【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎的更多相关文章
- 基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
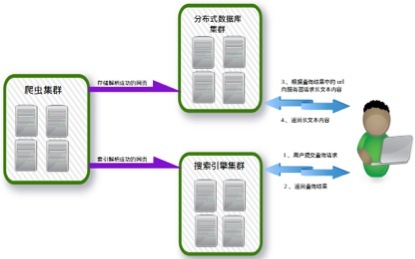
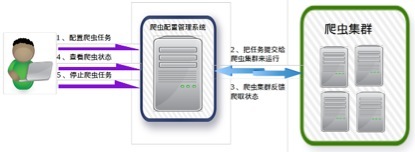
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎 网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并 ...
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- 网络爬虫与搜索引擎优化(SEO)
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引. ...
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- 【Nutch2.3基础教程】集成Nutch/Hadoop/Hbase/Solr构建搜索引擎:安装及运行【集群环境】
1.下载相关软件,并解压 版本号如下: (1)apache-nutch-2.3 (2) hadoop-1.2.1 (3)hbase-0.92.1 (4)solr-4.9.0 并解压至/opt/jedi ...
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
随机推荐
- 来谈谈 WebAssembly 是个啥?为何说它会影响每一个 Web 开发者?
作者:link 原文:What is WebAssembly and why it affects web developers! 你听说过WebAssembly吗?这是由Google, Micros ...
- vue组件之echarts报表
vue组件之echarts报表 将echarts报表封装成组件,动态传入数据,显示图表. 1.饼状图 父组件: <MPie :datas="piedata"></ ...
- 在Ubuntu 16.04如何安装Java使用apt-get的
转自:https://www.howtoing.com/how-to-install-java-with-apt-get-on-ubuntu-16-04/ 的Java和JVM(Java的虚拟机)是广泛 ...
- 领域Command
一.项目结构 二.代码 /// <summary> /// /// </summary> public interface ICommand { } /// <summa ...
- MySQL数据库篇之索引原理与慢查询优化之一
主要内容: 一.索引的介绍 二.索引的原理 三.索引的数据结构 四.聚集索引与辅助索引 五.MySQL索引管理 六.测试索引 七.正确使用索引 八.联合索引与覆盖索引 九.查询优化神器--explai ...
- react-native init安装指定版本的react-native
C:\Users\ZHONGZHENHUA\imooc_gp\index.js index.js /** @format */ import React,{ Component } from 'rea ...
- 游戏动作师使用Unity3D遇到过的所有问题
http://blog.csdn.net/onafioo/article/details/50865169 http://www.gameres.com/thread_480489.html 文/拉撒 ...
- _LightColor0将会是主要的directional light的颜色。
LightMode是个非常重要的选项,因为它将决定该pass中光源的各变量的值.如果一个pass没有指定任何LightMode tag,那么我们就会得到上一个对象残留下来的光照值,这并不是我们想要的. ...
- java-tip-HashMap
HashMap的基本查找过程: 先使用key.hashCode()生成哈希值,根据哈希值来确定key存放的位置 找到key在数组中的位置后,再使用key.equals()方法来找到指定的key. 1. ...
- 28-组合数(dfs)
http://acm.nyist.edu.cn/JudgeOnline/problem.php?pid=32 组合数 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 ...