runoob-pandas(python)
https://www.runoob.com/pandas/pandas-tutorial.html
Pandas 教程

Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 应用
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Pandas 安装
安装 pandas 需要基础环境是 Python,开始前我们假定你已经安装了 Python 和 Pip。
使用 pip 安装 pandas:
pip install pandas
安装成功后,我们就可以导入 pandas 包使用:
import pandas
实例 - 查看 pandas 版本
>>> pandas.__version__ # 查看版本
'1.1.5'
导入 pandas 一般使用别名 pd 来代替:
import pandas as pd
实例 - 查看 pandas 版本
>>> pd.__version__ # 查看版本
'1.1.5'
Pandas 数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
创建一个简单的 Series 实例:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
输出结果如下:
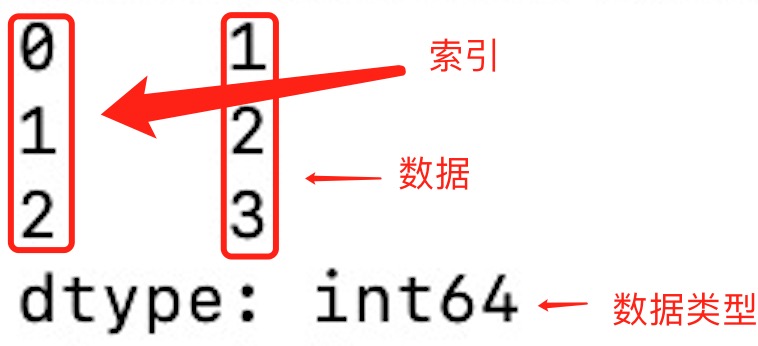
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])
输出结果如下:
2
我们可以指定索引值,如下实例:
实例
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
输出结果如下:

根据索引值读取数据:
Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
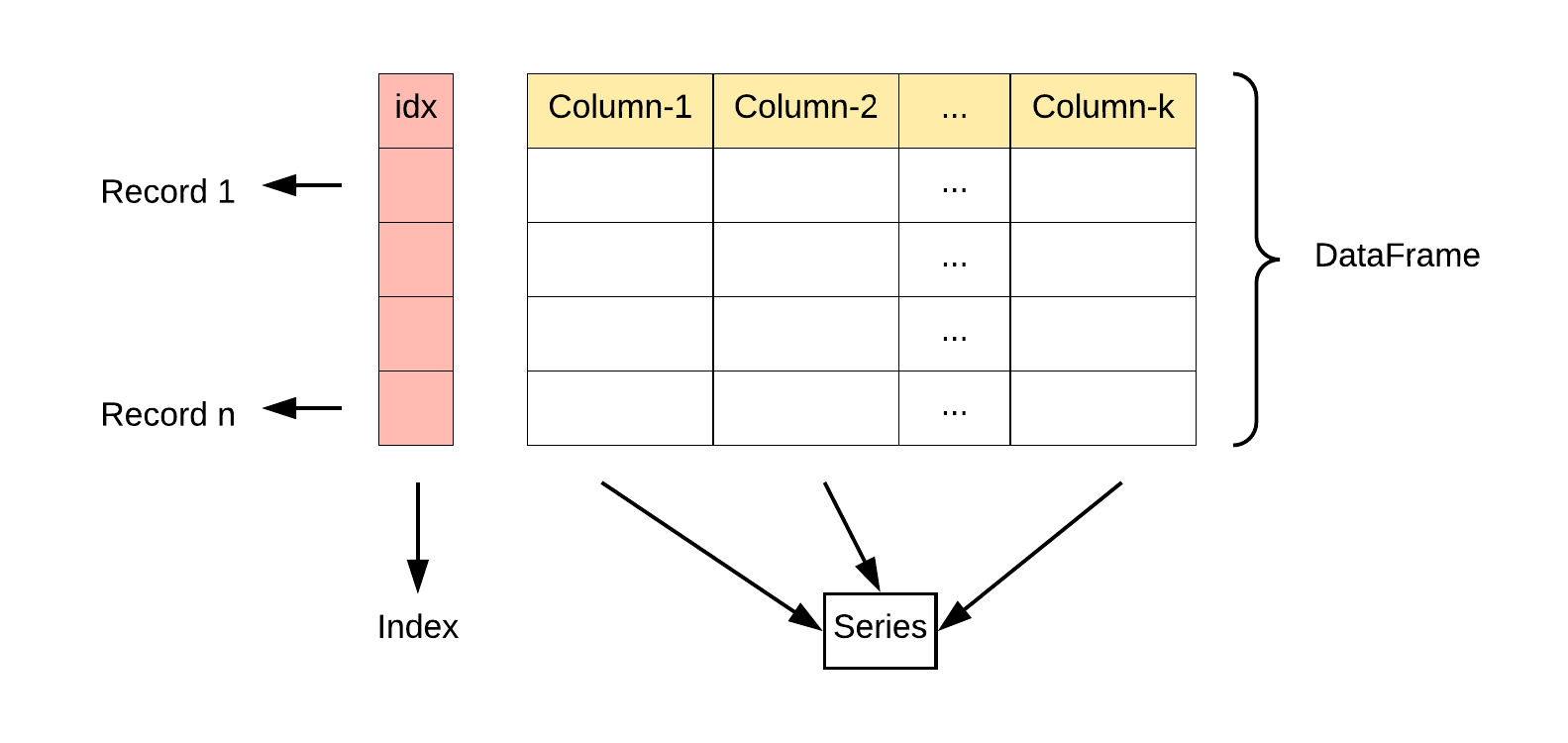
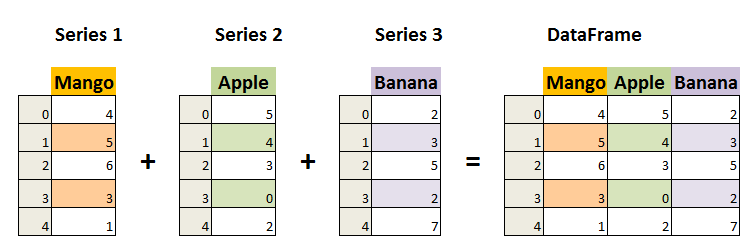
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
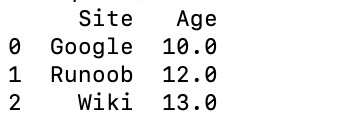
实例 - 使用列表创建
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
输出结果如下:
以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
ndarrays 可以参考:NumPy Ndarray 对象
实例 - 使用 ndarrays 创建
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
输出结果如下:
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):
Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件,本文以 nba.csv 为例,你可以下载 nba.csv 或打开 nba.csv 查看。
实例
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
实例
df = pd.read_csv('nba.csv')
print(df)
输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
.. ... ... ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
实例
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
执行成功后,我们打开 site.csv 文件,显示结果如下:
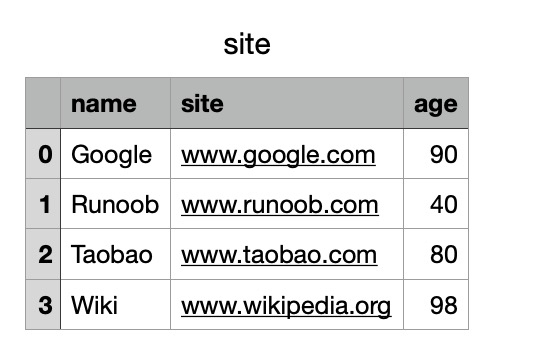
数据处理
Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,内容如下:
实例
实例
df = pd.read_json('sites.json')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
实例
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
以上实例输出结果为:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
在这个教程中,我们将利用 Pandas包来进行数据清洗。
上表包含来四种空数据:
- n/a
- NA
- —
- na
Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
我们可以通过 isnull() 判断各个单元格是否为空。
实例
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
runoob-pandas(python)的更多相关文章
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- https://www.runoob.com/python/python-variable-types.html
https://www.runoob.com/python/python-variable-types.html
- Pandas python
原文: https://github.com/catalystfrank/Python4DataScience.CH 和大熊猫们(Pandas)一起游戏吧! Pandas是Python的一个 ...
- 基于pandas python sklearn 的美团某商家的评论分类(文本分类)
美团店铺评价语言处理以及分类(NLP) 第一篇 数据分析部分 第二篇 可视化部分, 本文是该系列第三篇,文本分类 主要用到的包有jieba,sklearn,pandas,本篇博文主要先用的是词袋模型( ...
- 基于pandas python的美团某商家的评论销售(数据分析)
数据初步的分析 本文是该系列的第一篇 数据清洗 数据初步的统计 第二篇 数据可视化 第三篇 数据中的评论数据用于自然语言处理 from pyecharts import Bar,Pie import ...
- 推荐:python科学计算pandas/python画图库matplotlib【转】
机器学习基础3--python科学计算pandas(上) 地址:https://wangyeming.github.io/2018/09/04/marchine-learning-base-panda ...
- Pandas Python For Data Science
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- 【python操作Excel的常见方法汇总】 xlrd pandas xlwings
用python处理Excel数据,实现Excel的功能:分列.透视等功能 1. Excel 解压文件 #解压tar_path中的压缩文件到uzipPath def unzip_archive(tar_ ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- 共享存储ISCSI
建立共享iscsi磁盘组 资源环境 服务端:192.168.2.131 客户端:192.168.2.[110,169] 服务端磁盘: [root@centos ~]# lsblk NAME MAJ:M ...
- Python中函数或者类对象带()与不带()的区别——闭包和函数返回时的常见现象
Python中函数或者类对象带()与不带()的区别-----闭包和函数返回时的常见现象 - 函数不带括号时,调用的是这个函数本身 ,是整个函数体,是一个函数对象,不需等该函数执行完成,返回一个已定义函 ...
- .NET Core 线程(Thread)底层原理浅谈
简介 线程,进程,协程基本概念不再赘述. 原生线程和用户线程 原生线程 在内核态中创建的线程,只服务于内核态 用户线程 由User Application创建的线程,该线程会在内核态与用户态中间来回穿 ...
- 一文详解:项目如何从Docker慢慢演变成了K8s部署
今天,我们将深入探讨一个项目部署的演变过程.在这篇文章中,为了紧扣主题,我们将从 Docker 开始讲解,分析为什么一个传统的项目逐步演变成了今天流行的 Kubernetes(K8s)集群部署架构.我 ...
- 三剑客-grep-awk-sed
三剑客-grep-awk-sed grep 格式: grep 参数 过滤文件内容 文件名称 cat file|grep '过滤的内容' 参数: -v 取反 -E 支持扩展正则 | 或者 egr ...
- JS 正则表示式 字符串匹配 忽略大小写
在项目中遇到了需要使用字符串进行正则匹配,同时还要忽略大小写可以按照以下方法:1 先使用new RegExp(newVal, 'i')生成需要匹配的规则,其中 'i' 表示忽略大小写2 再对相应的字符 ...
- 成为Java GC专家系列(3) — 如何优化Java垃圾回收机制
本文是成为Java GC专家系列文章的第三篇.在第一篇<成为JavaGC专家Part I - 深入浅出Java垃圾回收机制>中我们学习了不同GC算法的执行过程,GC是如何工作的,什么是新生 ...
- nginx之日志
1)耗时问题定位 这几天在优化服务器的响应时间,在根据 nginx 的 accesslog 中 requesttime进行程序优化时,发现有个接口,直接返回数据,平均的requesttime进行程序优 ...
- 进程管理工具之supervisor(完整版)*
Supervisor 介绍 Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启.它是通过fork/ex ...
- Winform解决跨线程更新UI的问题
最近又拿起了Winform的程序,由于要起socket server,所以需要起线程,这里就遇到了经典的跨线程UI调用的问题. 如果什么都不写,直接由线程更新UI,会报错:线程间操作无效. 这里的解决 ...