数据分析入门——pandas之DataFrame基本概念
一、介绍
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
可以看作是Series的二维拓展,但是df有行列索引:index、column
推荐参考:https://www.jianshu.com/p/c534e83d2f4b
二、快速入门
1.打开csv

发现报错,原因是路径中\User的\u和转义符号冲突了,我们使用字符串中的知识,添加r开头表示不转义即可:
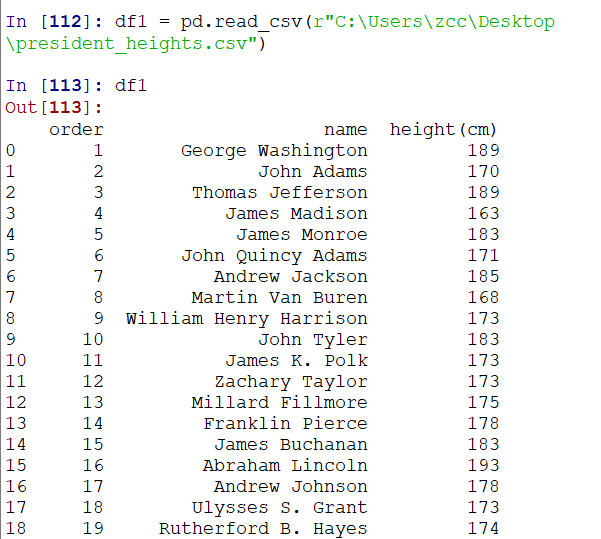
它包含的是行列索引和值values,value对应的就是二维的ndarray了
2.创建df
1.通过字典来创建df

可以通过index属性来控制索引,column同理:(在创建以后通过df.index = []的属性赋值也可以实现控制索引的)

2.可以通过列表来创建,给定ndarray,再给定Index和columns来构造df
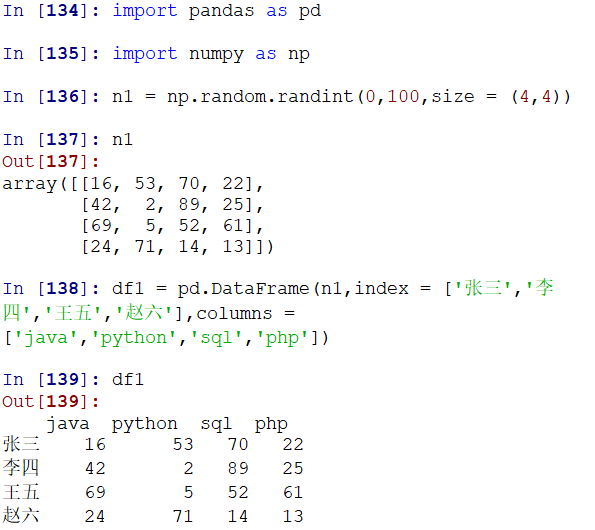
参考:https://www.yiibai.com/pandas/python_pandas_dataframe.html
3.df的索引
列索引:
通过列的索引检索,可以返回对应的列,也就是之前的Series

行索引:
使用loc或者iloc进行索引(其中,前者是显式索引,需要指定索引的值,后者是隐式索引,已过时的ix方法不再展开)
使用loc检索出一行,发现结果也是Series:

需要检索多行时,需要两个中括号(并且返回的也是DataFrame):

并且loc是支持切片(左右的闭区间)的:(支持的是行切片,如果切片范围不存在,则返回空数据,而不是报错)
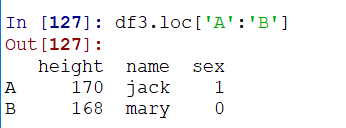
隐式索引是类似的:(但是iloc的切片是左闭右开,与上面稍有不符合)

//存在部分bug:汉字索引有个别索引不生效,无法检索
元素索引:
可以通过线检索出某一列,再操作这个列Series(注意使用loc的推荐方法):

其他变通形式同理:

上面这个简写就变成:这就是行索引的变通形式

4)DataFrame的数据查看
1.通过head()、tail()查看头几行或者尾几行(默认n = 5):

2.通过a.index ; a.columns ; a.values 即可查看对应属性
3.a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
三、DataFrame的运算
1.DF之间的运算
构建的df1、df2如下:(用于后续计算)
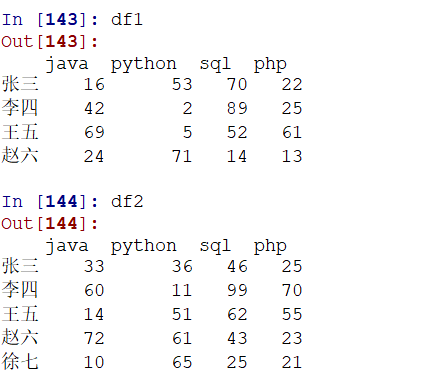
其实总结下来就是,行列索引相同的(也就是需要对齐再相加,无法对齐时使用NaN对齐,列会取并集,行值不对齐时使用默认NaN),进行计算,没有的全部用空进行计算(参考https://blog.csdn.net/weixin_34208283/article/details/86005233)
https://blog.csdn.net/weixin_33966095/article/details/88446784

需要避免NaN值可以使用pandas的add方法的fill_value来控制:

2.DF与Series之间的运算
直接运算,发现结果并不如人意:

提取行发现可以计算:

这也就是Series中的广播规则,默认情况下是s的index和df的columns进行对齐的,第二个对齐后的操作,看数据知道是广播成了四行与df对齐,可以通过 axis来进行广播控制(0表示在列上广播,1表示在行上广播)
数据分析入门——pandas之DataFrame基本概念的更多相关文章
- 数据分析入门——pandas之DataFrame数据丢失
一.数据丢失分类 1)nd中分为两种:None和np.nan(NaN) 其中,None是python中的对象,是一个object:而nan是一个float类型 两种不同的类型,运算速度也是不同的 2) ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之Series
一.介绍 Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具. 官方中文文档:https://www.pypandas.cn ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
- 数据分析入门——pandas之合并函数merge
merge有点类似SQL中的join,可以将不同数据集按照某些字段进行合并,得到新的数据集 1.参数一览表: 2.一对一连接:默认情况下,会按照相同字段的进行连接 例如有相同字段emp的两个df,m ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
随机推荐
- #2590. 「NOIP2009」最优贸易
C 国有 n 个大城市和 m 条道路,每条道路连接这 n 个城市中的某两个城市.任意两个城市之间最多只有一条道路直接相连.这 m 条道路中有一部分为单向通行的道路,一部分为双向通行的道路,双向通行的道 ...
- MQ的常见应用场景
MQ的常见的应用场景为:解耦,异步,流量削峰 在解耦场景中: 不使用MQ的耦合场景: 使用解耦的场景为: 异步的方式: 不使用MQ的同步高延时请求场景: 使用异步化之后的接口性能优化: 没有使用mq的 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- Kubernetes 学习6 Pod控制器应用进阶
一.资源配置清单 1.自主式Pod资源 2.资源的清单格式,大多数清单格式都遵循如下条件: a.一级字段:apiVersion(group/version),kind,metadata(name,na ...
- mongoDB线上数据库连接报错记录
报错信息提示:无法在第一次连接时连接到服务器 别的一切正常,经过查询得知,是因为如果电脑没设定固定IP,并且重启情况下可能会导致IP地址更改. 解决方法: 将本机ip地址添加到cluster的白名单即 ...
- linux 安装gcc 和 g++
以CentOS为例,安装后是没有C语言和C++编译环境的,需要手动安装,最简单的是用yum的方式安装,过程如下: 1.安装gcc yum install gcc 询问是否,按y键回车即可,或者 yum ...
- flutter 从接口获取json数据显示到页面
如题,在前端,是个很简单的ajax请求,json的显示,取值都很方便,换用dart之后,除了层层嵌套写的有点略难受之外,还有对json的使用比js要麻烦 1. 可以参照 flutter-go 先封装一 ...
- 2017.10.2 国庆清北 D2T2 树上抢男主
/* 我只看懂了求LCA */ #include<iostream> #include<cstring> #include<cstdio> #include< ...
- (14)Go导入包几种方式
(1)一般方式[导入单个和多个] (2)匿名导入包/忽略包 (主要用到有些包的init函数) (3)点操作包 (4)包别名/自定义包名 package main ////导入单个包 //import ...
- 三层设备-SHRP详解
步骤:3-sw1enconf tvlan databasevtp domain s2t117vtp servervlan 10vlan 20vlan 30vlan 40exitint r f0/7 - ...