Python-爬虫-针对有frame框架的页面
有的页面会使用frame 框架,使用Selenium + PhantomJS 后并不会加载iframe 框架中的网页内容。iframe 框架相当于在页面中又加载了一个页面,需要使用Selenium 的 switch_to.frame() 方法加载
(官网给的方法是switch_to_frame(),但是IDE提醒使用前面的方法替代该方法)。
比如:
driver.switch_to.frame('g_iframe')
一、介绍
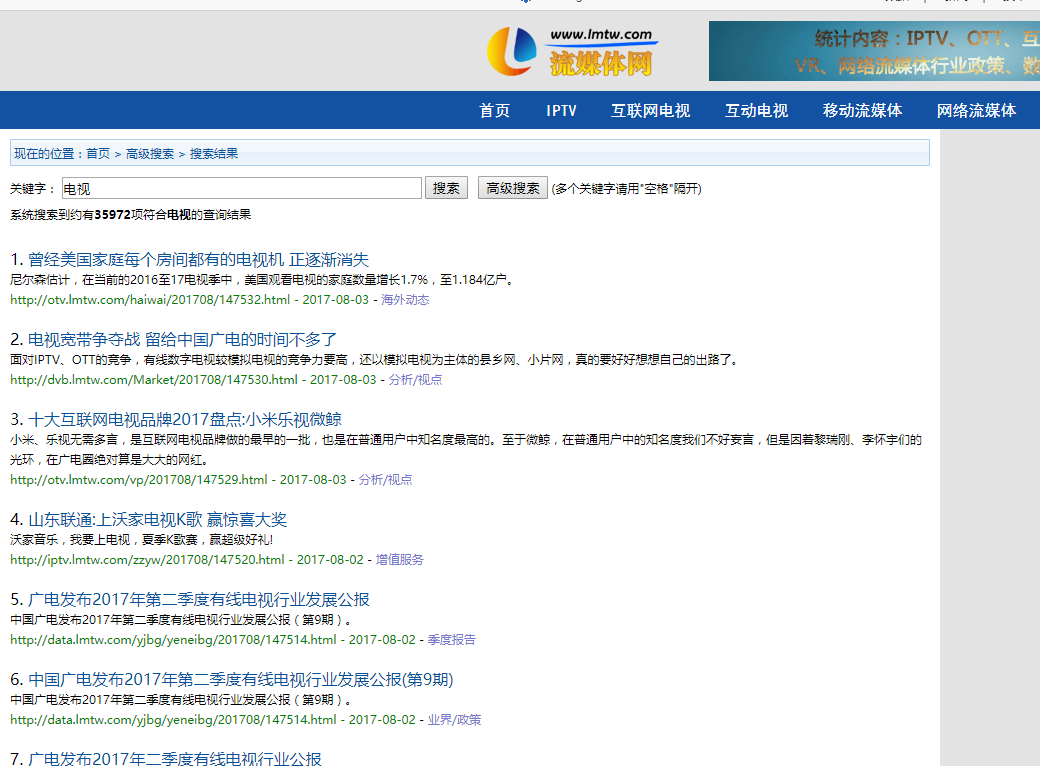
本例子用Selenium +phantomjs爬取流媒体(http://www.lmtw.com/search.php?show=title%2Ckeyboard%2Cwriter&searchget=1&keyboard=%E7%94%B5%E8%A7%86)的资讯信息,输入给定关键字抓取资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
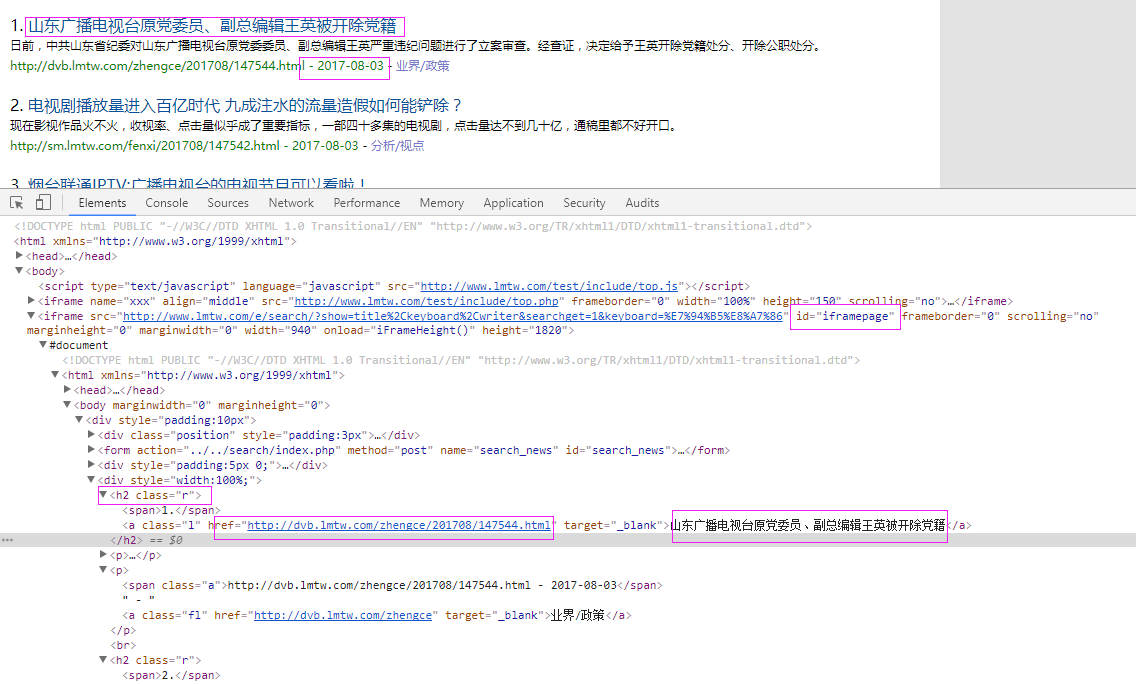
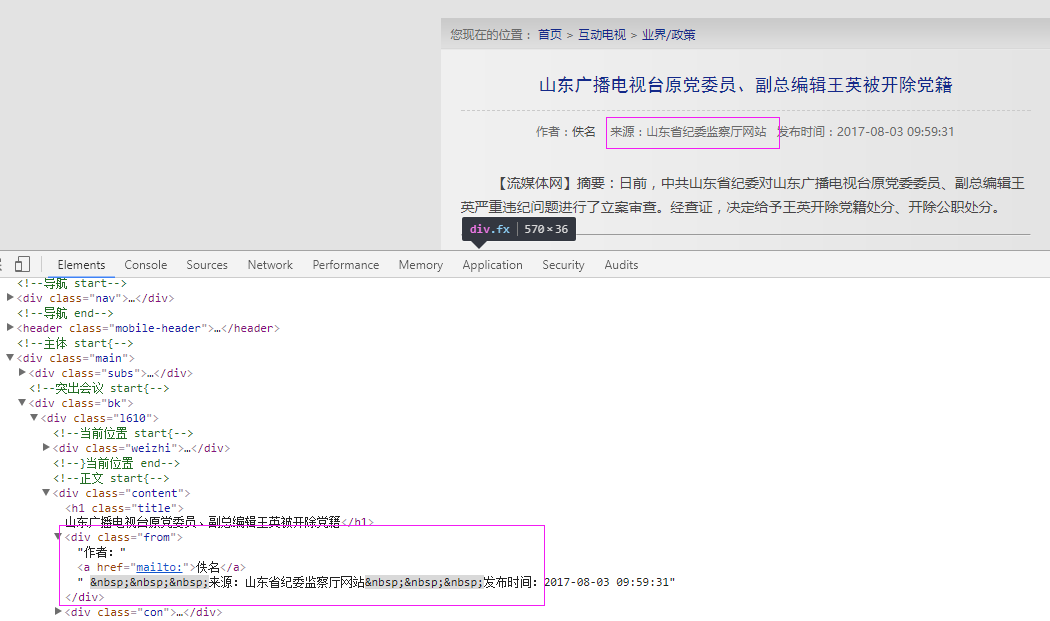
二、网站信息
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('h2[class="r"]')
2、抓取标题
抓取代码:title = element.find('a').text().encode('utf8').strip()
3、抓取链接
抓取代码:url = element.find('a').attr('href')
4、抓取日期
抓取代码:dateElements = doc('span[class="a"]')
5、抓取来源
抓取代码:strSources = dochtml('div[class="from"]').text().encode('utf8').strip()
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
import datetime
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib
class lmtwSpider(object):
def __init__(self,driver,log,keyword_list,websearch_url,valid,filter):
''' :param driver: 驱动
:param log: 日志
:param keyword_list: 关键字列表
:param websearch_url: 搜索网址
:param valid: 采集参数 0:采集当天;1:采集昨天
:param filter: 过滤项,下面这些内容如果出现在资讯标题中,那么这些内容不要,过滤掉
'''
self.log = log
self.driver = driver self.webSearchUrl_list = websearch_url.split(';')
self.keyword_list = keyword_list
self.db = mongoDB.mongoDbBase()
self.valid = valid self.start_urls = []
# 过滤项
self.filter = filter for keyword in keyword_list:
url = websearch_url + urllib.quote(keyword)
self.start_urls.append(url) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: '2017-06-20 10:22 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText) if len(strDate) == 1:
if self.valid == 0 and self.Comapre_to_days(currentDate, strDate[0])==0:
return True, currentDate
elif self.valid == 1 and self.Comapre_to_days(currentDate, strDate[0])==1:
return True,str(datetime.datetime.now() - datetime.timedelta(days=1))[0:10]
elif self.valid == 2 and self.Comapre_to_days(currentDate, strDate[0]) == 2:
return True,str(datetime.datetime.now() - datetime.timedelta(days=2))[0:10]
return False, '' def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self):
try:
strsplit = '------------------------------------------------------------------------------------'
# isbreak = False
keywordIndex = 0
for link in self.start_urls:
self.driver.get(link)
self.driver.switch_to.frame('iframepage')
keyword = self.keyword_list[keywordIndex]
keywordIndex += 1 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = [] self.log.WriteLog(strsplit)
self.log_print(strsplit)
Elements = doc('h2[class="r"]')
dateElements = doc('span[class="a"]')
index = 0
for element in Elements.items():
date = dateElements[index].text
index += 1
flag,strDate = self.date_isValid(date)
if flag:
title = element.find('a').text().encode('utf8').strip() # 考虑过滤项
if title.find(self.filter)>-1:
continue
if title.find(keyword) > -1:
url = element.find('a').attr('href')
dictM = {'title': title, 'date': strDate,
'url': url, 'keyword': keyword, 'introduction': title}
infoList.append(dictM)
if len(infoList) > 0:
for item in infoList:
item['sourceType']=1
url = item['url']
self.driver.get(url)
# self.driver.switch_to.frame('iframepage')
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
strSources = dochtml('div[class="from"]').text().encode('utf8').strip()
txtsource = strSources[strSources.find('来源:') + 9:]
item['source']=txtsource[0:txtsource.find(' ')] self.log.WriteLog('title:%s' % item['title'])
self.log.WriteLog('url:%s' % item['url'])
self.log.WriteLog('date:%s' % item['date'])
self.log.WriteLog('source:%s' % item['source'])
self.log.WriteLog('kword:%s' % item['keyword'])
self.log.WriteLog(strsplit) self.log_print('title:%s' % item['title'])
self.log_print('url:%s' % item['url'])
self.log_print('date:%s' % item['date'])
self.log_print('source:%s' % item['source'])
self.log_print('kword:%s' % item['keyword'])
self.log_print(strsplit)
self.db.SaveInformations(infoList)
except Exception,e:
self.log.WriteLog('lmtwSpider:'+ e.message)
finally:
pass
Python-爬虫-针对有frame框架的页面的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- js实现frame框架部分页面的刷新
一.先来看一个简单的例子: 下面以三个页面分别命名为frame.html.top.html.bottom.html为例来具体说明如何做. frame.html 由上(top.html)下(bottom ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
随机推荐
- BZOJ1233 [Usaco2009Open]干草堆tower 【单调队列优化dp】
题目链接 BZOJ1233 题解 有一个贪心策略:同样的干草集合,底长小的一定不比底长大的矮 设\(f[i]\)表示\(i...N\)形成的干草堆的最小底长,同时用\(g[i]\)记录此时的高度 那么 ...
- 图表绘制工具--Matplotlib 1
''' [课程3.] Matplotlib简介及图表窗口 Matplotlib → 一个python版的matlab绘图接口,以2D为主,支持python.numpy.pandas基本数据结构,运营高 ...
- mysql服务性能优化—my.cnf_my.ini配置说明详解(16G内存)
这配置已经优化的不错了,如果你的mysql没有什么特殊情况的话,可以直接使用该配置参数 MYSQL服务器my.cnf配置文档详解硬件:内存16G [client]port = 3306socket = ...
- Video for Linux Two API Specification revision0.24【转】
转自:http://blog.csdn.net/jmq_0000/article/details/7536805#t136 Video for Linux Two API Specification ...
- 使用函数方式生成UUID
1.默认生成的UUID是有 “-” 分隔符的 例如: public static void main(String[] args){ String uuid = UUID.randomUUID().t ...
- 使用Sublime Text 3 编写python
1,下载Sublime Text 3 链接:http://pan.baidu.com/s/1eROBpB0 密码:cqjr 2,安装 注意安装时去掉捆绑的软件安装选项,有两处. 3,安装完成打开软件, ...
- 最近看点JAVA
这本的书名:<求精要决:JAVA EE编程开发安全精解> 请得很懂 试一下servlet代码: <!DOCTYPE html> <html> <head> ...
- react className的2种变量写法
ES6新增的不少语法都是极好用的, 在拼接变量与字符串时,模版字符串``就是典型的用法 以下是2种写法 <div className={"bubble-box" +' '+` ...
- Codeforces 954I Yet Another String Matching Problem(并查集 + FFT)
题目链接 Educational Codeforces Round 40 Problem I 题意 定义两个长度相等的字符串之间的距离为: 把两个字符串中所有同一种字符变成另外一种,使得两个 ...
- spark-groupByKey
一般来说,在执行shuffle类的算子的时候,比如groupByKey.reduceByKey.join等. 其实算子内部都会隐式地创建几个RDD出来.那些隐式创建的RDD,主要是作为这个操作的一些中 ...