解决百度BMR的spark集群开启slaves结点的问题
前言
最近一直忙于和小伙伴倒腾着关于人工智能的比赛,一直都没有时间停下来更新更新我的博客。不过在这一个过程中,遇到了一些问题,我还是记录了下来,等到现在比较空闲了,于是一一整理出来写成博客。希望对于大家有帮助,如果在此有不对的地方,请大家指正,谢谢!
比赛遇到spark开启的问题
疑惑之处
在使用百度BMR的时候,出现了这样子一个比较困惑的地方。但百度那边帮我们初始化了集群之后,我们默认以为开启了spark集群了,于是就想也不想就开始跑我们的代码。可认真你就错了,发现它只是开启了local(即Master结点),其他的slaves结点并没有开启。于是我们不得不每一次都进入到Master的/opt/bmr/spark/conf/中去修改slaves文件,去把它里面最后的那个localhost删除,添加上slaves结点的hostname或者是IP。
原来的localhost:

改变成如下:

麻烦之处
最是麻烦的地方是,这个slaves文件,每次使用spark集群的时候都要去修改,非常不方便。在此吐槽一下百度BMR的不智能的地方。于是想,有木有好的办法可以让我们省去这样的麻烦呢?
使用脚本开启百度BMR的spark集群
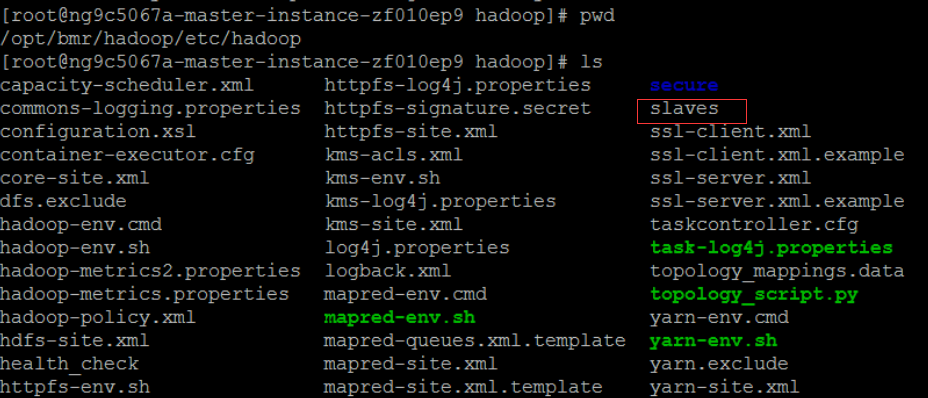
观察Hadoop文件夹下的情况
在开启集群的时候,百度提供我们选择Hadoop的镜像版本,而这个Hadoop是必选的。前几篇博文里见到配置Hadoop的时候其实需要配置其他slaves的结点的。知道这个,就有点惊喜了,因为Hadoop下的slaves文件是长这样子的

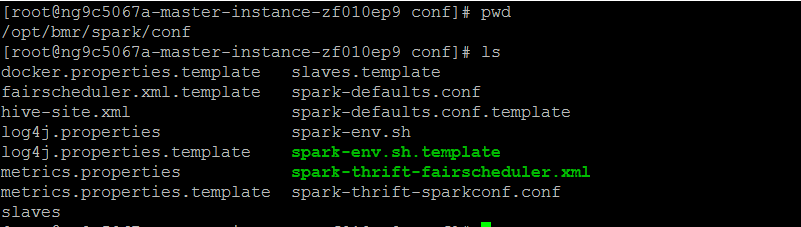
观察spark文件夹下的情况
spark下的conf文件夹,一开始并没有slaves,我们需要从它的slaves.template拷贝过来
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
使用脚本,拷贝slaves的hostname到spark下的slaves
我们需要做的是,获取Hadoop下slaves的slaves结点的hostname,进而拷贝到spark下的slaves文件的最后两行,拷贝之前,需要把spark的slaves的最后一行localhost给删除掉。那么有哪个shell指令可以帮我解决这个难题了?经过询问后台的大佬,以及晚上查阅,发现了sed这个指令可以帮助我们解决这个问题。
sed的介绍
取自http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856901.html
[root@www ~]# sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
使用sed写脚本
具体用到的有:
-i #因为信息我觉得不用输出到终端上
d #需要删除localhost
这是删除localhost的:
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves
追加slaves的hostname到spark的slaves最后
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done
最后spark下的slaves文件是这样子的

完整的代码如下
echo "Starting dfs!"
/opt/bmr/hadoop/sbin/start-dfs.sh
echo "*******************************************************************"
echo "Starting copy!"
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
echo "Copy finished!"
echo "Writing!"
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done
echo "*******************************************************************"
echo "Starting spark!"
/opt/bmr/spark/sbin/start-all.sh
echo "*******************************************************************"
echo "Watching the threads"
jps
查看到Master进程已经开启了,就大功告成了!
结言
只要把上面的代码保存到一个.shell文件下。给它加上可运行的权限,然后就大功告成了。理论上,百度BMR的spark的路径都是一致的,因而都能通用,希望能减轻大家每次配置的烦恼。
文章出自kwongtai'blog,转载请标明出处!
解决百度BMR的spark集群开启slaves结点的问题的更多相关文章
- 使用fabric解决百度BMR的spark集群各节点的部署问题
前言 和小伙伴的一起参加的人工智能比赛进入了决赛之后的一段时间里面,一直在构思将数据预处理过程和深度学习这个阶段合并起来.然而在合并这两部分代码的时候,遇到了一些问题,为此还特意写了脚本文件进行处理. ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- 解决Spark集群无法停止
执行stop-all.sh时,出现报错:no org.apache.spark.deploy.master.Master to stop,no org.apache.spark.deploy.work ...
- Spark集群无法停止的原因分析和解决
今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止.提示: no org.apache.spark.deploy.master.Master to stop ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
随机推荐
- 《物联网框架ServerSuperIO教程》-22.Web端对传感器实时监测与控制。附:v3.6.8版本,支持WebSocket
1.ServerSuperIO v3.6.8更新内容 1.1 增加WebSocket服务端功能,支持自控模式.并发模式.单例模式,不支持轮询模式1.2 接收数据缓存与现有的IO实例分离.1.3 优化代 ...
- Perl根据日期分割数据文件
Perl的优势:比C好写,比Shell高效,Linux普遍支持. #!/usr/bin/perl -w # auth: lichmama@cnblogs.com # what: split data_ ...
- JQuery EasyUI的常用组件
jQuery EasyUI 是一个基于 jQuery 的框架,集成了各种用户界面插件,该框架提供了创建网页所需的一切,帮助您轻松建立站点. 注:本次介绍的JQuery EasyUI版本为1.5版. 一 ...
- windows平台python 2.7环境编译安装zbar
最近一个项目需要识别二维码,找来找去找到了zbar和zxing,中间越过无数坑,总算基本上弄明白,分享出来给大家. 一.zbar官方介绍 ZBar 是款桌面电脑用条形码/二维码扫描工具,支持摄像头及图 ...
- FineReport中如何对cpt模板加密
1. 描述 FR客户使用FineReport报表并将其集成到自己的产品中,然后提供给最终用户使用,最终用户可以预览FR模板,但是不能打开模板进行设计修改. FineReport提供了cpt模板Des加 ...
- (转发)RequestDispatcher的include()方法和forward()方法的区别
forward(): 该方法用于将请求从一个Servlet传递给服务器上的另外的Servlet.JSP页面或者是HTML文件. 在Servlet中,可以对请求做一个初步的处理,然后调用这个方法,将请求 ...
- requireJS 源码(三) data-main 的加载实现
(一)入口 通过 data-main 去加载 JS 模块,是通过 req(cfg) 入口去进行处理的. 为了跟踪,你可以在此 加断点 进行调试跟踪. (二) req({ })执行时,functio ...
- Go语言学习笔记(三)数组 & 切片 & map
加 Golang学习 QQ群共同学习进步成家立业工作 ^-^ 群号:96933959 数组 Arrays 数组是同一种数据类型的固定长度的序列. 数组是值类型,因此改变副本的值,不会改变本身的值: 当 ...
- 1,入门-Hello Soring Boot
什么是SpringBoot Spring Boot是Spring社区发布的一个开源项目,旨在帮助开发者快速并且更简单的构建项目.大多数SpringBoot项目只需要很少的配置文件. SpringBoo ...
- Oozie时出现Exception in thread "main" java.lang.UnsupportedClassVersionError: com/mysql/jdbc/Driver : Unsupported major.minor version 52.0?
不多说,直接上干货! 问题详情 [hadoop@bigdatamaster oozie--cdh5.5.4]$ bin/ooziedb.sh create -sqlfile oozie.sql -ru ...