【kafka】JDBC source&sink connect实现数据从Oracle实时同步插入更新到PostgreSQL(PG)
〇、所需资料
1、JDBC connect的plugins下载地址(confluent)
一、Oracle建表
1、表规划
表名:Test_TimeFormat_Order、Test_Stress_Order
字段:INCREMENT_UID/Order_ID/quantity/cost/CREATE_DATE/UPDDATTIM_0
2、建表语句
-- 建表语句
CREATE TABLE "TEST"."Test_TimeFormat_Order"(
"INCREMENT_UID" INTEGER NOT NULL,
"Order_ID" VARCHAR2(255) NOT NULL,
"quantity" INTEGER DEFAULT 0 NOT NULL,
"cost" NUMBER(11,2) DEFAULT 0.99 NOT NULL,
"CREATE_DATE" TIMESTAMP (2) DEFAULT SYSDATE NOT NULL,
"UPDDATTIM_0" TIMESTAMP (2) DEFAULT SYSDATE NOT NULL
);
-- 建自增序列
create sequence test.test_seq_Test_Stress_Order increment by 1 start with 1
minvalue 1 maxvalue 9999999999999 nocache;
-- 创建触发器,将自增序列的值插入
create or replace trigger test.Auto_Trig_Test_TimeFormat_Order
before insert on "TEST"."Test_TimeFormat_Order"
for each row
begin
select test.test_seq_Test_TimeFormat_Order.Nextval into:new.INCREMENT_UID from dual;
end;
-- 问题:Oracle序列如何归零3、插入数据
-- 全字段
INSERT INTO "TEST"."Test_TimeFormat_Order"("INCREMENT_UID", "Order_ID", "quantity", "cost", "CREATE_DATE", "UPDDATTIM_0") VALUES ('1', 'SO001', '2', '1.99', TO_TIMESTAMP('2022-09-08 20:19:41.00', 'SYYYY-MM-DD HH24:MI:SS:FF2'), TO_TIMESTAMP('2022-09-08 20:19:44.00', 'SYYYY-MM-DD HH24:MI:SS:FF2'));
-- 最简化
INSERT INTO "TEST"."Test_TimeFormat_Order"("Order_ID") VALUES ('SO001')4、更新数据
-- 全字段更新
UPDATE "TEST"."Test_TimeFormat_Order" SET "INCREMENT_UID" = '1', "Order_ID" = 'SO001', "quantity" = '2', "cost" = '1.99', "CREATE_DATE" = TO_TIMESTAMP('2022-09-08 20:19:41.00', 'SYYYY-MM-DD HH24:MI:SS:FF2'), "UPDDATTIM_0" = TO_TIMESTAMP('2022-09-08 20:19:44.00', 'SYYYY-MM-DD HH24:MI:SS:FF2') WHERE "INCREMENT_UID" = '1' AND "Order_ID" = 'SO001' AND "quantity" = '2' AND "cost" = '1.99' AND "CREATE_DATE" = '2022-09-08 20:19:41.00' AND "UPDDATTIM_0" = '2022-09-08 20:19:44.00';
-- 单字段更新(只更新时间戳列)
UPDATE "TEST"."Test_TimeFormat_Order" SET "UPDDATTIM_0" = TO_TIMESTAMP('2022-09-08 20:19:44.00', 'SYYYY-MM-DD HH24:MI:SS:FF2') WHERE "Order_ID" = 'SO001';二、建source connector
PUT 192.168.0.1:8083/connectors/sink_connector_Test_TimeFormat_Order/config
{
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"mode": "timestamp",
"timestamp.column.name": "UPDDATTIM_0",
"topic.prefix": "connector_topic_",
"connection.password": "system",
"connection.user": "system",
"db.timezone": "Asia/Shanghai",
"name": "source_connector_Test_TimeFormat_Order",
"connection.url": "jdbc:oracle:thin:@//192.168.0.1:1521/helowin",
"table.whitelist": "TEST.Test_TimeFormat_Order"
}三、建sink connector
PUT 192.168.0.2:8083/connectors/sink_connector_Test_TimeFormat_Order/config
{
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"table.name.format": "ljh.Test_TimeFormat_Order",
"connection.password": "QAZ123",
"tasks.max": "1",
"topics": "connector_topic_Test_TimeFormat_Order",
"delete.enabled": "false",
"auto.evolve": "true",
"connection.user": "postgres",
"name": "sink_connector_Test_TimeFormat_Order",
"auto.create": "true",
"connection.url": "jdbc:postgresql://192.168.0.2:5432/bigdata",
"insert.mode": "upsert",
"pk.mode": "record_value",
"pk.fields": "Order_ID"
}四、用到的命令
1、启停zk、kafka、connect
kafka:nohup bin/kafka-server-start.sh config/server.properties > nohup_kafka_log.txt 2>&1 &
bin/kafka-server-stop.sh
zookeeper:nohup bin/zookeeper-server-start.sh -daemon config/zookeeper.properties > nohup_zookeeper_log.txt 2>&1 &
bin/zookeeper-server-stop.sh
nohup bin/connect-distributed.sh config/connect-distributed.properties > nohup_connect_log.txt 2>&1 &
kill pid
2、查看状态
sudo /usr/local/jdk1.8.0_291/bin/jps
tail -f nohup_zookeeper.log
3、topic相关
查看topic列表: bin/kafka-topics.sh --bootstrap-server big04:9092,big05:9092,big07:9092 --list
新建topic:bin/kafka-topics.sh --bootstrap-server big04:9092,big05:9092,big07:9092 --create --replication-factor 1 --partitions 1 --topic first
查看topic详细信息:kafka-topics.sh --describe --bootstrap-server big04:9092,big05:9092,big07:9092 --topic first
删除topic:bin/kafka-topics.sh --bootstrap-server big04:9092,big05:9092,big07:9092 --delete --topic first
生产:bin/kafka-console-producer.sh --broker-list big04:9092,big05:9092,big07:9092 --topic first
消费:bin/kafka-console-consumer.sh --bootstrap-server big04:9092,big05:9092,big07:9092 --topic connector_topic_0908_MFGITM_0908
从头消费:bin/kafka-console-consumer.sh --topic connector_topic_bak_MFGITM --from-beginning --bootstrap-server big04:9092,big05:9092,big07:9092
4、connect命令
查询全部connector:GET http://192.168.0.2:8083/connectors
查询可用的插件:GET 192.168.0.2:8083/connector-plugins
查询具体connector:GET 192.168.0.2:8083/connectors/source_connector_docker_oracle_MFGITM_bak/config(status)
新增或修改connector:PUT 192.168.0.2:8083/connectors/sink_connector_Test_TimeFormat_Order/config
新增connector:POST 192.168.0.2:8083/connectors
五、验证
1、Oracle插入数据
(1)插入新纪录

(2)修改记录

2、消费者监听topic
(1)查看创建的topic

(2)从头消费topic

(3)新增数据后

(4)修改数据后
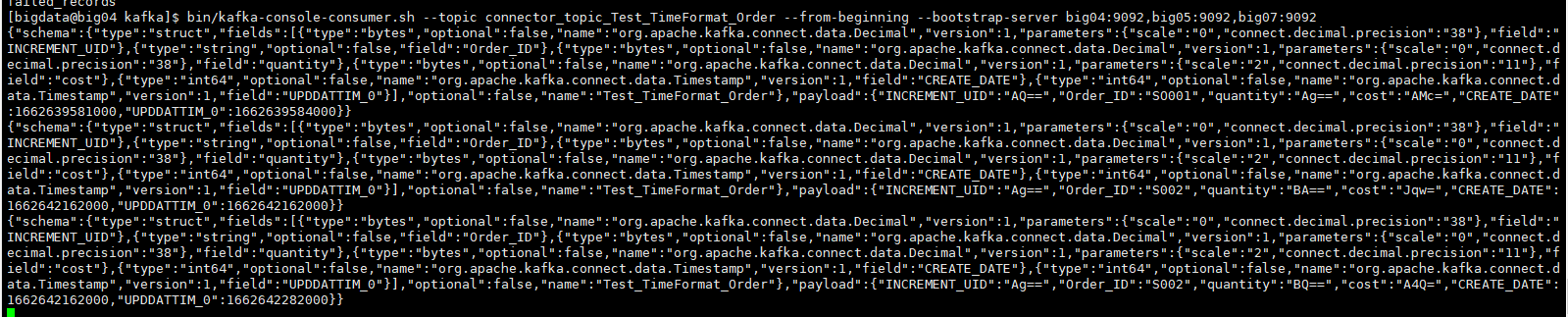
3、pg端查看插入的数据
(1)插入数据后
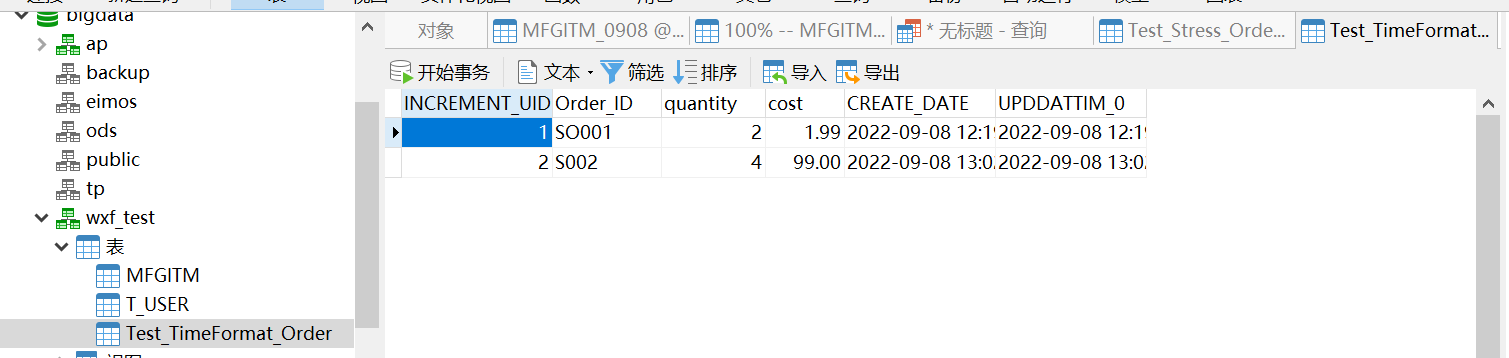
(2)修改数据后

【kafka】JDBC source&sink connect实现数据从Oracle实时同步插入更新到PostgreSQL(PG)的更多相关文章
- 真正的原生JS数据双向绑定(实时同步)
真正的原生JS数据双向绑定(实时同步) 接触过vue之后我感觉数据双向绑定实在是太好用了,然后就想着到底是什么原理,今天在简书上看到了一位老师的文章 js实现数据双向绑定 然后写出了我自己的代码 wi ...
- ORACLE no1 存储过程插入更新表数据
CREATE OR REPLACE PROCEDURE sp_cust_main_data_yx(InStrDate IN VARCHAR2, ...
- goldengate 12.3 实现mysql数据及DDL实时同步
以下环境在mysql 5.7上完成. set mysql_home=mysql安装路径 set path=%mysql_home%\bin;%path% 首先要准备mysql的启动,可参考:http: ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 同步、更新、下载Android Source & SDK from 国内镜像站(转载)
同步.更新.下载Android Source & SDK from 国内镜像站 转自: 同步.更新.下载Android Source & SDK from 国内镜像站 Download ...
- 基于nodejs将mongodb的数据实时同步到elasticsearch
一.前言 因公司需要选用elasticsearch做全文检索,持久化存储选用的是mongodb,但是希望mongodb里面的数据发生改变可以实时同步到elasticsearch上,一开始主要使用ela ...
- 泛函编程(36)-泛函Stream IO:IO数据源-IO Source & Sink
上期我们讨论了IO处理过程:Process[I,O].我们说Process就像电视信号盒子一样有输入端和输出端两头.Process之间可以用一个Process的输出端与另一个Process的输入端连接 ...
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- C++操作Kafka使用Protobuf进行跨语言数据交互
C++操作Kafka使用Protobuf进行跨语言数据交互 Kafka 是一种分布式的,基于发布 / 订阅的消息系统.主要设计目标如下: 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 T ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
随机推荐
- 微服务系列之授权认证(二) identity server 4
1.简介 IdentityServer4 是为ASP.NET Core系列量身打造的一款基于 OpenID Connect 和 OAuth 2.0 认证授权框架. 官方文档:https://ident ...
- containerd使用总结
# 安装 yum install -y yum-utils yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linu ...
- Kubernetes 日志:日志收集架构
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的.而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中.对于容器化应用 ...
- Grafana 入门知识介绍
通过[Configuration]>[Plugins]添加插件 通过[Configuration]>[Data Sources]添加数据源(分析对象) 通过[Server Admin]&g ...
- GTID主从
GTID主从 目录 GTID主从 GTID概念介绍 GTID工作原理 GTID主从配置 GTID概念介绍 GTID即全局事务ID (global transaction identifier), 其保 ...
- 2.ElasticSearch系列之集群权限认证
1. 在master节点上创建秘钥库 export ES_PATH_CONF="/home/elasticsearch/config" && /usr/local/ ...
- 《吐血整理》高级系列教程-吃透Fiddler抓包教程(30)-Fiddler如何抓取Android7.0以上的Https包-番外篇
1.简介 通过宏哥前边几篇文章的讲解和介绍想必大家都知道android7.0以上,有android的机制不在信任用户证书,导致https协议无法抓包.除非把证书装在系统信任的证书里,此时手机需要roo ...
- 解决办法:ImportError:'module'object has no attribute 'check specifier'
在安装envsubst命令不存在的报错, 安装centos本地源, 再安装gettext) 在指定版本的时候发现还是报错根据后面提示指定44.0.0问题解决 pip install --upgrade ...
- 【保姆教程】RuoYi-Radius搭建实现portal认证
[保姆教程]RuoYi-Radius搭建实现portal认证 一.简介 以若依后台管理框架V4.6.0做为基础框架,实现了ToughRADIUS大部分功能,支持标准RADIUS协议(RFC 2865, ...
- 从 QFramework 重新开始
自从上一篇博文写完后,就进入了繁忙工作状态,直到最近才开始有一点空闲时间. 这次繁忙的状态从 2022 年 10 月 11 日 持续到 2022 年 11 月 5 日. 主要的工作就是 QFramew ...