对象池框架 commons pool2 原理与实践
当资源对象的创建/销毁比较耗时的场景下,可以通过"池化"技术,达到资源的复用,以此来减少系统的开销、增大系统吞吐量,比如数据库连接池、线程池、Redis 连接池等都是使用的该方式。
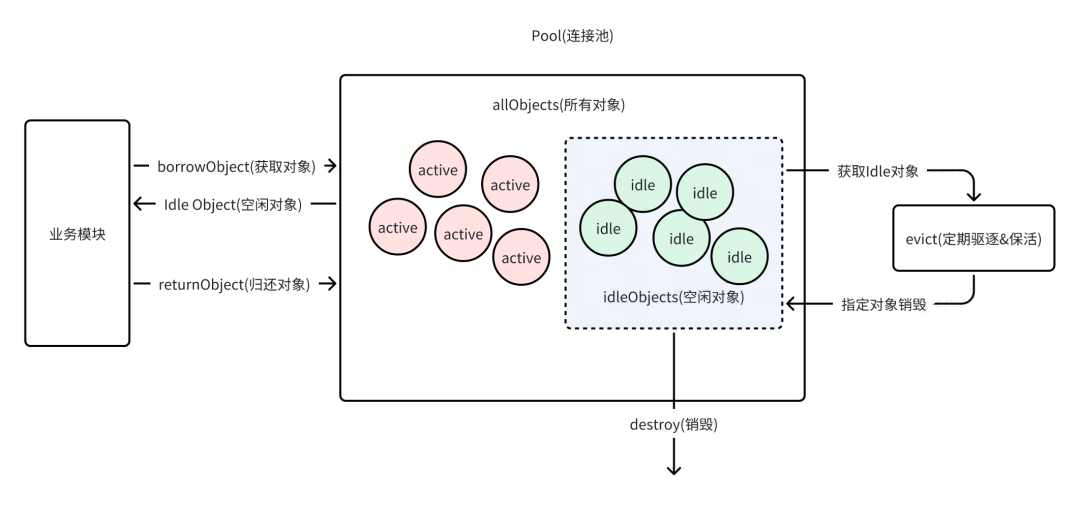
Apache Commons Pool 提供了通用对象池的实现,用于管理和复用对象,以提高系统的性能和资源利用率。
1 基础用法
1.1 添加依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.0</version>
</dependency>
1.2 定义对象工厂
PooledObjectFactory 是一个池化对象工厂接口,定义了生成对象、激活对象、钝化对象、销毁对象的方法,如下:
public interface PooledObjectFactory<T> {
/**
* Creates an instance that can be served by the pool and wrap it in a
*/
PooledObject<T> makeObject() throws Exception;
/**
* Destroys an instance no longer needed by the pool
*/
void destroyObject(PooledObject<T> p) throws Exception;
/**
* Ensures that the instance is safe to be returned by the pool
*/
boolean validateObject(PooledObject<T> p);
/**
* Reinitializes an instance to be returned by the pool
*/
void activateObject(PooledObject<T> p) throws Exception;
/**
* Uninitializes an instance to be returned to the idle object pool
*/
void passivateObject(PooledObject<T> p) throws Exception;
}
以下是一个简单的示例:
- 定义需要池化的对象 MyObject
public class MyObject {
private String uid = UUID.randomUUID().toString();
private volatile boolean valid = true;
public void initialize() {
System.out.println("初始化对象" + uid);
valid = true;
}
public void destroy() {
System.out.println("销毁对象" + uid);
valid = false;
}
public boolean isValid() {
return valid;
}
public String getUid() {
return uid;
}
}
- 定义对象工厂
public class MyObjectFactory implements PooledObjectFactory<MyObject> {
@Override
public PooledObject<MyObject> makeObject() throws Exception {
// 创建一个新对象
MyObject object = new MyObject();
// 初始化对象
object.initialize();
return new DefaultPooledObject<>(object);
}
@Override
public void destroyObject(PooledObject<MyObject> p) throws Exception {
// 销毁对象
p.getObject().destroy();
}
@Override
public boolean validateObject(PooledObject<MyObject> p) {
return p.getObject().isValid();
}
@Override
public void activateObject(PooledObject<MyObject> p) throws Exception {
}
@Override
public void passivateObject(PooledObject<MyObject> p) throws Exception {
}
}
1.3 配置对象池
创建 GenericObjectPool 对象,并设置相关参数,如最大对象数量、最小空闲对象数量等。
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxTotal(20);
config.setMaxIdle(5);
config.setTestWhileIdle(true);
config.setMinEvictableIdleTimeMillis(60000L);
GenericObjectPool<MyObject> pool = new GenericObjectPool<>(new MyObjectFactory(), config);
1.4 借用和归还对象
MyObject myObject = null;
try {
myObject = pool.borrowObject();
System.out.println("get对象" + myObject.getUid() + " thread:" + Thread.*currentThread*().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (myObject != null) {
pool.returnObject(myObject);
}
} catch (Exception e) {
e.printStackTrace();
}
}
2 Jedis 连接池
Jedis 是一个 Java 语言的 Redis 客户端库。它提供了一组易于使用的 API,可以用来连接和操作 Redis 数据库。
它的内部使用 Commons Pool 来管理 Redis 连接 ,我们使用 jedis 3.3.0 版本写一个简单的示例。
public class JedisMain {
public static void main(String[] args) throws Exception{
// 创建连接池配置
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100);
config.setMaxIdle(20);
// 创建连接池
JedisPool pool = new JedisPool(config, "localhost", 6379);
// 获取连接
Jedis jedis = pool.getResource();
jedis.set("hello" , "张勇");
// 使用连接
String value = jedis.get("hello");
System.out.println(value);
// 归还连接
jedis.close();
// 关闭连接池
// pool.close();
Thread.sleep(5000);
}
}
如下图,JedisFactory 实现了对象工厂,实现了创建对象、销毁对象、验证对象、激活对象四个方法。
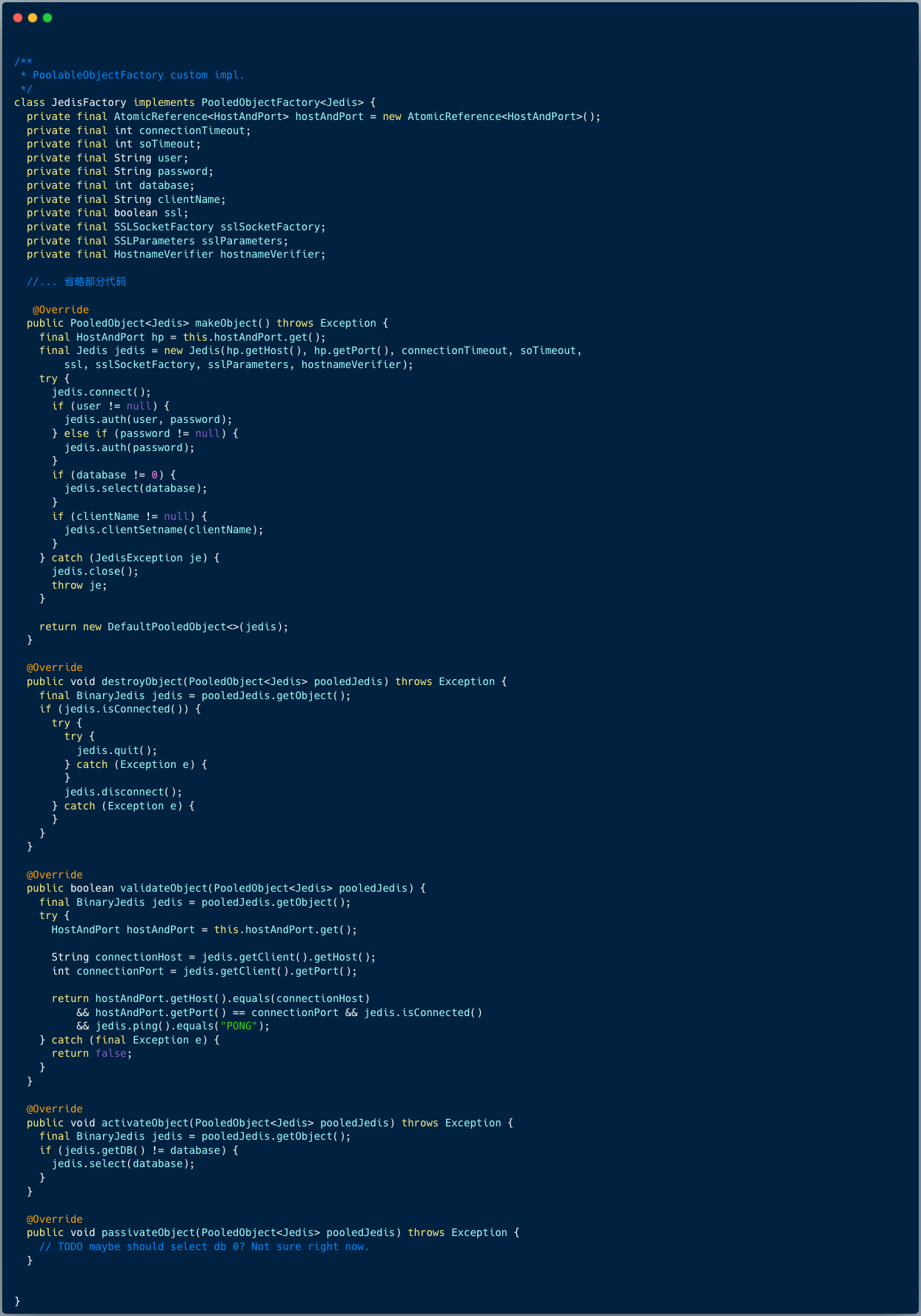
比如验证对象方法,逻辑是调用 Jedis 的 ping 方法,判断该连接是否存活。
3 原理解析
我们重点解析 GenericObjectPool 类的原理。
3.1 初始化
public GenericObjectPool(
final PooledObjectFactory<T> factory,
final GenericObjectPoolConfig<T> config) {
super(config, ONAME_BASE, config.getJmxNamePrefix());
if (factory == null) {
jmxUnregister(); // tidy up
throw new IllegalArgumentException("factory may not be null");
}
this.factory = factory;
idleObjects = new LinkedBlockingDeque<>(config.getFairness());
setConfig(config);
}
private final Map<IdentityWrapper<T>, PooledObject<T>> allObjects =
new ConcurrentHashMap<>();
初始化做三件事情:
初始化 JedisFactory 工厂对象。
对象容器 idleObjects , 类型是 LinkedBlockingDeque 。
因此存储容器有两个,所有的对象 allObjects 和空闲对象 idleObjects (可以直接取出使用)。
配置对象池属性 。
3.2 创建对象
我们关注 GenericObjectPool 类的 borrowObject 方法。
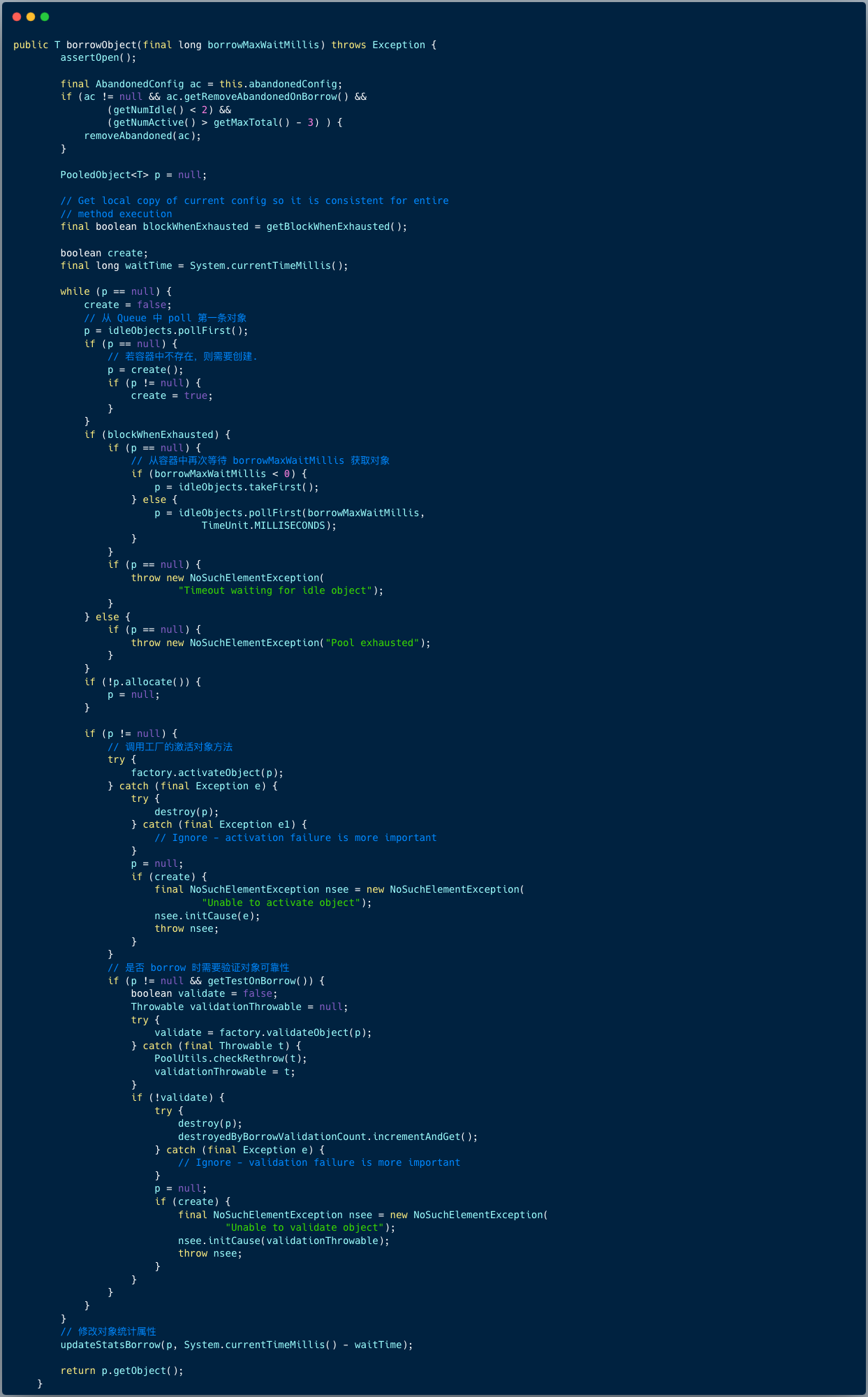
逻辑其实很简单 :
从容器中获取第一个条目对象,若没有获取,则调用工厂对象的创建对象方法,并将该对象加入到全局对象 Map。
创建成功后,调用对象的激活方法,接着验证对象的可靠性,最后将对象返回。
3.3 归还连接
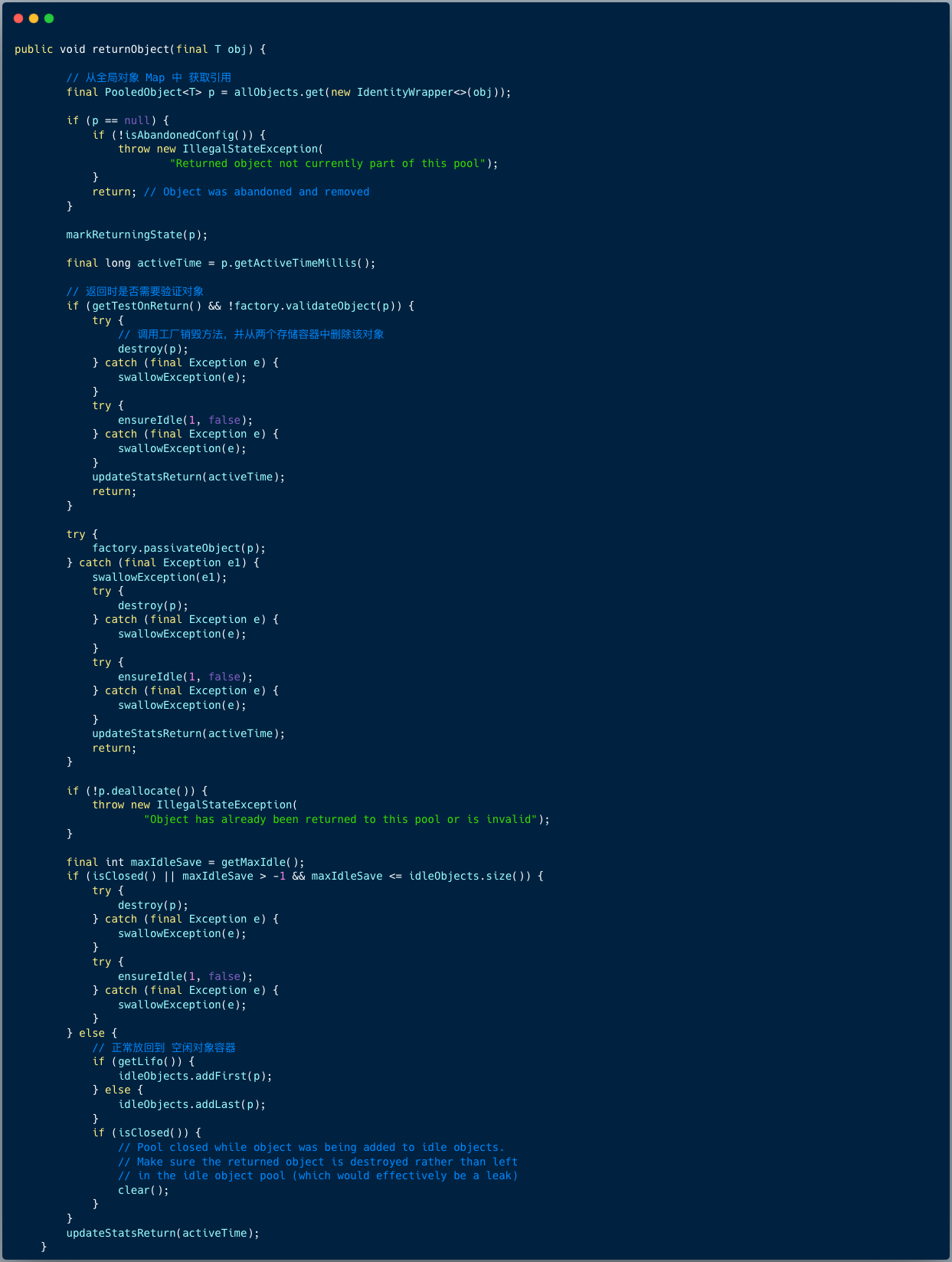
流程如下:
- 判断返还对象时是否校验,假如校验失败,则销毁该对象,将该对象从存储容器中删除 ;
- 调用工厂对象的激活对象方法 ;
- 若空闲对象 Map 元素大小达到最大值,则销毁该对象,将该对象从存储容器中删除 ;
- 正常将对象放回到空闲对象容器 idleObjects 。
参考资料:
对象池框架 commons pool2 原理与实践的更多相关文章
- Netty源码解析 -- 对象池Recycler实现原理
由于在Java中创建一个实例的消耗不小,很多框架为了提高性能都使用对象池,Netty也不例外. 本文主要分析Netty对象池Recycler的实现原理. 源码分析基于Netty 4.1.52 缓存对象 ...
- Java GenericObjectPool 对象池化技术--SpringBoot sftp 连接池工具类
Java BasePooledObjectFactory 对象池化技术 通常一个对象创建.销毁非常耗时的时候,我们不会频繁的创建和销毁它,而是考虑复用.复用对象的一种做法就是对象池,将创建好的对象放入 ...
- Unity性能优化-对象池
1.对象池Object Pool的原理: 有些GameObject是在游戏中需要频繁生成并销毁的(比如射击游戏中的子弹),以前的常规做法是:Instantiate不断生成预设件Prefab,然后采用碰 ...
- 对象池在 .NET (Core)中的应用[1]: 编程体验
借助于有效的自动化垃圾回收机制,.NET让开发人员不在关心对象的生命周期,但实际上很多性能问题都来源于GC.并不说.NET的GC有什么问题,而是对象生命周期的跟踪和管理本身是需要成本的,不论交给应用还 ...
- 对象池在 .NET (Core)中的应用[2]: 设计篇
<编程篇>已经涉及到了对象池模型的大部分核心接口和类型.对象池模型其实是很简单的,不过其中有一些为了提升性能而刻意为之的实现细节倒是值得我们关注.总的来说,对象池模型由三个核心对象构成,它 ...
- commons.pool2 对象池的使用
commons.pool2 对象池的使用 ? 1 2 3 4 5 <dependency> <groupId>org.apache.commons</groupI ...
- 基于Apache组件,分析对象池原理
池塘里养:Object: 一.设计与原理 1.基础案例 首先看一个基于common-pool2对象池组件的应用案例,主要有工厂类.对象池.对象三个核心角色,以及池化对象的使用流程: import or ...
- Apache common pool2 对象池
对象池的容器:包含一个指定数量的对象.从池中取出一个对象时,它就不存在池中,直到它被放回.在池中的对象有生命周期:创建,验证,销毁,对象池有助于更好地管理可用资源,防止JVM内部大量临时小对象,频繁触 ...
- Java--对象池化技术 org.apache.commons.pool2.ObjectPool
org.apache.commons.pool2.ObjectPool提供了对象池,开发的小伙伴们可以直接使用来构建一个对象池 使用该对象池具有两个简单的步骤: 1.创建对象工厂,org.apache ...
- 对象池化技术 org.apache.commons.pool
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率.Jakarta Commons Pool组件提供了一整套用于实现对象池化的框架,以及若干种各具特色的对象池实现,可以 ...
随机推荐
- Linux系统搭建性能测试监控体系
一.安装Grafana 1.Grafana介绍(默认端口3000): Grafana是一个开源的监控和可视化工具,用于显示和跟踪各种指标,数据和日志,支持多种源,包括influxDB.promethe ...
- 开源IDS/IPS Suricata的部署与使用
目录 前言 在Linux上部署Suricata Suricata的基本配置 配置文件 Suricata的规则 Suricata的使用 Suricata检测SQL注入 前言 Suricata 是一个高性 ...
- Spring IOC、DI、AOP原理和实现
(1)Spring IOC原理 IOC的意思是控件反转也就是由容器控制程序之间的关系,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 16 期(2024年12.01-12.08)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- StarBlog博客Vue前端开发笔记:(2)SASS与SCSS
前言 本项目需要使用 SCSS 来编写页面样式. Sass (Syntactically Awesome Stylesheets)是一个 css 预处理器,而 SCSS 是 Sass 的一种语法格式, ...
- ArkTs布局入门01——线性布局(Row/Column)
1.概述 布局指用特定的组件或者属性来管理用户页面所放置UI组件的大小和位置.组件按照布局的要求依次排列,构成应用的页面. 在声明式UI中,所有的页面都是由自定义组件构成,开发者可以根据自己的需求,选 ...
- zz Spring 是一种反模式
Java 将会消亡 – Martin Vysny – 第一性原理思考 原文标题"Java 将会消亡", 我并不认可 Java 会消亡一说, 作者还处于 FP 亢奋期,而我已经从 F ...
- [Mybatis Plus]lambdaQueryWrapper和QueryWrapper的选择
结论 更推荐使用:LambdaQueryWrapper QueryWrapper:灵活但是不够类型安全 LambdaQueryWrapper:安全 分析 在MyBatis-Plus中,QueryWra ...
- 转载 Netty tls验证
https://blog.csdn.net/luo15242208310/article/details/108215019 目录Java ssl单向TLSServer端Client端双向TLSser ...
- JVM故障分析及性能优化系列之四:jstack生成的Thread Dump日志线程状态
https://www.javatang.com/archives/2017/10/25/36441958.html JVM故障分析及性能优化系列文章 JVM故障分析及性能优化系列之一:使用jstac ...