LLaMA:开放和高效的基础语言模型
LLaMA:开放和高效的基础语言模型
论文:https://arxiv.org/pdf/2302.13971.pdf
代码:https://github.com/facebookresearch/llama
前言
我们介绍了LLaMA,这是一个参数范围从7B到65B的基础语言模型集合。我们在数以万亿计的标记上训练我们的模型,并表明有可能完全使用公开可用的数据集来训练最先进的模型,而不必求助于专有的和不可获取的数据集。特别是,LLaMA-13B 在大多数基准上超过了GPT-3(175B), LLaMA-65B与最好的模型Chinchilla-70B和PaLM-540B相比具有竞争力。我们向研究界发布了我们所有的模型。
总结:
- 仅仅在公开的数据集上进行训练了多个尺度的模型,就可以达到最先进的效果。
- 对模型和实现方式进行优化,加速训练。
方法
使用的数据
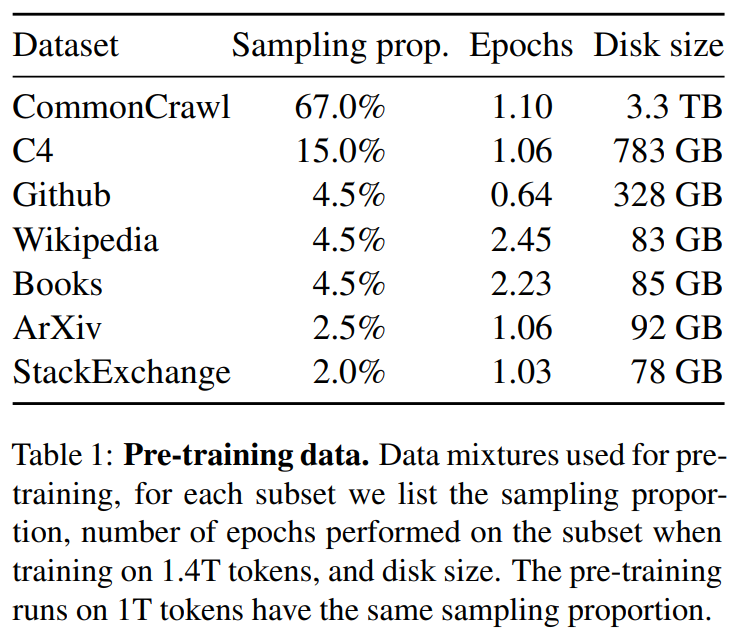
英语CommonCrawl[67%] :我们用CCNet管道( Wenzek等人 , 2020年)对五个CommonCrawl转储进行预处理,范围从2017年到2020年。这个过程在行的层面上对数据进行了删除,用fastText线性分类器进行语言识别,以去除非英语页面,并用n-gram语言模型过滤低质量内容。此外,我们训练了一个线性模型来对维基百科中用作参考文献的页面与随机抽样的页面进行分类,并丢弃了未被分类为参考文献的页面。
C4 [15%] :在探索性的实验中,我们观察到,使用多样化的预处理Com-monCrawl数据集可以提高性能。因此,我们将公开的C4数据集( Raffel等人,2020)纳入我们的数据。C4的预处理也包含重复数据删除和语言识别步骤:与CCNet的主要区别在于质量过滤,它主要依赖于标点符号的存在或网页中的单词和句子的数 量等判例。
Github[4.5%] :我们使用谷歌BigQuery上的GitHub公共数据集。我们只保留在Apache、BSD和MIT许可下发布的项目。此外,我们用基于行长或字母数字字符比例的启发式方法过滤了低质量的文件,并用规范的表达式删除了模板,如标题。最后,我们在文件层面上对结果数据集进行重复计算,并进行精确匹配。
维基百科[4.5%] :我们添加了2022年6月至8月期间的维基百科转储,涵盖了20使用拉丁字母或西里尔字母的语言:BG、CA、CS、DA、DE、EN、ES、FR、HR、HU、IT、NL、PL、PT、RO、RU、SL、SR、SV、UK。我们对数据进行处理,以删除超链接、评论和其他格式化的模板。
古腾堡和Books3[4.5%] :我们的训练数据 包括两个书体:Guten- berg项目和TheP-ile( Gao等人,2020)的Books3部分,后者是一个用于训练大型语言模型的公开可用数据集。我们在书籍层面上进行重复数据删除,删除内容重叠度超过90%的书籍。
ArXiv[2.5%] : 我们处理了arXiv的Latex文件,将科学数据添加到我们的数据集中。按照Lewkowycz等人(2022)的做法,我们删除了第一节之前的所有内容,以及书目。我们还删除了.tex文件中的注释,以及用户写的内联扩展的定义和宏,以提高不同论文的一致性。
Stack Exchange[2%] :我们包括了Stack Exchange的转储,这是一个高质量的问题和答案的网站,涵盖了从计算机科学到化学等不同的领域。我们保留了28个最大网站的数据,重新将HTML标签从文本中移出,并将答案按分数(从高到低)排序。
标记器
标记器: 我们用字节对编码(BPE)算法( Sennrich等人,2015)对数据进行标记,使用 Sentence-Piece(Kudo和Richardson,2018)中的实现。值得注意的是,我们将所有数字分割成单个数字,并回退到字节来分解未知的UTF-8字符。
总的来说,我们的整个训练数据集在标记化之后大约包含1.4T的标记。对于我们的大多数训练数据,每个标记在训练过程中只使用一次,但维基百科和图书领域除外,我们对其进行了大约两个epochs训练。
模型结构
基本还是transformer结构,主要要一下一些不同:
预归一化[GPT3] :为了提高训练的稳定性,我们对每个transformer子层的输入进行规范化,而不是对输出进行规范化。我们使用Zhang和Sennrich(2019)介绍的RMSNorm归一化函数。
SwiGLU激活函数[PaLM] :我们用SwiGLU激活函数替换ReLU的非线性,由Shazeer(2020)引入以提高性能。我们使用的维度是\(\frac{2}{3}4d\),而不是PaLM中的4d。
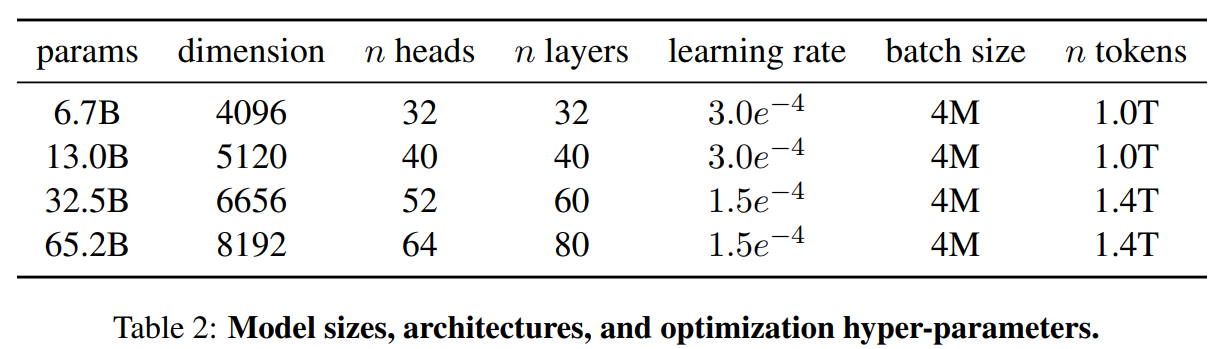
旋转嵌入[GPTNeo] :我们删除了绝对位置嵌入,取而代之的是在网络的每一层添加Su等人(2021)介绍的旋转位置嵌入(RoPE)。表2中给出了我们不同模型的超参数细节。
优化器
我们的模型使用AdamW optimizer( Loshchilov和Hutter,2017)进行训练,超参数如下:β1 = 0.9,β2 = 0.95。我们使用一个余弦学习率计划,使最终的学习率等于最大的10%。我们使用0.1的权重衰减和梯度剪裁为1.0。我们使用2,000个预热步骤,并随着模型的大小而改变学习率和批次大小(详见表2)。
高效的实现
我们进行了一些优化,以提高我们模型的训练速度。首先,我们使用causal multi-head attention,以减少内存使用和运行时间。这个实现可在xformers库中找到。这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的键/查询分数来实现的。
为了进一步提高训练效率,我们重新缩减了在后向传递过程中建议使用的激活量。更确切地说,我们保存了计算成本较高的激活,如线性层的输出。这是通过手动实现transformer层的后向函数来实现的,而不是依靠PyTorch的autograd。为了充分受益于这种优化,我们需要如Korthikanti等人(2022)所述,通过使用模 型和序列并行,减少模型的内存使用。此外,我们还尽可能地过度重视激活的计算和GPU之间通过网络的通信(由于all_reduce操作)。当训练一个65B参数的模型时,我们的代码在2048个A100GPU和80GB的内存上处理大约380个令牌/秒/GPU。 这意味着在我们包含1.4T标记的数据集上进行训练大约需要21天。
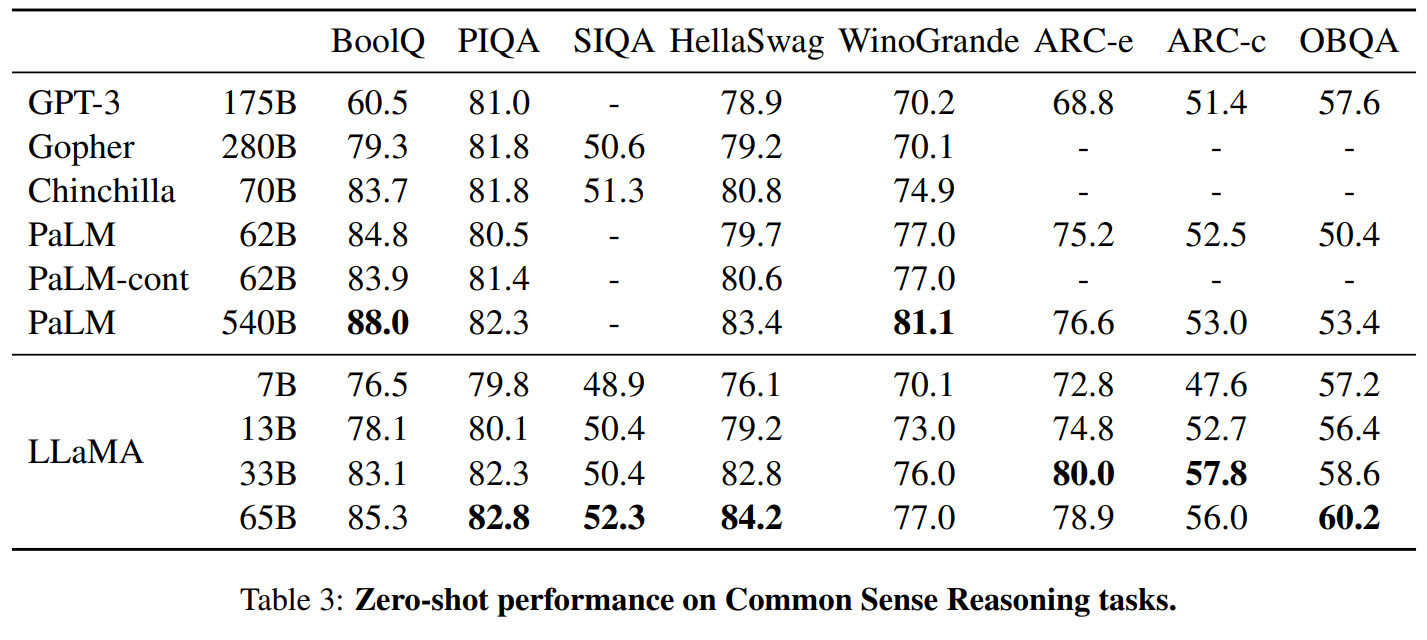
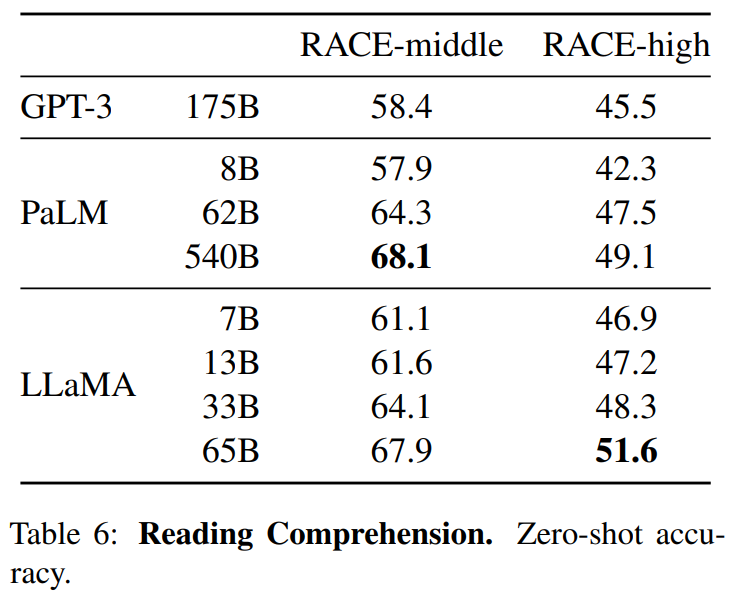
结果
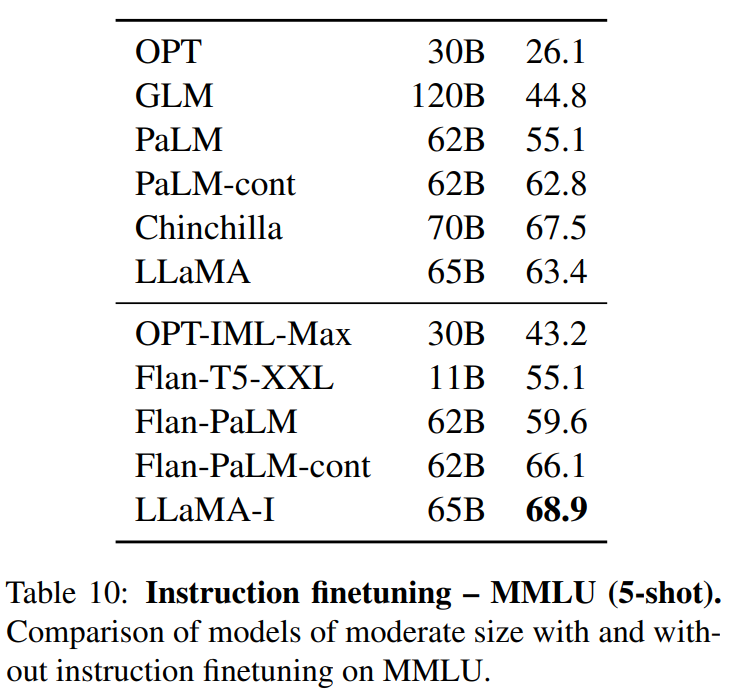
LLaMA:开放和高效的基础语言模型的更多相关文章
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- (转) 面向对象设计原则(二):开放-封闭原则(OCP)
原文:https://blog.csdn.net/tjiyu/article/details/57079927 面向对象设计原则(二):开放-封闭原则(OCP) 开放-封闭原则(Open-closed ...
- 网络对抗技术 2017-2018-2 20152515 Exp5 MSF基础应用
1.实践内容(3.5分) 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路. 1.1一个主动攻击实践,如ms08_067; (1分) MS08-067漏洞攻击 这次使用 ...
- 20155217《网络对抗》Exp05 MSF基础应用
20155217<网络对抗>Exp05 MSF基础应用 实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 一个主动攻击实践,如ms ...
- 1.tornado基础
import tornado.web ''' tornado基础web框架模块 ''' import tornado.ioloop ''' tornado的核心循环IO模块,封装了linux的epol ...
- 1.(基础)tornado初识
tornado的话就不带着大家看源码了,今后可能会介绍,目前只是看简单的用法,而且当前的tornado版本不高,其实说白了这是很久以前写的文档,但是由于格式的原因,所以打算用Markdown重写一次. ...
- Node.js知识点详解(一)基础部分
转自:http://segmentfault.com/a/1190000000728401 模块 Node.js 提供了exports 和 require 两个对象,其中 exports 是模块公开的 ...
- Go 通过 Map/Filter/ForEach 等流式 API 高效处理数据
什么是流处理 如果有 java 使用经验的同学一定会对 java8 的 Stream 赞不绝口,极大的提高了们对于集合类型数据的处理能力. int sum = widgets.stream() .fi ...
- 2014 年最热门的国人开发开源软件 TOP 100 - 开源中国社区
不知道从什么时候开始,很多一说起国产好像就非常愤慨,其实大可不必.做开源中国六年有余,这六年时间国内的开源蓬勃发展,从一开始的使用到贡献,到推出自己很多的开源软件,而且还有很多软件被国外的认可.中国是 ...
随机推荐
- 【python】第二模块 步骤一 第二课、数据库表的相关操作
第二课.数据库表的相关操作 一.课程介绍 1.1 课程介绍 学习目标 管理逻辑库和数据表 创建.删除.修改逻辑库和数据表 了解常用的数据类型和约束 字符串.整数.浮点数.精确数字.日期.枚举.主要约束 ...
- 使用fontmin,压缩字体文件,从十几M到几kb,只选择需要使用的文字
字体文件压缩fontmin,大幅压缩字体文件 快速熟练fontmin的使用,只需要在代码中配置文章中需要用到的文字,可以大幅度缩减代码大小 安装 npm install fontmin 目录结构 sr ...
- MySQL核心知识
MySQL常用的命令 启动:net start mySql; 进入:mysql -u root -p/mysql -h localhost -u root -p databaseName; 列出数据库 ...
- echarts属性大全
// 全图默认背景 // backgroundColor: 'rgba(0,0,0,0)', // 默认色板 color: ['#ff7f50','#87cefa','#da70d6','#32cd ...
- MySql 在 Linux 下的安装与基础配置
使用版本:Mysql (5.7) Linux(CentOS 7.2) 1.安装 1)下载MySQL官方的 Yum Repository wget -i -c http://dev.mysql.com/ ...
- 【Unity】阅读LuaFramework_UGUI的一种方法
写在前面 我第一次接触到LuaFramework_UGUI是在一个工作项目中,当时也是第一次知道toLua.但我刚开始了解LuaFramework_UGUI时十分混乱,甚至将LuaFramework_ ...
- vs2013安装完VASSISTX助手之后字体变成斜体如何解决?
VC助手为最新版本. 1. 打开vc助手选项 2. 取消勾选"show stable symbols in italics"
- K8S—dashboard ui部署
一.Dashboard UI概述 仪表板是基于Web的Kubernetes用户界面.您可以使用仪表板将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,并管理集群本身及其伴随 ...
- UIPath踩坑记一UIpath中抓取数据后在tableau中无表头
UIpath抓取数据存在Excel中(Excel 应用程序范围),且已设置表头,但是放到tableau中无表头 更换为"写入范围(工作簿)",同时属性设置必须勾选"添加标 ...
- 西电oj245 成绩统计 结构体数组使用
#include<stdio.h> struct student{ //定义一个结构体数组 int num; char name[11]; float g1; float g2; floa ...