selenium登录爬取知乎出现:请求异常请升级客户端后重试的问题(用Python中的selenium接管chrome)
一、问题
使用selenium自动化测试爬取知乎的时候出现了:错误代码10001:请求异常请升级客户端后重新尝试,这个错误的产生是由于知乎可以检测selenium自动化测试的脚本,因此可以阻止selenium的继续访问。这也算是比较高级的反爬取措施。
二、解决
解决方法,使用自己打开的一个浏览器,再用selenium接管这个浏览器这样就可以完成反爬的处理。
1.建议一个新的映射,以保存原来的chrome不被污染
1)添加环境变量
将chrome.exe放入系统环境变量中,找到驱动位置添加变量,如果没找到,最快的方法就是点击图标右键,点击访问文件地址
chrome.exe位置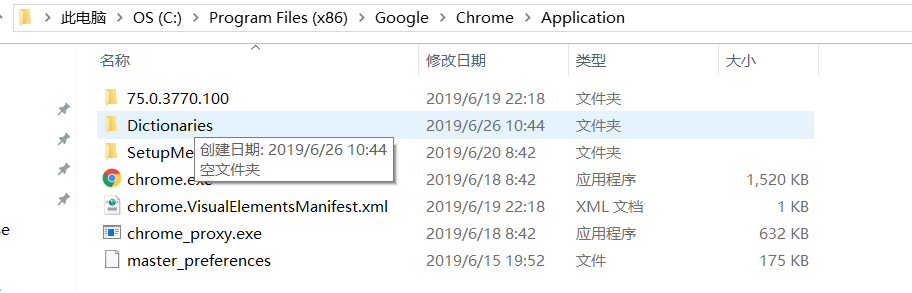
快捷访问方式,在菜单栏同样可以
2)新建一个存放新环境的文件夹并映射
使用指令【chrome.exe --remote-debugging-port=9222 --user-data-dir="E:\data_info\selenium_data"】
其中--remote-debugging-port是建立新的移植位置,其中端口后面会使用(自定义), --user-data-dir是数据存储的目录(自定义)
此时会打开一个网页放着就行
2.selenium代码接管
通过下面的代码就可以登录知乎
import time
import json from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait class ZhiHu:
def __init__(self):
self.url = 'https://www.zhihu.com/'
self.chrome_options = Options()
self.chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
self.browser = webdriver.Chrome(executable_path=r'E:\Environment\python_global\Scripts\chromedriver.exe', options=self.chrome_options) # executable执行webdriver驱动的文件 def get_start(self):
self.browser.get(self.url)
# time.sleep(20) # 可以选择手动登录或者是自动化,我这里登录过就直接登陆了
info = self.browser.get_cookies() # 获取cookies
print(info)
with open(r"..\download_txt\info.json", 'w', encoding='utf-8') as f:
f.write(json.dumps(info)) if __name__ == '__main__':
zhihu = ZhiHu()
zhihu.get_start()
三、结果展示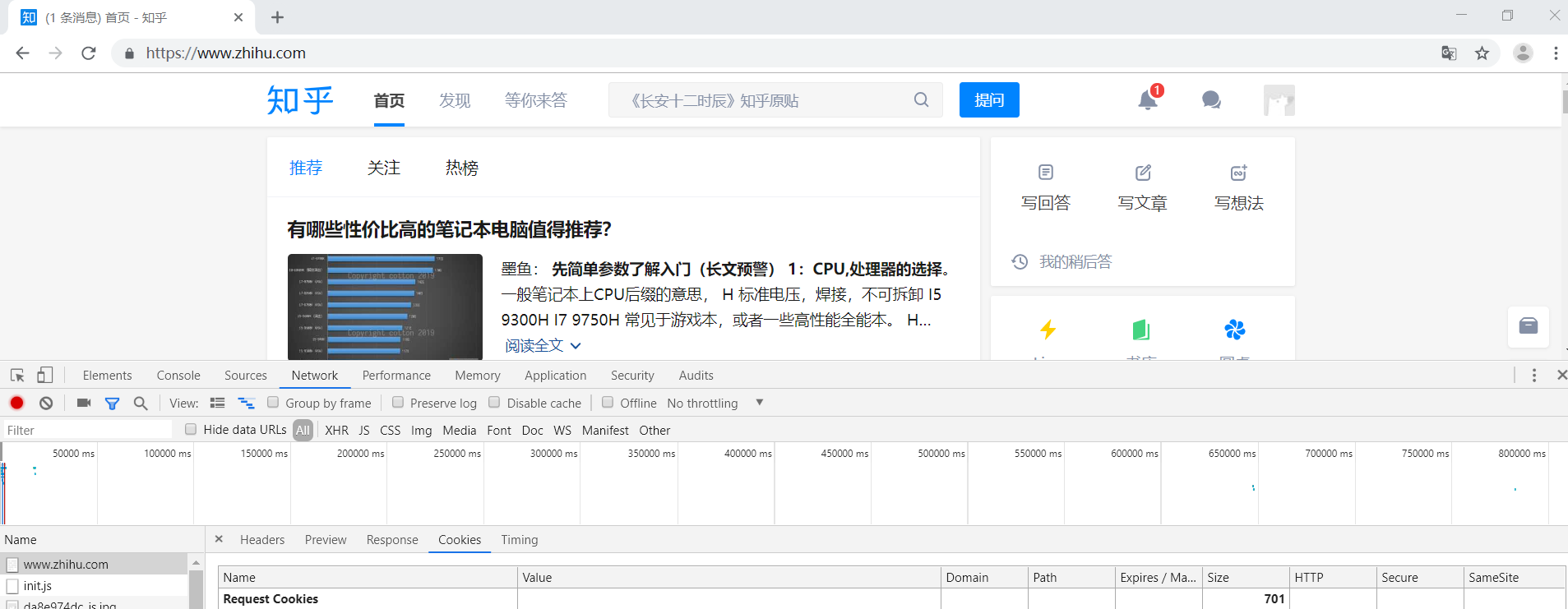
四、总结
利用这个selenium接管正在使用的浏览器就可以绕过知乎的反爬,当然也可以做更多的爬虫,selenium在爬虫的使用中还是有重要的地位,偷懒一点就可以使用这个。这种方法可以获取cookies这样在使用其他的爬虫,就可以使用这个cookies会加快爬取的效率,以及突破不适用浏览器的反爬措施。这引起我们另一个思考,我们直接接管我们正常的chrome好像更加的高效,这个可以以后的学习中尝试一下。
五、参考
附一些参考,方便自己学习,毕竟每次百度起来都很麻烦
https://www.cnblogs.com/HJkoma/p/9936434.htmlhttps://blog.csdn.net/qq_42206477/article/details/86477446
selenium登录爬取知乎出现:请求异常请升级客户端后重试的问题(用Python中的selenium接管chrome)的更多相关文章
- 第二个爬虫之爬取知乎用户回答和文章并将所有内容保存到txt文件中
自从这两天开始学爬虫,就一直想做个爬虫爬知乎.于是就开始动手了. 知乎用户动态采取的是动态加载的方式,也就是先加载一部分的动态,要一直滑道底才会加载另一部分的动态.要爬取全部的动态,就得先获取全部的u ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- scrapy爬取知乎某个问题下的所有图片
前言: 1.仅仅是想下载图片,别人上传的图片也是没有版权的,下载来可以自己欣赏做手机背景但不商用 2.由于爬虫周期的问题,这个代码写于2019.02.13 1.关于知乎爬虫 网上能访问到的理论上都能爬 ...
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
随机推荐
- GitBash上传项目出现[fatal: remote origin already exists.]问题解决方案
问题截图如下: 当出现这个问题时,不要慌,只需要输入 git remote rm origin 就可以解决,输入完前面的命令后再次 输入 git remote add origin https://. ...
- Android 中指纹识别
Android从6.0系统开始就支持指纹认证功能了,指纹功能还需要有硬件支持才行 指纹与手机系统设置的指纹进行匹配 如图: 在LoginActivity 中弹出指纹验证Fragment,验证成功进入M ...
- Android 实现系统分享
使用手机上的程序,来分享/发送,比如QQ的“发送到我的电脑”. 1.分享/发送文本内容 Intent shareIntent = new Intent(); shareIntent.setAction ...
- Jenkins+gradle+git部署
感谢博友分享,这边记录下https://blog.csdn.net/jiankeufo/article/details/78228334 我的密码7789cc2b62114e9da9fb78b0aa3 ...
- [b0015] python 归纳 (一)_python组织方式
结论: xxx.yyyy yyyy 可以是 类.类对象.函数.变量 xxx 可以是 包.模块.类 代码: ref1.py # -*- coding: utf-8 -*- import os class ...
- mysql数据库之用户管理和权限
mysql服务器进程在启动的时候会读取这6张表,并在内存中生成授权表,所以这几个文件是直接加载进内存的. 以后后续的任何用户登录及其访问权限的检查都通过检查这6张表来实现的.通过访问内存上所生成的结构 ...
- 网络流之最大流Dinic --- poj 1459
题目链接 Description A power network consists of nodes (power stations, consumers and dispatchers) conne ...
- windows 7系统下查看被占用的端口并解除占用
运行输入cmd,在命令行输入 netstat -ano 查找所占用端口所在的行,如图本例子被占用端口为9999,记住对应的pid 然后输入 tasklist|findstr pid(此处为9528) ...
- flask 案例项目基本框架的搭建
综合案例:学生成绩管理项目搭建 一 新建项目目录students,并创建虚拟环境 mkvirtualenv students 二 安装开发中使用的依赖模块 pip install flask==0.1 ...
- 201871010117--石欣钰--《面向对象程序设计(java)》第十六周学习总结
博文正文开头格式:(2分) 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh 这个作业的要求在哪里 https://www.cnblogs.com ...