(三)xpath爬取4K高清美女壁纸


功能:通过xpath爬取彼岸图网的高清美女壁纸
url = 'http://pic.netbian.com/4kmeinv/'
1. 通过url请求整张页面的数据
2.通过页面的标签定位图片所在的位置
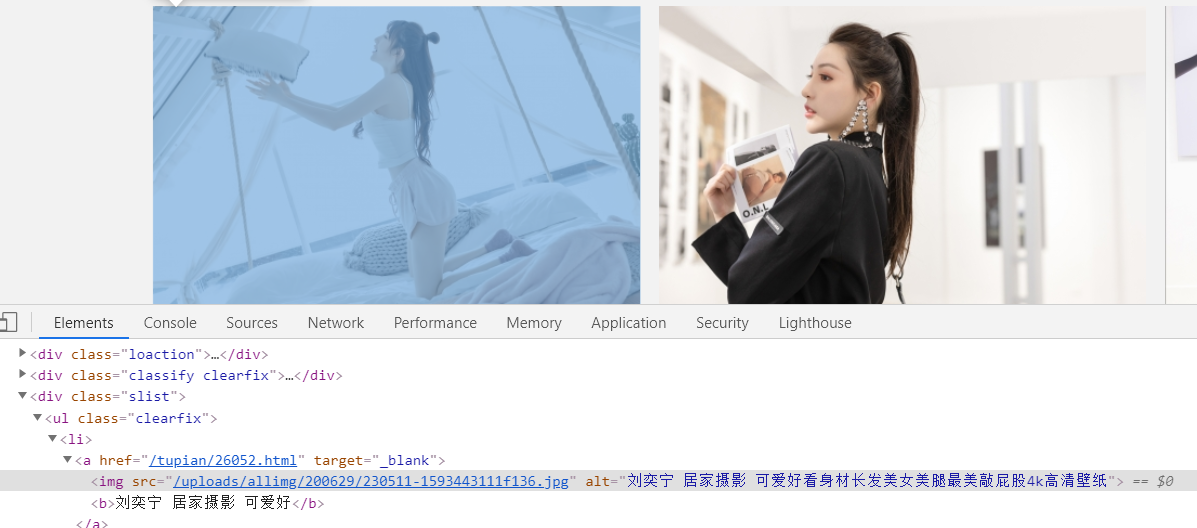
3.找到所有图片的通用的标签
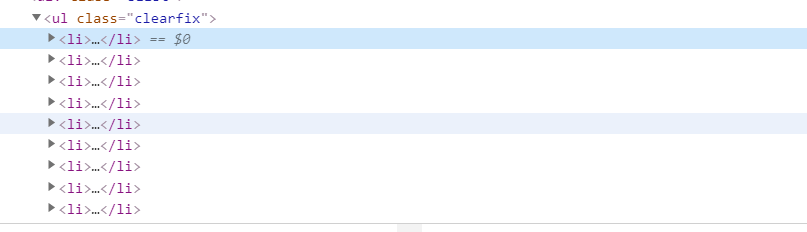
向图片标签的父级查找,可以发现每一张图片都在ul下的li标签下。
4.知道每一个li标签下图片所处的位置
5.思路:通过url拿到整张页面的数据,通过etree进行标签定位,拿到所有的li标签,再循环对每一个li标签下的每一个图片发送请求,拿到图片。
import requests
from lxml import etree
import os
import time
if not os.path.exists('./4kPic'):
os.makedirs('./4kPic')
url ='http://pic.netbian.com/4kmeinv/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
response = requests.get(url=url,headers=headers)
# 获取网页所有数据
page_text = response.text
# 实例化etree对象
tree = etree.HTML(page_text)
# 找到所有的li标签
li_list = tree.xpath("//div[@class='slist']/ul/li")
# 遍历所有li标签
for li in li_list:
# 局部解析用./表示当前的li标签
img_src = li.xpath('.//img/@src')[0] # 获取图片路径
img_alt = li.xpath('.//img/@alt')[0] # 获取图片名称
# 解决中文乱码问题的通用方式
img_name = img_alt.encode('iso-8859-1').decode('gbk')
# 获取图片完整路径
img_url = 'http://pic.netbian.com'+img_src
try:
# content获取图片的二进制数据 文件传输都是以二进制的形式
img_data = requests.get(url=img_url, headers=headers).content
except requests.exceptions.ConnectionError:
time.sleep(1) # 数据请求过快会请求失败 可以time.sleep
continue
fileName = img_name+'.jpg'
with open('4kPic/'+fileName,'wb') as f:
f.write(img_data)
print(img_name+'--------------爬取成功')
注:解决中文乱码问题的方式
方式1:
response.encoding='utf-8' 有些数据不能直接用utf8编码 这不是一种通用的方式
方式2:
img_name = img_alt.encode('iso-8859-1').decode('gbk') 这种为通用方式
(三)xpath爬取4K高清美女壁纸的更多相关文章
- 实例学习——爬取Pexels高清图片
近来学习爬取Pexels图片时,发现书上代码会抛出ConnectionError,经查阅资料知,可能是向网页申请过于频繁被禁,可使用time.sleep(),减缓爬取速度,但考虑到爬取数据较多,运行时 ...
- 别人用钱,而我用python爬虫爬取了一年的4K高清壁纸
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取htt ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
目录 前言 XPath的使用方法 XPath爬取数据 后言 @(目录) 前言 本章同样是解析网页,不过使用的解析技术为XPath. 相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用 ...
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
随机推荐
- K8s场景下Logtail组件可观测方案升级-Logtail事件监控发布
简介: SLS针对Logtail本身以及Logtail的管控组件alibaba-log-controller,采用K8s事件的方式,将处理流程中的关键事件透出,从而让用户能够更清楚的感知其中发生的异常 ...
- 阿里云EMAS移动测试,帮您快速掌握移动端兼容性测试技巧
简介: 兼容性测试用于验证应用在不同设备上进行安装/启动/登录/不同版本覆盖安装/卸载等操作时,是否存在兼容性问题:如界面适配问题.应用性能等,现阿里云EMAS套餐免费试用,帮您快速掌握移动端兼容性测 ...
- 性能提升 57% ,SMC-R 透明加速 TCP 实战解析 | 龙蜥技术
简介:SMC-R 是如何加速 TCP 应用? 编者按:TCP 协议作为当前使用最为广泛的网络协议,场景遍布移动通信.数据中心等.对于数据中心场景,通过弹性 RDMA 实现高性能网络协议 SMC-R, ...
- 2018-8-29-dotnet-core-添加-SublimeText-编译插件
title author date CreateTime categories dotnet core 添加 SublimeText 编译插件 lindexi 2018-08-29 08:53:47 ...
- vue中使用vue-b2wordcloud创建词云
安装使用 安装:使用npm install vue-b2wordcloud --save或者直接在vue ui中添加vue-b2wordcloud运行依赖 使用:在main.js中导入使用 impor ...
- fastreport .net打印普通报表
fastreport .net打印普通报表 前言: .net代码层先不记录在这,后续会单独写一篇博客来记录. 直接在工具上进行功能点的实现 一.效果图 二.功能点 分页 分页小计 金额大写 三.功能点 ...
- 深入理解 Swift Combine
Combine 文中写一些 Swift 方法签名时,会带上 label,如 subscribe(_ subscriber:),正常作为 Selector 的写法时会忽略掉 label,只写作 subs ...
- 使用qemu运行risc-v ubuntu
参考 Ubuntu installation on a RISC-V virtual machine using a server install image and QEMU 用到的文件 fw_ju ...
- Blazor/Hybird 触屏下单程序调优笔记
环境 Blazor Net8.0 + FreeSql + Bootstrap Blazor 组件 以下都是自己瞎琢磨的和官网资料搬运,肯定有不少错漏和不合理的地方,非常希望各位大佬评论区给我建议和意见 ...
- 谷歌 hackbar 不能使用的问题
谷歌 hackbar 不能使用的问题 下载 hackbar 插件:https://github.com/Mr-xn/hackbar2.1.3 解压文件,将其拖入 chrome 扩展程序中 点击详情,点 ...