K近邻(K Nearest Neighbor-KNN)原理讲解及实现
算法原理
K最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样本中的大多数都属于某一个类别,则该样本也属于这个类别。第一个字母k可以小写,表示外部定义的近邻数量。
举例说明
首先我们准备一个数据集,这个数据集很简单,是由二维空间上的4个点构成的一个矩阵,如表1所示:
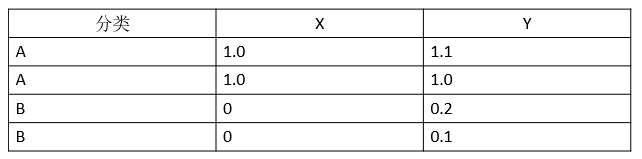
表1:训练集
其中前两个点构成一个类别A,后两个点构成一个类别B。我们用Python把这4个点在坐标系中绘制出来,如图1所示:

图1:训练集绘制
绘制所用的代码如下:
# -*- encoding:utf-8-* -
from numpy import *
import matplotlib.pyplot as plt def createDataSet():
dataSet = array([[1.0, 1.1], [1.0, 1.0], [0, 0.2], [0, 0.1]]) # 数据集
labels = ['A', 'A', 'B', 'B'] # 数据集对应的类别标签
return dataSet, labels dataSet, labels = createDataSet()
# 显示数据集信息
fig = plt.figure()
ax = fig.add_subplot(111)
indx = 0
for point in dataSet:
if labels[indx] == 'A':
ax.scatter(point[0], point[1], c='blue', marker='o', linewidths=0, s=300)
plt.annotate("("+str(point[0])+","+str(point[1])+")", xy=(point[0], point[1]))
else:
ax.scatter(point[0], point[1], c='red', marker='^', linewidths=0, s=300)
plt.annotate("("+str(point[0])+","+str(point[1])+")", xy=(point[0], point[1]))
indx += 1
plt.show()
从图形中可以清晰地看到由4个点构成的训练集。该训练集被分为两个类别:A类——蓝色圆圈,B类——红色三角形。因为红色区域内的点距比它们到蓝色区域内的点距要小的多,这种分类也很自然。
下面我们给出测试集,只有一个点,我们把它加入到刚才的矩阵中去,如表2所示:

表2:加入了一个训练样本
我们想知道给出的这个测试集应该属于哪个分类,最简单的方法还是画图,我们把新加入的点加入图中,图2很清晰,从距离上看,它更接近红色三角形的范围,应该归于B类,这就是KNN算法的基本原理。
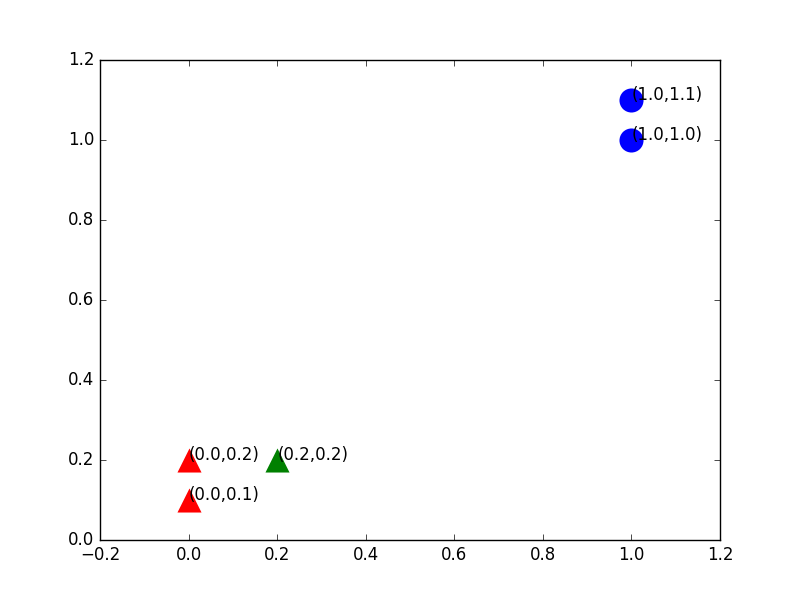
图2:加入一个训练样本后绘制
在上述代码的基础上,绘制测试样本点的代码如下:
# 显示即将需要测试的数据信息
testdata = [0.2, 0.2]
ax.scatter(testdata[0], testdata[1], c='green', marker='^', linewidths=0, s=300)
plt.annotate("(" + str(testdata[0]) + "," + str(testdata[1]) + ")", xy=(testdata[0], testdata[1]))
plt.show()
算法实现
综上所述,KNN算法应由以下步骤构成。
第一阶段:确定k值(就是指最近邻居的个数)。一般是一个奇数,因为测试样本有限,故取值为3。
第二阶段:确定距离度量公式。文本分类一般使用夹角余弦,得出待分类数据点和所有已知类别的样本点,从中选择距离最近的k个样本。
夹角余弦:
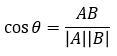
第三阶段:统计这k个样本点中各个类别的数量。上例中我们选定k值为3,则B类样本(三角形)有2个,A类样本(圆形)有 1个,那么我们就把这个方形数据点定位B类;即,根据k个样本中数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
实现代码如下:
from numpy import *
import operator # 产生数据集
def createDataSet():
dataSet = array([[1.0, 1.1], [1.0, 1.0], [0, 0.2], [0, 0.1]]) # 数据集
labels = ['A', 'A', 'B', 'B'] # 数据集对应的类别标签
return dataSet, labels # 夹角余弦距离公式
def cosdist(vector1, vector2):
return dot(vector1, vector2) / (linalg.norm(vector1) * linalg.norm(vector2)) # KNN 分类器
# 测试集:testdata; 训练集:trainSet;类别标签:listClasses;k: k个邻居数
def classify(testdata, trainSet, listClasses, k):
dataSetSize = trainSet.shape[0] # 返回样本集的行数
distances = array(zeros(dataSetSize))
for indx in xrange(dataSetSize): # 计算测试集与训练集之间的距离:夹角余弦
distances[indx] = cosdist(testdata, trainSet[indx])
# 根据生成的夹角余弦按从小到大排序,结果为索引号
sortedDistIndicies = argsort(distances)
classCount = {}
for i in range(k):
# 按排序顺序返回样本集对应的类别标签
voteIlabel = listClasses[sortedDistIndicies[i]]
# 为字典classCount赋值,相同的key,value加1
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# sorted():按字典值进行排序,返回list
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] # dataSet:测试数据集
# labels:测试数据集对应的标签
dataSet, labels = createDataSet()
testdata = [0.2, 0.2]
k = 3 # 选取最近的K个样本进行类别判定
# 判定testdata类别,输出类别结果
print "label is: " + classify(testdata, dataSet, labels, k)
输出:“label is: B“
K近邻(K Nearest Neighbor-KNN)原理讲解及实现的更多相关文章
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- 机器学习分类算法之K近邻(K-Nearest Neighbor)
一.概念 KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确.而且KN ...
- 《机实战》第2章 K近邻算法实战(KNN)
1.准备:使用Python导入数据 1.创建kNN.py文件,并在其中增加下面的代码: from numpy import * #导入科学计算包 import operator #运算符模块,k近邻算 ...
- k 近邻算法(k-Nearest Neighbor,简称kNN)
预约助教问题: 1.计算1-NN,k-nn和linear regression这三个算法训练和查询的时间复杂度和空间复杂度? 一. WHy 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- 统计学习三:1.k近邻法
全文引用自<统计学习方法>(李航) K近邻算法(k-nearest neighbor, KNN) 是一种非常简单直观的基本分类和回归方法,于1968年由Cover和Hart提出.在本文中, ...
随机推荐
- C++学习(十一)(C语言部分)之 练习
/* 1.if 输入一个成绩 进行分级 输入一个数字 判断是否是水仙花数 比如 153 = 1 * 1 * 1 + 5 * 5 * 5 + 3 * 3 * 3 2.switch 提示 先对数字做处理 ...
- 非系统服务如何随系统启动时自动启动(rc.local加了可执行权限,仍然没有生效)
我们知道,例如我们直接yum 安装的httpd mysqld之类的服务可以直接systemctl enable mysql使服务自动启动,但是,我们应该关心的是但是的那部分 例如nginx,我的话,我 ...
- <------------------字节流--------------------->
字节流: 输入和输出:1.参照物都是java程序来惨遭 2.Input输入,持久化上的数据---->内存 3.Output输出,内存--->硬盘 字节输出流: OutputStream: ...
- gcc的编译属性和选项
1.指定内存默认对其参数: __attribute__((packed)):按一字节对其__attribute__((aligned(n))):从此之后默认按n字节对其 例如: struct stu ...
- 如何安装Visio
- VIM命令操作
退出命令 :wq 保存并退出 ZZ 保存并退出 :q! 强制退出并忽略所有更改 :e! 放弃所有修改,并打开原来文件.
- Java 8后的首个长期支持版本Java 11
Java 11是Java8后的首个长期支持版本.按照 Oracle 公布的支持路线图,Java 11 将会获得 Oracle 提供的长期支持服务,直至2026年9月. 按照官方的说法,新的发布周期会严 ...
- TypeScript 之 声明文件的发布
https://www.tslang.cn/docs/handbook/declaration-files/publishing.html 发布声明文件到npm,有两种方式: 与你的npm包捆绑在一起 ...
- C# 使用委托实现多线程调用窗体的四种方式(转)
1.方法一:使用线程 功能描述:在用c#做WinFrom开发的过程中.我们经常需要用到进度条(ProgressBar)用于显示进度信息.这时候我们可能就需要用到多线程,如果不采用多线程控制进度条,窗口 ...
- SQL Server 2005无法远程连接的解决方法 (转帖)
方法如下: 一.为 SQL Server 2005 启用远程连接1. 单击"开始",依次选择"程序"."Microsoft SQL Server 2 ...