Pytorch多GPU并行处理
- 可以参数2017coco detection 旷视冠军MegDet: MegDet 与 Synchronized BatchNorm
- PyTorch-Encoding官方文档对CGBN(cross gpu bn)实现
- GPU捉襟见肘还想训练大批量模型?
- 在一个或多个 GPU 上训练大批量模型: 梯度累积
- 充分利用多 GPU 机器:torch.nn.DataParallel
- 多 GPU 机器上的均衡负载 : PyTorch-Encoding 的 PyTorch 包,包括两个模块:DataParallelModel 和 DataParallelCriterion
- 分布式训练:在多台机器上训练: PyTorch 的 DistributedDataParallel
- Pytorch 的多 GPU 处理接口是
torch.nn.DataParallel(module, device_ids),其中module参数是所要执行的模型,而device_ids则是指定并行的 GPU id 列表。 - 而其并行处理机制是,首先将模型加载到主 GPU 上,然后再将模型复制到各个指定的从 GPU 中,然后将输入数据按 batch 维度进行划分,具体来说就是每个 GPU 分配到的数据 batch 数量是总输入数据的 batch 除以指定 GPU 个数。每个 GPU 将针对各自的输入数据独立进行 forward 计算,最后将各个 GPU 的 loss 进行求和,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,这样就完成了一次迭代计算。所以该接口还要求输入数据的 batch 数量要不小于所指定的 GPU 数量。

这里有两点需要注意:
- 主 GPU 默认情况下是 0 号 GPU,也可以通过
torch.cuda.set_device(id)来手动更改默认 GPU。 - 提供的多 GPU 并行列表中需要包含有主 GPU
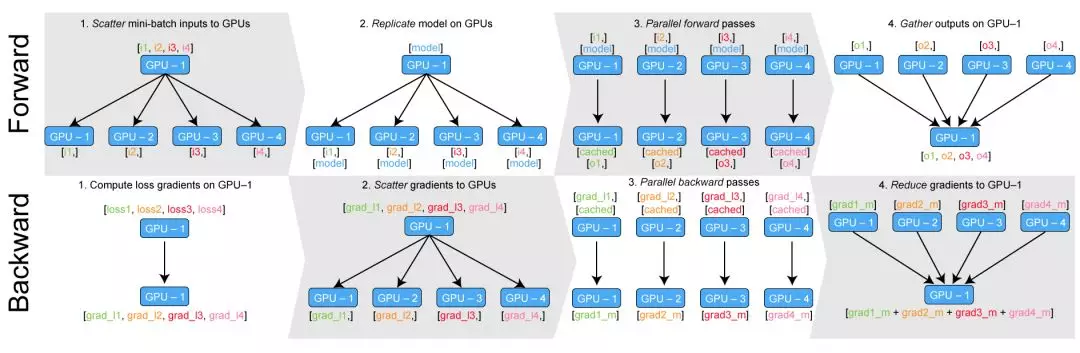
但是,DataParallel 有一个问题:GPU 使用不均衡。在一些设置下,GPU-1 会比其他 GPU 使用率高得多。
Pytorch多GPU并行处理的更多相关文章
- Pytorch 多 GPU 并行处理机制
Pytorch 的多 GPU 处理接口是 torch.nn.DataParallel(module, device_ids),其中 module 参数是所要执行的模型,而 device_ids 则是指 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- pytorch 多GPU训练总结(DataParallel的使用)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_40087578/artic ...
- Pytorch指定GPU的方法总结
Pytorch指定GPU的方法 改变系统变量 改变系统环境变量仅使目标显卡,编辑 .bashrc文件,添加系统变量 export CUDA_VISIBLE_DEVICES=0 #这里是要使用的GPU编 ...
- Ubuntu下安装pytorch(GPU版)
我这里主要参考了:https://blog.csdn.net/yimingsilence/article/details/79631567 并根据自己在安装中遇到的情况做了一些改动. 先说明一下我的U ...
- [转] pytorch指定GPU
查过好几次这个命令,总是忘,转一篇mark一下吧 转自:http://www.cnblogs.com/darkknightzh/p/6836568.html PyTorch默认使用从0开始的GPU,如 ...
- pytorch 多GPU处理过程
多GPU的处理机制: 使用多GPU时,pytorch的处理逻辑是: 1.在各个GPU上初始化模型. 2.前向传播时,把batch分配到各个GPU上进行计算. 3.得到的输出在主GPU上进行汇总,计算l ...
- Pytorch使用GPU
pytorch如何使用GPU在本文中,我将介绍简单如何使用GPU pytorch是一个非常优秀的深度学习的框架,具有速度快,代码简洁,可读性强的优点. 我们使用pytorch做一个简单的回归. 首先准 ...
- 怎么用 pytorch 查看 GPU 信息
如果你用的 Keras 或者 TensorFlow, 请移步 怎么查看keras 或者 tensorflow 正在使用的GPU In [1]: import torch In [2]: torch.c ...
随机推荐
- Redis客户端连接以及持久化数据(三)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
- 5,EasyNetQ-Send Receive
而发布/订阅和请求/响应模式是位置透明的,因为您不需要指定消息的消费者所在的位置,发送/接收模式专门用于通过命名队列进行通信. 它也不会对可以通过队列发送的消息的类型做任何假设. 这意味着您可以通过同 ...
- MOXA的Nport5600初始密码
今天第一次弄Nport,看了半天手册没找到初始密码,网上也搜不到,按照说明书上想打电话问问,发现根本是空号... 后来灵感一来试了一下,居然是:moxa
- JZYZOJ 2042 多项式逆元 NTT 多项式
http://172.20.6.3/Problem_Show.asp?id=2042 题意:求一个次数界为n的多项式在模P并模x^m的意义下的逆元.P=7*17*2^23+1. 多项式逆元的含义以及求 ...
- hashCode()方法与equals()方法
摘自别人的评论:http://blog.csdn.net/fhm727/article/details/5221792 当向集合Set中增加对象时,首先集合计算要增加对象的hashCode码,根据该值 ...
- inline关键字的作用
一.在C&C++中,inline关键字用来定义一个类的内联函数,引入它的主要原因是用它替代C中表达式形式的宏定义. 如下面一宏定义表达式: #define express(v1,v2) (v1 ...
- 【原】getInputStream()与getParameterMap()获得Post请求的数据区别
[前言] 最近在写一个接口,写好以后想测试,自己写ajax(Post方法)来调用接口倒是可以用action所在类的属性的get/set方法获得数据.但是不只是页面的ajax会调用这个接口,还有外系统会 ...
- HDU 4031 Attack
Attack Time Limit: 5000/3000 MS (Java/Others) Memory Limit: 65768/65768 K (Java/Others) Total Sub ...
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- Linux进程管理工具 Supervisord 的安装 及 入门教程
Supervisor是一个进程管理工具,官方的说法: 用途就是有一个进程需要每时每刻不断的跑,但是这个进程又有可能由于各种原因有可能中断.当进程中断的时候我希望能自动重新启动它,此时,我就需要使用到了 ...