Pytorch多GPU并行处理
- 可以参数2017coco detection 旷视冠军MegDet: MegDet 与 Synchronized BatchNorm
- PyTorch-Encoding官方文档对CGBN(cross gpu bn)实现
- GPU捉襟见肘还想训练大批量模型?
- 在一个或多个 GPU 上训练大批量模型: 梯度累积
- 充分利用多 GPU 机器:torch.nn.DataParallel
- 多 GPU 机器上的均衡负载 : PyTorch-Encoding 的 PyTorch 包,包括两个模块:DataParallelModel 和 DataParallelCriterion
- 分布式训练:在多台机器上训练: PyTorch 的 DistributedDataParallel
- Pytorch 的多 GPU 处理接口是
torch.nn.DataParallel(module, device_ids),其中module参数是所要执行的模型,而device_ids则是指定并行的 GPU id 列表。 - 而其并行处理机制是,首先将模型加载到主 GPU 上,然后再将模型复制到各个指定的从 GPU 中,然后将输入数据按 batch 维度进行划分,具体来说就是每个 GPU 分配到的数据 batch 数量是总输入数据的 batch 除以指定 GPU 个数。每个 GPU 将针对各自的输入数据独立进行 forward 计算,最后将各个 GPU 的 loss 进行求和,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,这样就完成了一次迭代计算。所以该接口还要求输入数据的 batch 数量要不小于所指定的 GPU 数量。

这里有两点需要注意:
- 主 GPU 默认情况下是 0 号 GPU,也可以通过
torch.cuda.set_device(id)来手动更改默认 GPU。 - 提供的多 GPU 并行列表中需要包含有主 GPU
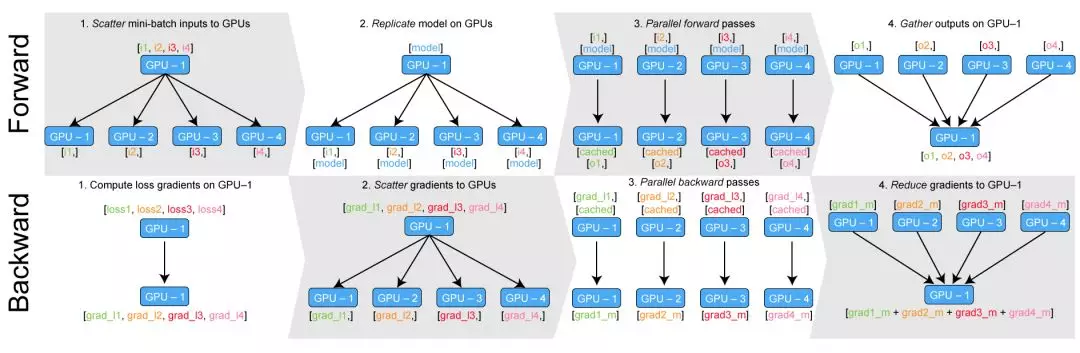
但是,DataParallel 有一个问题:GPU 使用不均衡。在一些设置下,GPU-1 会比其他 GPU 使用率高得多。
Pytorch多GPU并行处理的更多相关文章
- Pytorch 多 GPU 并行处理机制
Pytorch 的多 GPU 处理接口是 torch.nn.DataParallel(module, device_ids),其中 module 参数是所要执行的模型,而 device_ids 则是指 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- pytorch 多GPU训练总结(DataParallel的使用)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_40087578/artic ...
- Pytorch指定GPU的方法总结
Pytorch指定GPU的方法 改变系统变量 改变系统环境变量仅使目标显卡,编辑 .bashrc文件,添加系统变量 export CUDA_VISIBLE_DEVICES=0 #这里是要使用的GPU编 ...
- Ubuntu下安装pytorch(GPU版)
我这里主要参考了:https://blog.csdn.net/yimingsilence/article/details/79631567 并根据自己在安装中遇到的情况做了一些改动. 先说明一下我的U ...
- [转] pytorch指定GPU
查过好几次这个命令,总是忘,转一篇mark一下吧 转自:http://www.cnblogs.com/darkknightzh/p/6836568.html PyTorch默认使用从0开始的GPU,如 ...
- pytorch 多GPU处理过程
多GPU的处理机制: 使用多GPU时,pytorch的处理逻辑是: 1.在各个GPU上初始化模型. 2.前向传播时,把batch分配到各个GPU上进行计算. 3.得到的输出在主GPU上进行汇总,计算l ...
- Pytorch使用GPU
pytorch如何使用GPU在本文中,我将介绍简单如何使用GPU pytorch是一个非常优秀的深度学习的框架,具有速度快,代码简洁,可读性强的优点. 我们使用pytorch做一个简单的回归. 首先准 ...
- 怎么用 pytorch 查看 GPU 信息
如果你用的 Keras 或者 TensorFlow, 请移步 怎么查看keras 或者 tensorflow 正在使用的GPU In [1]: import torch In [2]: torch.c ...
随机推荐
- java 生成随机数字
for(int i=0;i<size1;i++){ int n = (int)(java.lang.Math.random()*99); LinkNode newLink = new LinkN ...
- centos yum 安装php mysql
1 安装php7 查看 centos 版本 # cat /etc/centos-release 删除之前的 php 版本 # yum remove php* php-common rpm 安装 Php ...
- usb3.0 monitor is already started
用360 开机加速里找到这个程序,把它从开机启动中删除掉就好.
- Bzoj3122:多项式BSGS
根据鸽笼原理,在p次后一定循环,一眼BSGS.发现他给的函数是个一次函数,一次函数有什么性质呢?f(f(x))还是一次函数,这样就能做了.首先我们暴力预处理出f(f(f(x)))......sqrt( ...
- js的sort()方法
说明 如果调用该方法时没有使用参数,将按字母顺序对数组中的元素进行排序,说得更精确点,是按照字符编码的顺序进行排序.要实现这一点,首先应把数组的元素都转换成字符串(如有必要),以便进行比较. arra ...
- Codeforces Beta Round #14 (Div. 2) D. Two Paths 树形dp
D. Two Paths 题目连接: http://codeforces.com/contest/14/problem/D Description As you know, Bob's brother ...
- pat advanced 1139. First Contact (30)
题目链接 解法暴力 因为有 0000, -0000 这样的数据,所以用字符串处理 同性的时候,遍历好朋友时会直接遍历到对方,这个时候应该continue #include<cstdio> ...
- 群晖NAS简介(转)
Synology 群晖科技(Synology )创立于 2000 年,自始便专注于打造高效能.可靠.功能丰富且绿色环保的 NAS 服务器,是全球少数几家以单纯的提供网络存储解决方案获得世界认同的华人企 ...
- BZOJ 1207 DP
打一次鼹鼠必然是从曾经的某一次打鼹鼠转移过来的 以打每一个鼹鼠时的最优解为DP方程 #include<iostream> #include<cstdio> #include&l ...
- 《Go语言实战》摘录:6.1 并发 - 并行 与 并发
6.1 并行 与 并发