jmeter 参数化5_Count 计数器
如果需要引用的数据量较大,且要求不能重复或者需要自增,那么可以使用计数器来实现。
计数器(counter):允许用户创建一个在线程组之内都可以被引用的计数器。
计数器允许用户配置一个起点,一个最大值,增量数,循环到最大值,然后重新开始,继续这样,直到测试结束。计数器使用long存储的值,所取的范围是2^63——2^63-1.
- 添加计数器
2、参数说明
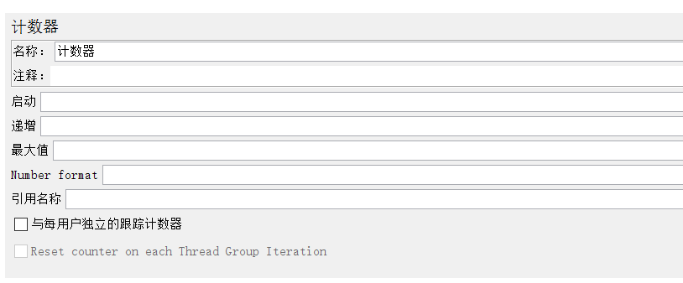
启动(start):给定计数器的起始值、初始值,第一次迭代时,会把该值赋给计数器
PS:英文版是Start,Jmeter的中文语言将Start翻译成了“启动”,有些歧义
递增(Increment):每次迭代后,给计数器增加的值
最大值(Maximum):计数器的最大值,如果超过最大值,重新设置为初始值(Start),默认的最大值为Long.MAX_VALUE,2^63-1(如果持续压测,建议最好不要设置最大值)
Number format:可选格式,比如000,格式化为001,002;默认格式为Long.toString(),但是默认格式下,还是可以当作数字使用
引用名称(Reference Name):用于控制在其它元素中引用该值,形式:$(reference_name}
与每用户独立的跟踪计数器(Track Counter Independently for each User):全局的计数器,如果不勾选,即全局的,比如用户#1 获取值为1,用户#2获取值还是为1;
如果勾选,即独立的,则每个用户有自己的值:比如用户#1 获取值为1,用户#2获取值为2。
每次迭代复原计数器(Reset counter on each Thread Group Iteration):可选,仅勾选与每用户独立的跟踪计数器时可用;
如果勾选,则每次线程组迭代,都会重置计数器的值,当线程组是在一个循环控制器内时比较有用。
3、引用



jmeter 参数化5_Count 计数器的更多相关文章
- jmeter参数化之函数助手(十五)
jmeter-参数化: 参数化的作用:调用接口入参时.有时要求参数经常变化,如果每次去修改就会变得很繁琐,这时候就需要把经常变化的值改变为提前编辑好的文档或函数中,便于调用时使用不同的值. Jmete ...
- JMeter参数化(一)
JMeter参数化的4种方法:
- 性能测试——jmeter环境搭建,录制脚本,jmeter参数化CSV
一.Jmeter+jdk环境搭建 1.http://www.oracle.com/technetwork/java/javase/downloads/index.html,下载jdk. 直接安装就行了 ...
- Jmeter 参数化请求实例
Jmeter 参数化请求实例 在jmeter中的请求可以参数化,其中参数化的方式有4种: 1.CSV Data Set Config 2.数据库 3.用户自定义变量 4.用jmeter中的函数获取参数 ...
- Jmeter参数化的方法
测试接口时,使用Jmeter在请求中输入参数,若是有多种情况,有多条测试参数,是不是要每个情况逐条输入呢?逐条输入会让人觉得比较麻烦,因此,就有了Jmeter参数化. Jmeter参数化的方法: 用户 ...
- jmeter参数化读取数据进行多次运行
jmeter参数化数据,可以使用csv,还可以使用数据库的方式 1.使用csv读取数据 在线程组中,配置原件中,选择csv data set config 1.本地创建了16个数据,存为test.tx ...
- Jmeter 参数化之 CSV Data Set Config 循环读取参数
对于做接口和性能测试,个人感觉Jmeter是一个非常方便易学的工具,今天随笔记录Jmeter 参数化之 CSV Data Set Config. 首先在开始记录之前,先搞明白2个问题 1.什么是参数化 ...
- Jmeter参数化-CSV Data Set Config
前言 一般来说,我们使用Jmeter来模拟HTTP请求时,比如模拟查询学生信息,我们通常把查询接口的入参(如学生姓名)写在HTTP请求中.当只需要查询1个学生的信息时,我们可以把这名学生的姓名准确的写 ...
- Jmeter参数化、检查点、集合点教程
在使用Jemeter做压力测试的时候,往往需要参数化用户名,密码以到达到多用户使用不同的用户名密码登录的目的,这个时候我们就可以使用参数化登录. 一.badboy录制需要的脚本.也可以用fiddler ...
随机推荐
- kibana使用日志时间进行排序
kibana默认的是按照客户端的采集时间(@timestamp)进行排序,这往往不是我们所需要的,我们需要的是对日志实际时间进行排序,要解决这个问题,有很多种方法,可以在elasticsearch建立 ...
- php linux环境安装ftp扩展
1.进入PHP安装源码包,找到ext下的ftp,进入 cd /home/local/php-5.6.25/ext/ftp 2./usr/local/php/bin/phpize 3../configu ...
- 【HDOJ6699】Block Breaker(模拟)
题意:给定一个n*m的网格块,如果一个块水平或垂直方向没有相邻支撑就会掉下去 有q次询问,每次会掉下去一块,问连锁反应新掉下的块数 n,m<=2e3,q<=1e5 思路: #include ...
- 【CF1244D】Paint the Tree(树形DP,树)
题意: n<=1e5,1<=a[i][j]<=1e9 思路: 不是很懂INF为什么要开到1e15,我觉得只要1e14就好 #include<bits/stdc++.h> ...
- 【2019 Multi-University Training Contest 6】
01: 02:https://www.cnblogs.com/myx12345/p/11650764.html 03: 04: 05:https://www.cnblogs.com/myx12345/ ...
- linux之rpm软件包管理
1.RPM包的命名规则 例如:httpd-2.2.15-15.el6.centos.1.i686.rpm httpd · 软件包名 2.2.15 软件版本 15 ...
- Shell中uname命令查看系统内核、版本
uname命令 描述 用于打印内核名称和版本.主机名等系统信息. 用法 uname [OPTION]... 参数 用法 -a print all information -s print th ...
- python实现基于两张图片生成圆角图标效果的方法
python实现基于两张图片生成圆角图标效果的方法 这篇文章主要介绍了python实现基于两张图片生成圆角图标效果的方法,实例分析了Python使用pil模块进行图片处理的技巧,分享给大家供大家参考. ...
- ASP.NET MVC Filter过滤机制(过滤器、拦截器)
https://blog.csdn.net/knqiufan/article/details/82413885 本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/ ...
- Bootstrap 学习笔记4 巨幕页头略缩图警告框