scrapy 之自定义命令运行所有爬虫文件
1、在spider文件夹同级目录创建commands python包
2、在包下创建command.py文件
3、从scrapy.commands包下引入ScrapyCommand
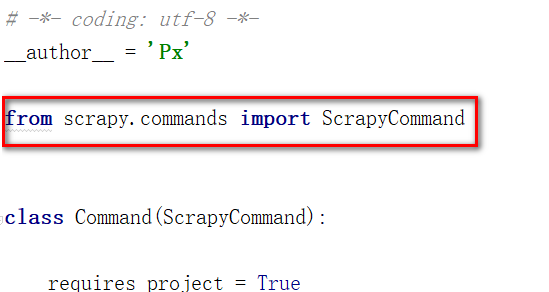
4、创建一个类,继承ScrapyCommand
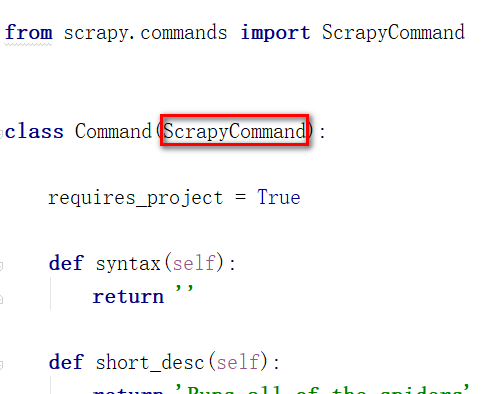
5、重新定义类变量 requires_project = True

6、重写syntax short_desc方法,syntax返回空字符串 short_desc返回描述字符串

7、重写run方法。
8、在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list() #通过self.crawler_process.spider.list()获得所有爬虫
for name in spider_list: #遍历所有爬虫
self.crawler_process.crawl(name, **opts.__dict__) #运行爬虫 self.crawler_process.start() #启动进程
crawler_process 来自父类 完整代码
# -*- coding: utf-8 -*-
__author__ = 'Px' from scrapy.commands import ScrapyCommand class Command(ScrapyCommand): requires_project = True def syntax(self):
return '' def short_desc(self):
return 'Runs all of the spiders' def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
scrapy 之自定义命令运行所有爬虫文件的更多相关文章
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- Scrapy的shell命令(转)
scrapy python MrZONT 2015年08月29日发布 ...
- scrapy框架--新建调试的main.py文件
一.原因: 由于pycharm中没有scrapy的一个模板,所有没办法直接在scrapy文件中调试,所有我们需要写一个自己的main.py文件,在文件里面调用命令行,来实现scrapy的一个调试.(在 ...
- scrapy框架的命令行解释
scrapy框架的命令解释 创建爬虫项目 scrapy startproject 项目名例子如下: scrapy startproject test1 这个时候爬虫的目录结构就已经创建完成了,目录结构 ...
- python+pytest,通过自定义命令行参数,实现浏览器兼容性跑用例
场景拓展: UI自动化可能需要指定浏览器进行测试,为了做成自定义配置浏览器,可以通过动态添加pytest的命令行参数,在执行的时候,获取命令行传入的参数,在对应的浏览器执行用例. 1.自动化用例需要支 ...
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- scrapy 基础组件专题(六):自定义命令
写好自己的爬虫项目之后,可以自己定制爬虫运行的命令. 一.单爬虫 在项目的根目录下新建一个py文件,如命名为start.py,写入如下代码: from scrapy.cmdline import ex ...
随机推荐
- 简单的爬虫爬的完整的<img>标签,修改正则即可修改爬取内容
简单的爬虫爬的完整的<img>标签,生成<img>标签结果文件与爬虫经历的网页. <?php/** 从给定的url获取html内容** */function _getUr ...
- Ajax异步请求阻塞情况的解决办法(asp.net MVC Session锁的问题)
讨论今天这个问题之前,我们先来看下浏览器公布的资源并发数限制个数,如下图 不难看出,目前主流浏览器支持都是最多6个并发 需要注意的是,浏览器的并发请求数目限制是针对同一域名的 意即,同一时间针对同一域 ...
- 在线学习在CTR上应用的综述
参考:https://mp.weixin.qq.com/s/p10_OVVmlcc1dGHNsYMQwA 在线学习只是一个机器学习的范式(paradigm),并不局限于特定的问题,模型或者算法. 架构 ...
- JUnit报告美化——ExtentReports
美化后效果 美化后的报告,页面清晰简洁.重要信息都可以体现出来,用例通过率,失败的用例和失败原因 主要技术点 ExtentReports JUnit的@Rule 重写TestWatcher的succe ...
- centos 6.5 安装redis
1. 下载redis,编译安装 下载地址:https://redis.io/download(建议大家都选择稳定版本) 下载到本地,然后上传到集群 当然也可以通过命令行直接在线下载 $ wget ht ...
- Odoo二次开发
Odoo 点击进入
- memory_profiler的使用
作用:memory_profiler是用来分析每行代码的内存使用情况 使用方法一: 1.在函数前添加 @profile 2.运行方式: python -m memory_profiler memory ...
- 羊车门问题(Python)
羊车门问题(结对作业) 在完成本题之前,请仔细阅读下面内容: 题目描述:有3扇关闭的门,一扇门后面停着汽车,其余门后是山羊,只有主持人知道每扇门后面是什么.参赛者可以选择一扇门,在开启它之前,主持人会 ...
- 去掉点击a标签时产生的虚线框
1.直接给a 标签添加属性:onfocus="this.blur()" 即可 For Example: <a onfocus="this.blur()" ...
- post提交参数过多时,取消Tomcat对 post长度限制
1.Tomcat 默认的post参数的最大大小为2M, 当超过时将会出错,可以配置maxPostSize参数来改变大小. 从 apache-tomcat-7.0.63 开始,参数 maxPostSiz ...