近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数。求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的。
考虑一个这样的问题:
minx f(x)+λg(x)
x∈Rn,f(x)∈R,这里f(x)是一个二阶可微的凸函数,g(x)是一个凸函数(或许不可导),如上面L1的正则化||x||。
此时,只需要f(x)满足利普希茨(Lipschitz)连续条件,即对于定义域内所有向量x,y,存在常数M使得||f'(y)-f'(x)||<=M·||y-x||,那么这个模型就可以通过近端梯度算法来进行求解了。
ps:下面涉及很多数学知识,不想了解数学的朋友请跳到结论处,个人理解,所以也不能保证推理很严谨,如有问题,请一定帮忙我告诉我。
利普希茨连续条件的几何意义可以认为是函数在定义域内任何点的梯度都不超过M(梯度有上限),也就是说不会存在梯度为正负无穷大的情况。
因而,我们有下图所示的推算:
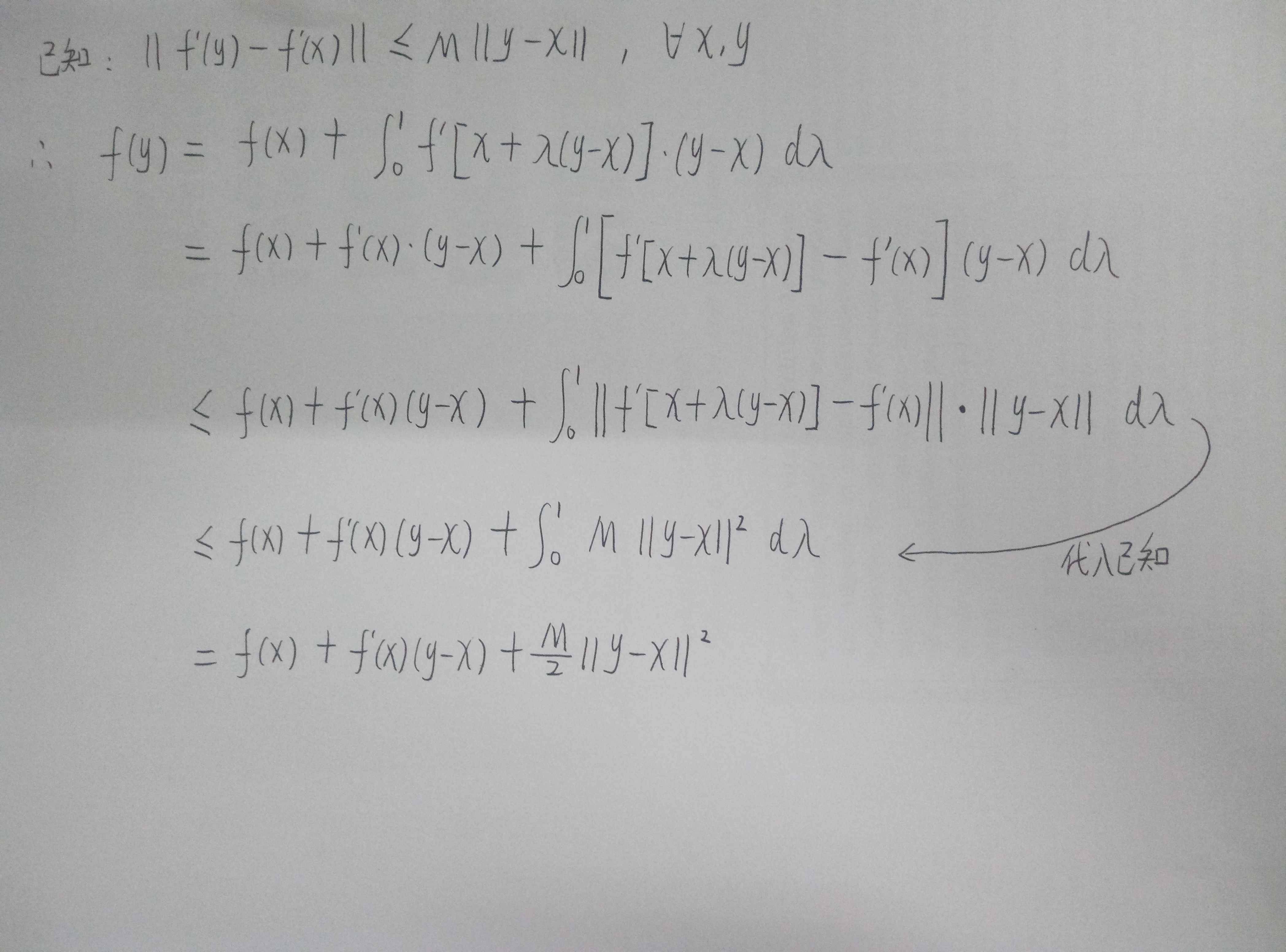
我们可以用f(y) = f(x)+f'(x)(y-x)+M/2*||y-x||2来近似的表示f(y),也可以认为是高维下的泰勒分解,取到二次项。
我们换一种写法,f(xk+1) = f(xk)+f'(xk)(xk+1-xk)+M/2*||xk+1-xk||2,也就是说可以直接迭代求minx f(x),就是牛顿法辣。
再换一种写法,f(xk+1)=(M/2)(xk+1-(xk+(1/M)f'(xk)))2+CONST,其中CONST是一个与xk+1无关的常数,也就是说,此时我们可以直接写出这个条件下xk+1的最优取值就是xk+1=xk+(1/M)f'(xk)。令z=xk+(1/M)f'(xk)。
回到原问题,minx f(x)+λg(x),此时问题变为了求解minx (M/2)||x-z||2+λg(x)。
实际上在求解这个问题的过程中,x的每一个维度上的值是互不影响的,可以看成n个独立的一维优化问题进行求解,最后组合成一个向量就行。
如果g(x)=||x||1,就是L1正则化,那么最后的结论可以通过收缩算子来表示。
即xk+1=shrink(z,λ/M)。具体来说,就是Z向量的每一个维度向原点方向移动λ/M的距离(收缩,很形象),对于xk+1的第i个维度xi=sgn(zi)*max(|zi|-λ/M,0),其中sgn()为符号函数,正数为1,负数为-1。
一直迭代直到xk收敛吧。
参考文献:
[1]Nesterov Y. Introductory lectures on convex optimization: A basic course[M]. Springer Science & Business Media, 2013.
[2]https://people.eecs.berkeley.edu/~elghaoui/Teaching/EE227A/lecture18.pdf
近端梯度算法(Proximal Gradient Descent)的更多相关文章
- Proximal Gradient Descent for L1 Regularization(近端梯度下降求解L1正则化问题)
假设我们要求解以下的最小化问题: $min_xf(x)$ 如果$f(x)$可导,那么一个简单的方法是使用Gradient Descent (GD)方法,也即使用以下的式子进行迭代求解: $x_{k+1 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- 梯度下降(Gradient Descent)
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)相关概念
梯度,直观理解: 梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中, 梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过 ...
- One-hot 编码/TF-IDF 值来提取特征,LAD/梯度下降法(Gradient Descent),Sigmoid
1. 多值无序类数据的特征提取: 多值无序类问题(One-hot 编码)把“耐克”编码为[0,1,0],其中“1”代表了“耐克”的中 间位置,而且是唯一标识.同理我们可以把“中国”标识为[1,0],把 ...
- [机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自网上的免费课程和一些经典书籍,免费课 ...
- ML:梯度下降(Gradient Descent)
现在我们有了假设函数和评价假设准确性的方法,现在我们需要确定假设函数中的参数了,这就是梯度下降(gradient descent)的用武之地. 梯度下降算法 不断重复以下步骤,直到收敛(repeat ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
随机推荐
- Objective-C 禁用NSMenu中的系统services菜单项
当用NSMenu创建一个右键菜单时,mac系统会默认插入一些服务(services)菜单项,如下图,xlsx文件的右键菜单中,除了自定义的菜单项:“转发”和“收藏”等等,还有“在 Finder中显示简 ...
- Android 底部菜单会被顶起来的情况
描述:主界面有一排底部菜单,当从主界面跳转到另一个界面,假如说这个界面有软键盘弹出,主界面的顶部菜单会被顶起来. 原因:系统软键盘造成的 解决办法:在返回主界面时将系统软键盘关掉即可
- TCP/IP协议---UDP协议
UDP是一个简单的面向数据报的运输层协议:进程的每个输出操作都产生一个UDP数据报,并组装成一份待发送的IP数据报.UDP数据报是要依赖IP数据报传送的.UDP协议并不可靠,它不能保证发出去的包会被目 ...
- Luogu2839 Middle 主席树、二分答案
题目传送门:https://www.luogu.org/problemnew/show/P2839 题目大意:给出一个长度为$N$的序列与$Q$次询问,每次询问左端点在$[a,b]$,右端点在$[c, ...
- DIV实现水平或垂直滚动条
添加样式: 在html中,需要创建2层div来实现.一个div包含另一个div: 效果:
- Luogu P4427 [BJOI2018]求和
这是一道巨狗题,我已无力吐槽为什么我怎么写都不过 我们对于这种无修改的边权题目有一个经典的树上差分套路: \(ans=sum_x+sum_y-2\cdot sum_{LCA(x,y)}\) 这里的\( ...
- 给 MSYS2 添加中科大的源
最近一段时间不知怎么的,使用默认的 MSYS2 源升级软件或是安装新软件的特别的慢.所以就翻了翻国内的几个开源软件的镜像库,发现中科大的库里就有 MSYS2.所以就研究了一下,给 MSYS2 添加了中 ...
- linux监控文件夹内的文件数量
开发的时候遇到一个问题,服务器一旦重启,项目生成的文件就丢失了,感觉很莫名其妙..一开始猜测是文件流没有关闭,检查了代码,感觉没毛病.于是先看看是关机丢失了文件还是开机被删除了.下面的脚本每秒执行一次 ...
- Jq_DOM元素方法跟JQuery 核心函数跟JQuery 事件方法
JQuery DOM 元素 函数 描述 .get() 从队列中删除所有未运行的项目. .ind ...
- db2修改最大连接数
查看当前连接数,sample为数据库名db2 list applications for db sample db2 list applications for db sample show deta ...