近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数。求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的。
考虑一个这样的问题:
minx f(x)+λg(x)
x∈Rn,f(x)∈R,这里f(x)是一个二阶可微的凸函数,g(x)是一个凸函数(或许不可导),如上面L1的正则化||x||。
此时,只需要f(x)满足利普希茨(Lipschitz)连续条件,即对于定义域内所有向量x,y,存在常数M使得||f'(y)-f'(x)||<=M·||y-x||,那么这个模型就可以通过近端梯度算法来进行求解了。
ps:下面涉及很多数学知识,不想了解数学的朋友请跳到结论处,个人理解,所以也不能保证推理很严谨,如有问题,请一定帮忙我告诉我。
利普希茨连续条件的几何意义可以认为是函数在定义域内任何点的梯度都不超过M(梯度有上限),也就是说不会存在梯度为正负无穷大的情况。
因而,我们有下图所示的推算:
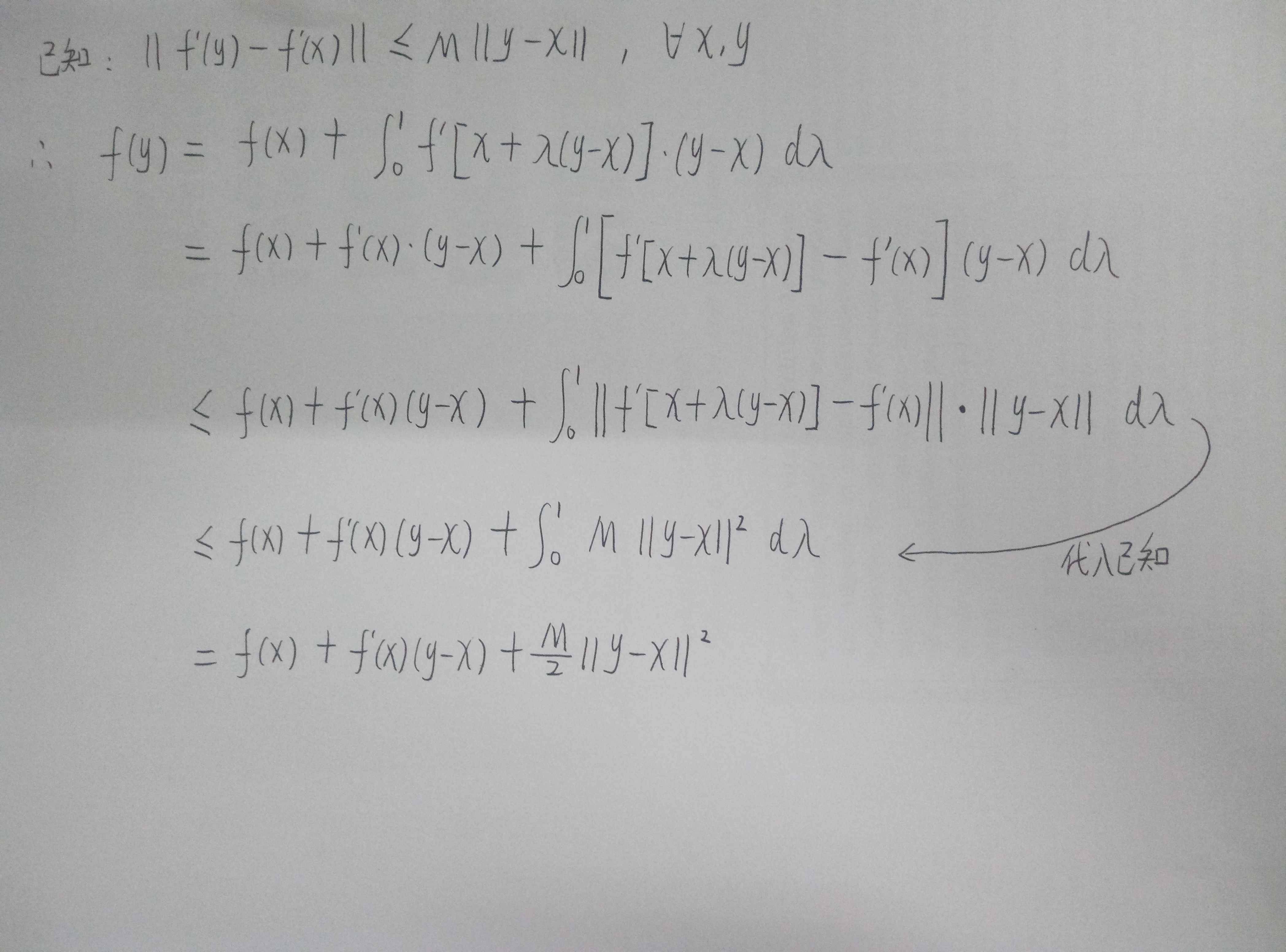
我们可以用f(y) = f(x)+f'(x)(y-x)+M/2*||y-x||2来近似的表示f(y),也可以认为是高维下的泰勒分解,取到二次项。
我们换一种写法,f(xk+1) = f(xk)+f'(xk)(xk+1-xk)+M/2*||xk+1-xk||2,也就是说可以直接迭代求minx f(x),就是牛顿法辣。
再换一种写法,f(xk+1)=(M/2)(xk+1-(xk+(1/M)f'(xk)))2+CONST,其中CONST是一个与xk+1无关的常数,也就是说,此时我们可以直接写出这个条件下xk+1的最优取值就是xk+1=xk+(1/M)f'(xk)。令z=xk+(1/M)f'(xk)。
回到原问题,minx f(x)+λg(x),此时问题变为了求解minx (M/2)||x-z||2+λg(x)。
实际上在求解这个问题的过程中,x的每一个维度上的值是互不影响的,可以看成n个独立的一维优化问题进行求解,最后组合成一个向量就行。
如果g(x)=||x||1,就是L1正则化,那么最后的结论可以通过收缩算子来表示。
即xk+1=shrink(z,λ/M)。具体来说,就是Z向量的每一个维度向原点方向移动λ/M的距离(收缩,很形象),对于xk+1的第i个维度xi=sgn(zi)*max(|zi|-λ/M,0),其中sgn()为符号函数,正数为1,负数为-1。
一直迭代直到xk收敛吧。
参考文献:
[1]Nesterov Y. Introductory lectures on convex optimization: A basic course[M]. Springer Science & Business Media, 2013.
[2]https://people.eecs.berkeley.edu/~elghaoui/Teaching/EE227A/lecture18.pdf
近端梯度算法(Proximal Gradient Descent)的更多相关文章
- Proximal Gradient Descent for L1 Regularization(近端梯度下降求解L1正则化问题)
假设我们要求解以下的最小化问题: $min_xf(x)$ 如果$f(x)$可导,那么一个简单的方法是使用Gradient Descent (GD)方法,也即使用以下的式子进行迭代求解: $x_{k+1 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- 梯度下降(Gradient Descent)
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)相关概念
梯度,直观理解: 梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中, 梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过 ...
- One-hot 编码/TF-IDF 值来提取特征,LAD/梯度下降法(Gradient Descent),Sigmoid
1. 多值无序类数据的特征提取: 多值无序类问题(One-hot 编码)把“耐克”编码为[0,1,0],其中“1”代表了“耐克”的中 间位置,而且是唯一标识.同理我们可以把“中国”标识为[1,0],把 ...
- [机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自网上的免费课程和一些经典书籍,免费课 ...
- ML:梯度下降(Gradient Descent)
现在我们有了假设函数和评价假设准确性的方法,现在我们需要确定假设函数中的参数了,这就是梯度下降(gradient descent)的用武之地. 梯度下降算法 不断重复以下步骤,直到收敛(repeat ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
随机推荐
- Echo团队Alpha冲刺随笔 - 第三天
项目冲刺情况 进展 完成了三分一左右,前端整体页面框架已有,后端也在稳步推进 问题 今天问题较少,主要还是出在对于框架的掌握上 心得 继续加油! 今日会议内容 黄少勇 今日进展 实现社区公告,个人信息 ...
- Android使用属性动画ValueAnimator动态改变SurfaceView的背景颜色
以下是主要代码,难点和疑问点都写在注释中: /** * 开始背景动画(此处为属性动画) */ private void startBackgroundAnimator(){ /* *参数解释: *ta ...
- LInq之Take Skip TakeWhile SkipWhile Reverse Union Concat 用法
废话不多说,直接上代码,代码有注释!自行运行测试! class Program { static void Main(string[] args) { string[] names = { " ...
- [Spark][python]RDD的collect 作用是什么?
[Spark][Python]sortByKey 例子的继续 RDD的collect() 作用是什么? “[Spark][Python]sortByKey 例子”的继续 In [20]: mydata ...
- CSS 边框(border)实例
CSS 边框(border)实例:元素的边框 (border) 是围绕元素内容和内边距的一条或多条线. CSS border 属性允许你规定元素边框的样式.宽度和颜色. CSS 边框属性属性 描述bo ...
- 这里已不再更新,访问新博客请移步 http://www.douruixin.com
这里已不再更新,访问新博客请移步 http://www.douruixin.com
- Python常见字符编码间的转换
主要内容: 1.Unicode 和 UTF-8的爱恨纠葛 2.字符在硬盘上的存储 3.编码的转换 4.验证编码是否转换正确 5.Python bytes类型 前 ...
- 牛客多校第三场-A-PACM Team-多维背包的01变种
题目我就不贴了...说不定被查到要GG... 题意就是我们需要在P,A,C,M四个属性的限制下,找到符合条件的最优解... 这样我们就需要按照0/1背包的思路,建立一个五维度数组dp[i][j][k] ...
- Scrutiny of Partner's individual project Code
因为队友的代码并没有完整的实现个人项目的完整功能. 已实现功能: 1.对单个单词进行词频统计 2.能够按照老师的要求的格式对制定的有效字符串进行匹配,并且输出至指定文件. 未实现: 1.对连续多个单词 ...
- Linux内核读书笔记第六周
主要内容: 什么是调度 调度实现原理 Linux上调度实现的方法 调度相关的系统调用 什么是调度 现在的操作系统都是多任务的,为了能让更多的任务能同时在系统上更好的运行,需要一个管理程序来管理计算机上 ...