import Pool
from requests.exceptions import RequestException
步骤二:定义获取网页源代码的函数,这里使用 requests.get() 方法来获取,并调用异常处理方法:
def get_one_page(url):
response = requests.get(url)
try:
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
步骤三:定义一个函数,利用正则表达式 re.findall() 等函数解析网页源代码,并利用 yield 生成器对解析的代码进行排布,转换为字典形式:
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?">(\d+)</i>.*?data-src="(.*?)".*?</a>.*?'
+ '<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'排名': item[0],
'图片': item[1],
'名称': item[2],
'主演': item[3].strip()[3:],
'上映时间': item[4].strip()[5:]
}
步骤四:定义主函数,爬取最受期待榜的 n 页:
def main(offset):
url = 'https://maoyan.com/board/6?offset=' +str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_one_page(item)
步骤五:多进程爬取,定义进程池,并调用 Pool.map() 方法进行多进程爬取,提高爬取效率:
if __name__ == "__main__":
pool = Pool()
pool.map(main, [i*10 for i in range(10)])
爬取的部分数据如下:
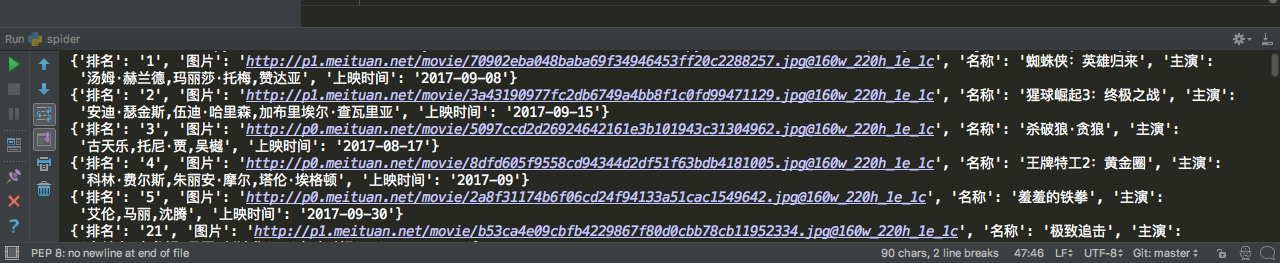
Python 爬取猫眼电影最受期待榜的更多相关文章
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 爬虫实战【4】Python获取猫眼电影最受期待榜的50部电影
前面几天介绍的都是博客园的内容,今天我们切换一下,了解一下大家都感兴趣的信息,比如最近有啥电影是万众期待的? 猫眼电影是了解这些信息的好地方,在猫眼电影中有5个榜单,其中最受期待榜就是我们今天要爬取的 ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- Python爬取猫眼电影《飞驰人生》47858万条评论并对其进行数据分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Yura不说数据说 ,PYuraL PS:如有需要Python学习资 ...
- Python 爬取猫眼电影《无名之辈》并对其进行数据分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接 ...
- Python爬取猫眼电影排行
import requests import pyquery def crawl_page(url: str) -> None: headers = { 'user-agent': 'Mozil ...
随机推荐
- 【MySql系列】MySql踩坑系列
问题一:远程登录报错Host '192.168.181.201' is not allowed to connect to this MySQL server 解决: 问题二:MySql access ...
- alpha-咸鱼冲刺day7(后续一波)-紫仪
总汇链接 一,合照 emmmmm.自然还是没有的. 二,项目燃尽图 三,项目进展 正在写登陆+注册ing 注册搞出来了!!!!!!!!QAQ(喜极而泣!!!!.jpg) 四,问题困难 数据流程大概是搞 ...
- C语言--第六周作业
一.高速公路超速罚款 1.代码 #include<stdio.h> int main() { int a,b; float c; scanf("%d %d",& ...
- 转 Eclipse快捷键调试大全
(1)Ctrl+M --切换窗口的大小(2)Ctrl+Q --跳到最后一次的编辑处(3)F2 ---重命名类名 工程名 --当鼠标放在一个标记处出现Tooltip时候按F2则把鼠标移开时To ...
- java实现同步的两种方式
同步是多线程中的重要概念.同步的使用可以保证在多线程运行的环境中,程序不会产生设计之外的错误结果.同步的实现方式有两种,同步方法和同步块,这两种方式都要用到synchronized关键字. 给一个方法 ...
- io多路复用(一)
sever端 1 import socket sk1 = socket.socket() sk1.bind(('127.0.0.1',8001,)) sk1.listen() sk2 = socket ...
- 201421123042 《Java程序设计》第8周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图或其他)归纳总结集合相关内容. 2. 书面作业 1. ArrayList代码分析 1.1 解释ArrayList的contains源代码 源代码: 答:查找 ...
- 原生ajax的请求函数
ajax:一种请求数据的方式,不需要刷新整个页面:ajax的技术核心是 XMLHttpRequest 对象:ajax 请求过程:创建 XMLHttpRequest 对象.连接服务器.发送请求.接收响应 ...
- 前端面试之angular JS
1. angular的数据绑定采用什么机制?详述原理 angularjs的双向数据绑定,采用脏检查(dirty-checking)机制.ng只有在指定事件触发后,才进入 $digest cycle : ...
- D的下L
D的小L 时间限制:4000 ms | 内存限制:65535 KB 难度:2 描述 一天TC的匡匡找ACM的小L玩三国杀,但是这会小L忙着哩,不想和匡匡玩但又怕匡匡生气,这时小L给 ...