LDA线性判别分析原理及python应用(葡萄酒案例分析)
目录
线性判别分析(LDA)数据降维及案例实战
一、LDA是什么
- LDA概念及与PCA区别
LDA线性判别分析(Linear Discriminant Analysis)也是一种特征提取、数据压缩技术。在模型训练时候进行LDA数据处理可以提高计算效率以及避免过拟合。它是一种有监督学习算法。
与PCA主成分分析(Principal Component Analysis)相比,LDA是有监督数据压缩方法,而PCA是有监督数据压缩及特征提取方法。PCA目标是寻找数据集最大方差方向作为主成分,LDA目标是寻找和优化具有可分性特征子空间。其实两者各有优势,更深入详细的区分和应用等待之后的学习,这里我仍然以葡萄酒数据集分类为案例记录原理知识的学习和具体实现步骤。
对比我之前记录的PCA请看:PCA数据降维原理及python应用(葡萄酒案例分析)
- LDA内部逻辑实现步骤
- 标准化d维数据集。
- 计算每个类别的d维均值向量。
- 计算跨类散布矩阵
和类内散布矩阵
.
- 线性判别式及特征计算。
- 按特征值降序排列,与对应的特征向量成对排序。
- 选择最具线性判别性的前k个特征,构建变换矩阵
.
- 通过变换矩阵将原数据投影至k维子空间。
二、计算散布矩阵
1、数据集下载
下载葡萄酒数据集wine.data到本地,或者到时在加载数据代码是从远程服务器获取,为了避免加载超时推荐下载本地数据集。
下载之后用记事本打开wine.data可见得,第一列为葡萄酒数据类别标签,共有3类,往后的13列为特征值。
数据加载以及标准化数据处理与PCA技术一样,具体可以翻看PCA数据降维原理及python应用(葡萄酒案例分析),或者本文第五部分完整代码有具体实现代码。
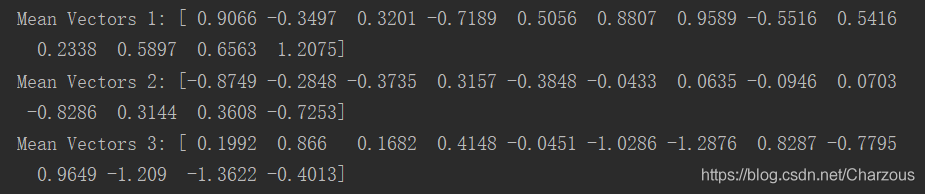
2、计算散布矩阵第一步,先计算每个类别每个样本的均值向量。
公式: , i =1,2,3 表示类别,每个特征取平均值。
得到三个均值向量为:
代码实现:
# 计算均值向量
np.set_printoptions(precision=4)
mean_vecs = []
for label in range(1, 4):
mean_vecs.append(np.mean(x_train_std[y_train == label], axis=0))
打印查看结果:
3、计算类内散布矩阵。
每个样本 i 的散布矩阵:
类内散布矩阵即每个样本的累加:
代码实现:
# 计算类内散布矩阵
k = 13
Sw = np.zeros((k, k))
for label, mv in zip(range(1, 4), mean_vecs):
Si = np.zeros((k, k))
Si = np.cov(x_train_std[y_train == label].T)
Sw += Si
print("类内散布矩阵:",Sw.shape[0],"*",Sw.shape[1])
矩阵规模:

4、计算跨类散布矩阵。
公式:
公式中,m是所有样本总均值向量,也就是不分类的情况下计算特征平均值。
代码实现:
# 计算跨类散布矩阵
mean_all = np.mean(x_train_std, axis=0)
Sb = np.zeros((k, k))
for i, col_mv in enumerate(mean_vecs):
n = x_train[y_train == i + 1, :].shape[0]
col_mv = col_mv.reshape(k, 1) # 列均值向量
mean_all = mean_all.reshape(k, 1)
Sb += n * (col_mv - mean_all).dot((col_mv - mean_all).T)
三、线性判别式及特征选择
LDA其他步骤与PCA相似,但是,PCA是分解协方差矩阵提取特征值,LDA则是求解矩阵 得到广义特征值,实现:
# 计算广义特征值
eigen_vals, eigen_vecs = np.linalg.eig(np.linalg.inv(Sw).dot(Sb))
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))]
eigen_pairs = sorted(eigen_pairs, key=lambda k: k[0], reverse=True)
对特征值降序排列之后,打印看看:
print("特征值降序排列:")
for eigen_val in eigen_pairs:
print(eigen_val[0])
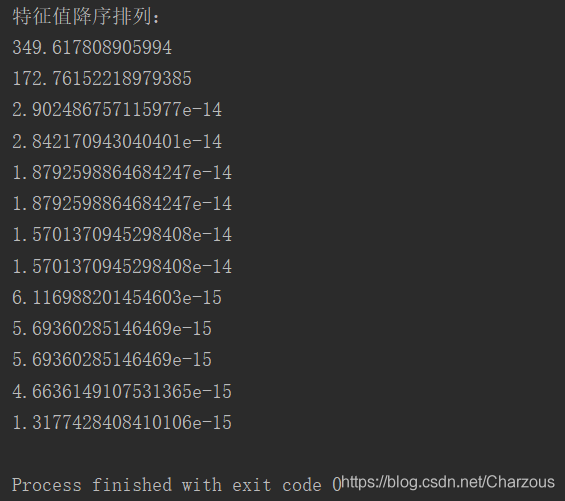
从捕捉到的特征值发现,前两个可以占据大部分数据集特征了,接下来可视化表示更加直观地观察:
# 线性判别捕捉,计算辨识力
tot = sum(eigen_vals.real)
discr = []
# discr=[(i/tot) for i in sorted(eigen_vals.real,reverse=True)]
for i in sorted(eigen_vals.real, reverse=True):
discr.append(i / tot)
# print(discr)
cum_discr = np.cumsum(discr) # 计算累加方差
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.bar(range(1,14),discr,alpha=0.5,align='center',label='独立辨识力')
plt.step(range(1,14),cum_discr,where='mid',label='累加辨识力')
plt.ylabel('"辨识力"比')
plt.xlabel('线性判别')
plt.ylim([-0.1,1.1])
plt.legend(loc='best')
plt.show()
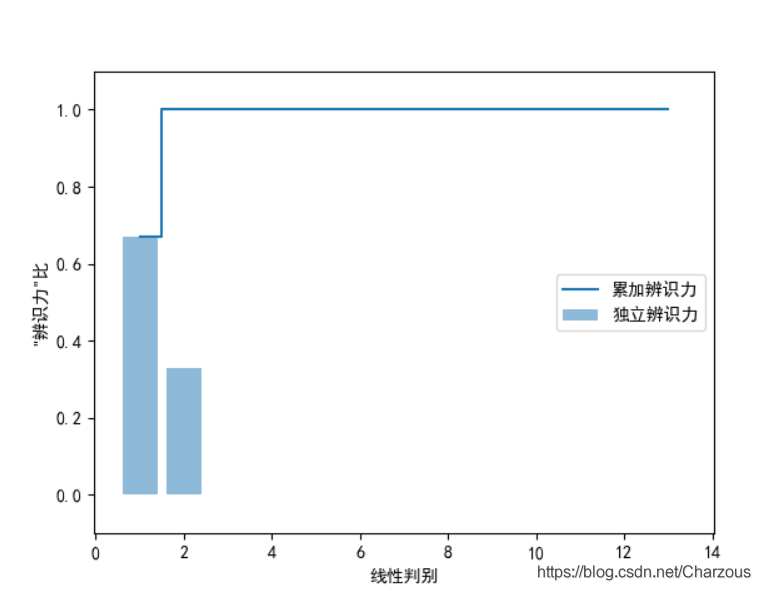
很明显,最具线性判别的前两个特征捕捉了100%的信息,下面以此构建变换矩阵 W.
四、样本数据降维投影
构建变换矩阵:
# 变换矩阵
w = np.hstack((eigen_pairs[0][1][:, np.newaxis].real, eigen_pairs[1][1][:, np.newaxis].real))
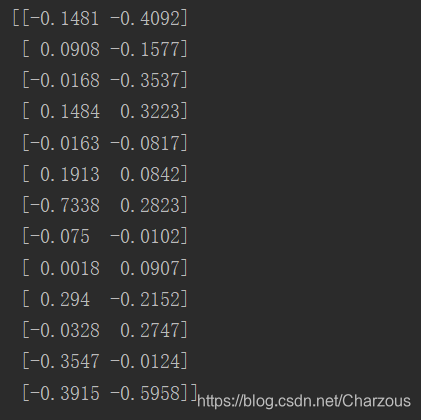
print(w)
来瞅瞅,这就是前两个特征向量的矩阵表示。
现在有了变换矩阵,就可以将样本训练数据投影到降维特征空间了:. 并展示分类结果:
# 样本数据投影到低维空间
x_train_lda = x_train_std.dot(w)
colors = ['r', 'g', 'b']
marks = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), colors, marks):
plt.scatter(x_train_lda[y_train == l, 0],
x_train_lda[y_train == l, 1] * -1,
c=c, label=l, marker=m)
plt.xlabel('LD 1')
plt.ylabel('LD 2')
plt.legend(loc='lower right')
plt.show()
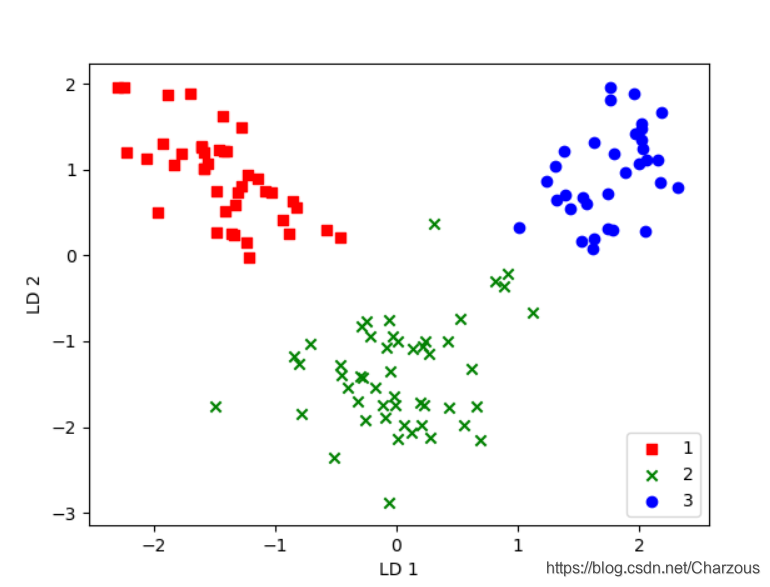
很明显,三个类别线性可分,效果也不错,相比较PCA方法,我感觉LDA分类结果更好,我们知道,LDA是有监督的方法,有利用到数据集的标签。
五、完整代码


import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加载
# df_wine=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)#服务器加载 # split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0) # standardize the feature 标准化单位方差
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test) # 计算均值向量
np.set_printoptions(precision=4)
mean_vecs = []
for label in range(1, 4):
mean_vecs.append(np.mean(x_train_std[y_train == label], axis=0))
# print("Mean Vectors %s:" % label,mean_vecs[label-1]) # 计算类内散布矩阵
k = 13
Sw = np.zeros((k, k))
for label, mv in zip(range(1, 4), mean_vecs):
Si = np.zeros((k, k))
# for row in x_train_std[y_train==label]:
# row,mv=row.reshape(n,1),mv.reshape(n,1)
# Si+=(row-mv).dot((row-mv).T)
Si = np.cov(x_train_std[y_train == label].T)
Sw += Si
# print("类内散布矩阵:",Sw.shape[0],"*",Sw.shape[1])
# print("类内标签分布:",np.bincount(y_train)[1:]) # 计算跨类散布矩阵
mean_all = np.mean(x_train_std, axis=0)
Sb = np.zeros((k, k))
for i, col_mv in enumerate(mean_vecs):
n = x_train[y_train == i + 1, :].shape[0]
col_mv = col_mv.reshape(k, 1) # 列均值向量
mean_all = mean_all.reshape(k, 1)
Sb += n * (col_mv - mean_all).dot((col_mv - mean_all).T)
# print("跨类散布矩阵:", Sb.shape[0], "*", Sb.shape[1]) # 计算广义特征值
eigen_vals, eigen_vecs = np.linalg.eig(np.linalg.inv(Sw).dot(Sb))
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))]
eigen_pairs = sorted(eigen_pairs, key=lambda k: k[0], reverse=True)
# print(eigen_pairs[0][1][:,np.newaxis].real) # 第一特征向量
# print("特征值降序排列:")
# for eigen_val in eigen_pairs:
# print(eigen_val[0]) # 线性判别捕捉,计算辨识力
tot = sum(eigen_vals.real)
discr = []
# discr=[(i/tot) for i in sorted(eigen_vals.real,reverse=True)]
for i in sorted(eigen_vals.real, reverse=True):
discr.append(i / tot)
# print(discr)
cum_discr = np.cumsum(discr) # 计算累加方差
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
# plt.bar(range(1,14),discr,alpha=0.5,align='center',label='独立辨识力')
# plt.step(range(1,14),cum_discr,where='mid',label='累加辨识力')
# plt.ylabel('"辨识力"比')
# plt.xlabel('线性判别')
# plt.ylim([-0.1,1.1])
# plt.legend(loc='best')
# plt.show() # 转换矩阵
w = np.hstack((eigen_pairs[0][1][:, np.newaxis].real, eigen_pairs[1][1][:, np.newaxis].real))
# print(w) # 样本数据投影到低维空间
x_train_lda = x_train_std.dot(w)
colors = ['r', 'g', 'b']
marks = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), colors, marks):
plt.scatter(x_train_lda[y_train == l, 0],
x_train_lda[y_train == l, 1] * -1,
c=c, label=l, marker=m)
plt.xlabel('LD 1')
plt.ylabel('LD 2')
plt.legend(loc='lower right')
plt.show()
结语
这篇记录了这几天学习的LDA实现数据降维的方法,仍然以葡萄酒数据集为案例,在上面一步步的拆分中,我们更加清楚线性判别分析LDA方法的内部实现,在这个过程,对于初步学习的我感觉能够认识和理解更深刻,当然以后数据处理使用LDA方法时候会用到一些第三方库的类,实现起来更加方便,加油学习,期待下一篇LDA实现更简洁的方法!
我的博客园:
我的CSDN博客:原创 LDA数据压缩原理及python应用(葡萄酒案例分析)
LDA线性判别分析原理及python应用(葡萄酒案例分析)的更多相关文章
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- LDA线性判别分析
LDA线性判别分析 给定训练集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能的近,异类样例点尽可能的远,对新样本进行分类的时候,将新样本同样的投影,再根据投影得到的位置进行判断,这个新样本的 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- LDA线性判别分析(转)
线性判别分析LDA详解 1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2 ...
- LDA 线性判别分析
LDA, Linear Discriminant Analysis,线性判别分析.注意与LDA(Latent Dirichlet Allocation,主题生成模型)的区别. 1.引入 上文介绍的PC ...
- LDA(线性判别分析,Python实现)
源代码: #-*- coding: UTF-8 -*- from numpy import * import numpy def lda(c1,c2): #c1 第一类样本,每行是一个样本 #c2 第 ...
- 运用sklearn进行线性判别分析(LDA)代码实现
基于sklearn的线性判别分析(LDA)代码实现 一.前言及回顾 本文记录使用sklearn库实现有监督的数据降维技术——线性判别分析(LDA).在上一篇LDA线性判别分析原理及python应用(葡 ...
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- LDA(Linear discriminate analysis)线性判别分析
LDA 线性判别分析与Fisher算法完全不同 LDA是基于最小错误贝叶斯决策规则的. 在EMG肌电信号分析中,... 未完待续:.....
随机推荐
- italic和oblique的区别
italic和oblique都是向右倾斜的文字, 但区别在于Italic是指斜体字,而Oblique是倾斜的文字(让没有斜体属性的文字倾斜), 对于没有斜体的字体应该使用Oblique属性值来实现倾斜 ...
- springboot(五)使用FastJson返回Json视图
FastJson简介: fastJson是阿里巴巴旗下的一个开源项目之一,顾名思义它专门用来做快速操作Json的序列化与反序列化的组件.它是目前json解析最快的开源组件没有之一!在这之前jaskJs ...
- cookie 和session的简单比较
1.cookie数据存放在客户的浏览器上,session数据放在服务器上. 2.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗 考虑到安全应当使用session ...
- 高度塌陷与BFC
高度塌陷的产生条件 子元素浮动,脱离文档流 子元素绝对定位或固定定位,脱离文档流 定位产生的高度塌陷只能通过加固定高度或更换其他方案解决塌陷,本文主要讨论浮动产生塌陷的解决方法. 高度塌陷的解决方法 ...
- Linux系统zabbix_agentd客户端安装与配置
标注:官网下载zabbix安装包(zabbix安装包里包含了zabbix_agentd客户端安装包,我们只选择zabbix_agentd客户端安装) zbbix官网下载地址: http://www. ...
- Java-每日学习笔记(数据库与idea技巧)
Java杂记-2020.07.28 简单记录下今天项目用到的东西还有技术公众号学到的一些知识点 Java事务 idea编码技巧 数据库快速插入100万条数据 Java实现sql回滚 Java事务 事务 ...
- matplotlib 去掉坐标轴
#去掉x轴 plt.xticks([]) #去掉y轴 plt.yticks([]) #去掉坐标轴 plt.axis('off') 2020-06-26
- Numpy数组排序
import numpy as np x = np.array([1,4,5,2]) # array([1, 4, 5, 2]) # 返回排序后元素的原下标 np.argsort(x) # array ...
- PHP bin2hex() 函数
实例 把 "Hello World!" 转换为十六进制值: <?php 高佣联盟 www.cgewang.com$str = bin2hex("Hello Worl ...
- 7.18 NOI模拟赛 因懒无名 线段树分治 线段树维护直径
LINK:因懒无名 20分显然有\(n\cdot q\)的暴力. 还有20分 每次只询问一种颜色的直径不过带修改. 容易想到利用线段树维护直径就可以解决了. 当然也可以进行线段树分治 每种颜色存一下直 ...