【Hadoop 分布式部署 一 :分布式部署准备虚拟机 】
一、将IP配置为静态
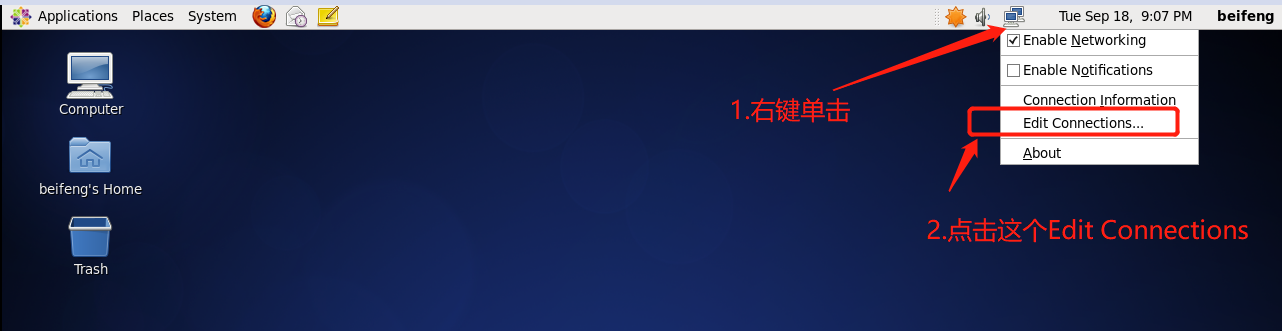
按照 下面的操作将IP配置为静态IP 这个静态的IP地址 是你自己设置的,只要符合虚拟机的IP段就可以。最后点击 Apply 需要root密码
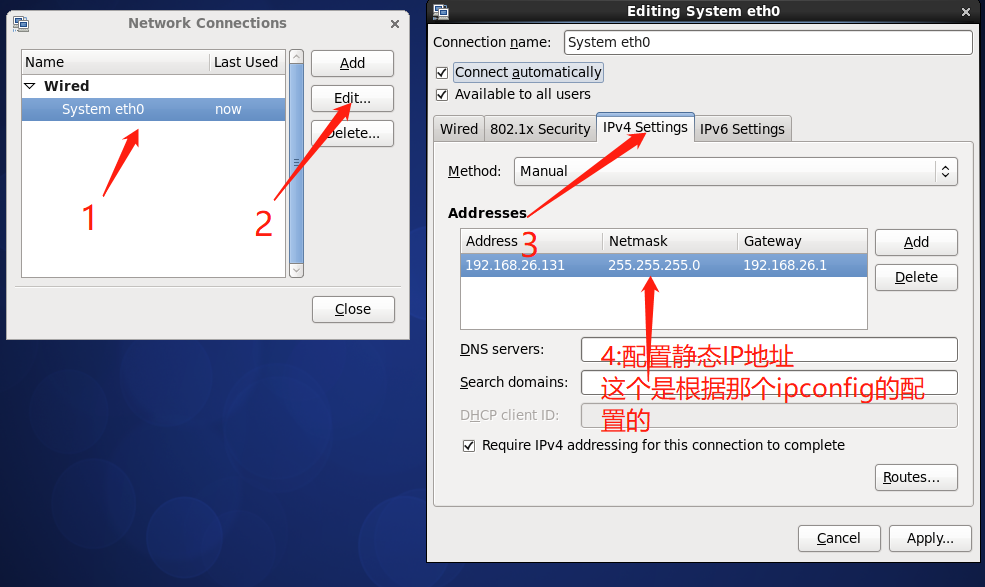
将网络断开 (在网络图标左键 Disconnect ) 重新连接 检查IP是否改变了
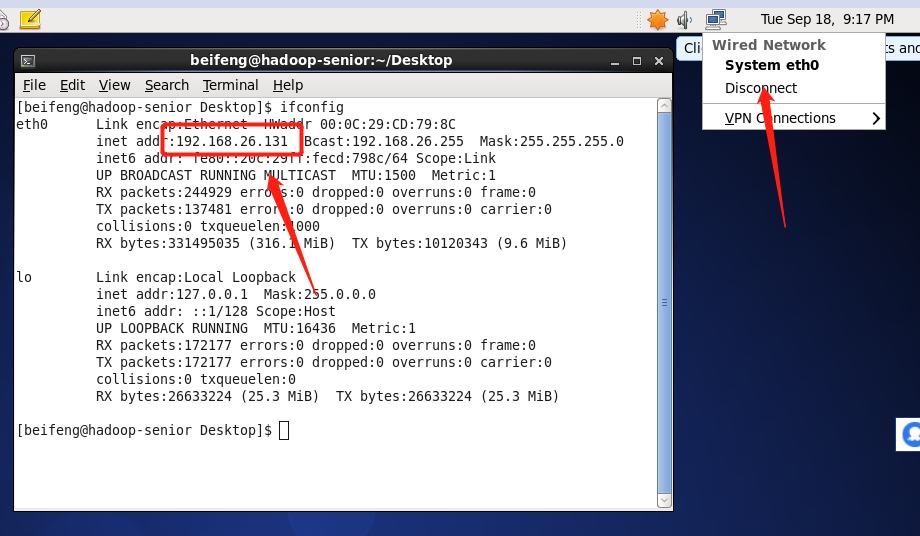
如果IP地址已经改变了,那就说明网络配置成功
更改 主机名的方法(这个一会用到 现在这里可以不用改) 编辑 /etc/sysconfig/network 中的主机和IP地址

规划三台 分布式机器

现在开始克隆虚拟机 选中需要克隆的虚拟机 然后在工具栏 点击 虚拟机 -> 管理 ----->克隆 点击下一步,注意:克隆类型选择的是完整克隆 ,虚拟机的位置 随便选择,我选择的是我所有虚拟机存放的位置 等待克隆完成,这就是第一个虚拟机的准备
第三个虚拟机使用另一种方式,可以直接拷贝 文件 到第一个虚拟机的文件夹中,拷贝文件到一个新的文件夹
其中 CentOS.vmx.lck 这个文件夹是不需要的, 所以拷贝完直接删除就可以
启动第二台 虚拟机的时候 网卡会出现 Auto eth1 ,是因为改变了虚拟机,我们需要配置网卡
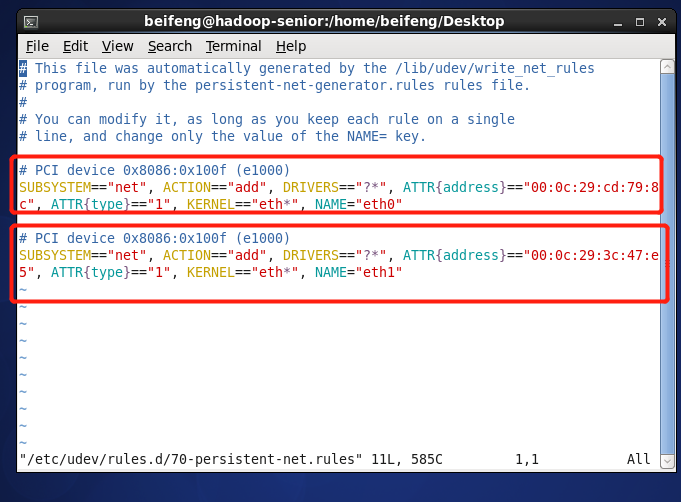
使用root 用户 执行命令: vim /etc/udev/rules.d/70-persistent-net.rules
会有两个网卡,只要将eth0 删除 将 eth1 改变成 eth0 即可 还有需要记录下 mac 地址 :00:0c:29:47:e5
然后编辑 vim /etc/sysconfig/network-scripts/ifcfg-eth0 将里面的mac地址 换成 生成的这个mac地址
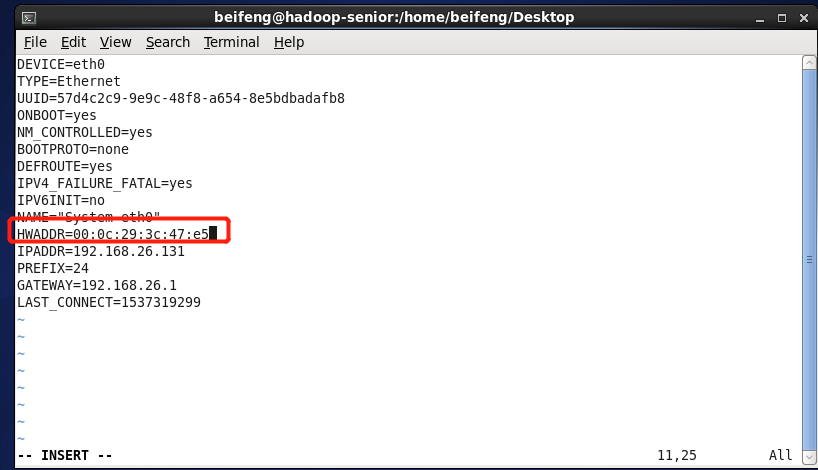
重启机器才会 生效
第三台机器 因为是拷贝文件的,所以mac 地址 是和第一台 机器的mac地址是一样的,所以需要重新生成一下mac地址
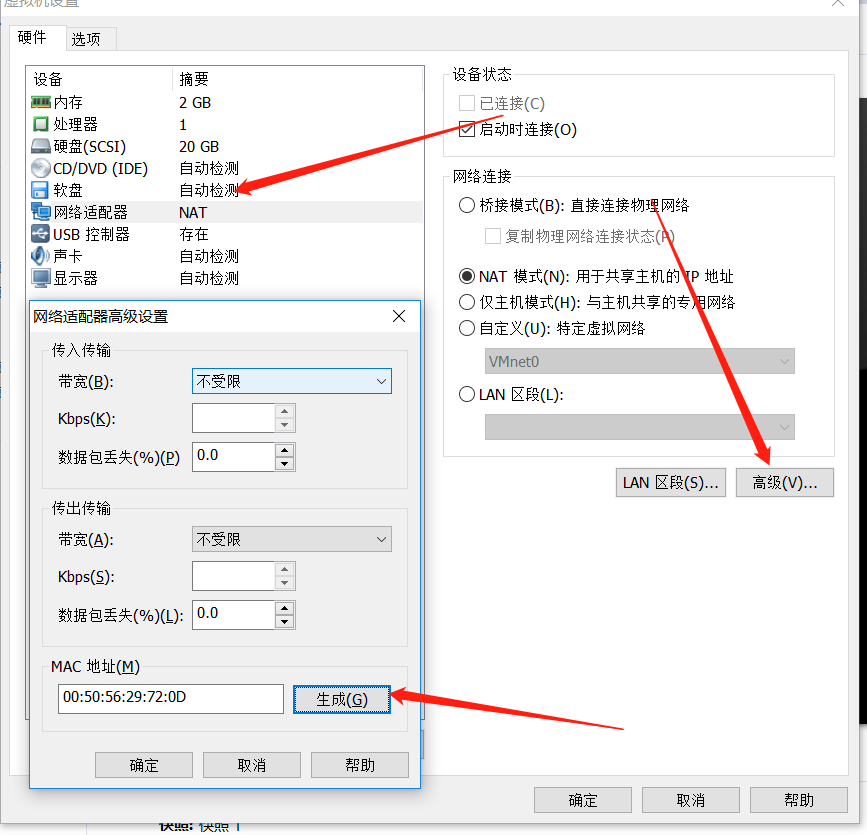
然后启动该虚拟机,选择我已经移动该虚拟机
进入第三台虚拟机中进行配置静态IP,方法和刚才第一个虚拟机配置静态Ip的方法相同(这个网卡设置 是习惯问题,不改也是可以的,但是为了方便起见 还是配置一下)
步骤:删除 eth0 将eth1 改变为 eth0 然后复制mac地址,到指定目录 更改mac地址 顺便也 更改一下ip地址 更改完后 打开虚拟机
最后将 3台 虚拟机重启,使用ifconfig 查看ip 地址配置的是否正确
【Hadoop 分布式部署 一 :分布式部署准备虚拟机 】的更多相关文章
- 3-3 Hadoop集群完全分布式配置部署
Hadoop集群完全分布式配置部署 下面的部署步骤,除非说明是在哪个服务器上操作,否则默认为在所有服务器上都要操作.为了方便,使用root用户. 1.准备工作 1.1 centOS6服务器3台 手动指 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
- Hadoop生态圈-phoenix完全分布式部署以及常用命令介绍
Hadoop生态圈-phoenix完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. phoenix只是一个插件,我们可以用hive给hbase套上一个JDBC壳,但是你 ...
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
- 一文搞定FastDFS分布式文件系统配置与部署
Ubuntu下FastDFS分布式文件系统配置与部署 白宁超 2017年4月15日09:11:52 摘要: FastDFS是一个开源的轻量级分布式文件系统,功能包括:文件存储.文件同步.文件访问(文件 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 三、Linux部署MinIO分布式集群
MinIO的官方网站非常详细,以下只是本人学习过程的整理 一.MinIO的基本概念 二.Windows安装与简单使用MinIO 三.Linux部署MinIO分布式集群 四.C#简单操作MinIO 一. ...
随机推荐
- 【Hadoop学习之九】MapReduce案例分析一-天气
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 找出每个月气温最高的2天 1949 ...
- js里用append()和appendChild有什么区别?
parentNode.append()是还在试用期的方法,有兼容问题.是在parendNode节点中最后一个子节点后插入新Node或者DOMString(字符串,插入后为Text节点). 与paren ...
- C# 设置按钮快捷键
参考自:http://www.csharpwin.com/csharpspace/3932r8132.shtml 一.C# button快捷键之第一种:Alt + *(按钮快捷键) 在Button按钮 ...
- python smtplib 发送邮件简单介绍
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式python的smtplib提供了一种很 ...
- linux 查找locate find
1.locate locate指令和find找寻档案的功能类似,但locate是透过update程序将硬盘中的所有档案和目录资料先建立一个索引数据库,在 执行loacte时直接找该索引,查询速度会较快 ...
- JavaScript 中禁止用户右键菜单,复制,选取,Ctrl,Alt,Shift. 获取宽高,清除浮动
//禁用右键菜单 document.oncontextmenu = function(){ event.returnValue = false; } //禁用选取内容 document.onselec ...
- 怎样从外网访问内网WebLogic?
本地安装了一个WebLogic,只能在局域网内访问,怎样从外网也能访问到本地的WebLogic呢?本文将介绍具体的实现步骤. 准备工作 安装并启动WebLogic 默认安装的WebLogic端口是70 ...
- linux下nginx整合php
在nginx中药使用php可不像apache那样,因为apache是把php当做自己的一个模块来启动的, 而我们的nginx是把http请求转发给php程序,也就是说,php和nginx是相互独立的的 ...
- K8S学习笔记之CentOS7集群使用Chrony实现时间同步
0x00 概述 容器集群对时间同步要求高,实际使用环境中必须确保集群中所有系统时间保持一致,openstack官方也推荐使用chrony代替ntp做时间同步. Chrony是一个开源的自由软件,像Ce ...
- DOM EventListener
向元素添加事件句柄的语法:element.addEventListener(event, function, useCapture); 第一个参数是事件的类型,如click或者mousedown,注意 ...