Selenium - 元素定位(1) - 八种元素定位
Selenium - 元素定位
八种元素定位
我们在做WEB自动化时,最根本的就是操作页面上的各种元素,而操作的基础便是元素的定位,只有准确地定位到唯一元素才能进行后续的自动化控制,下面将对各种元素定位方式进行总结归纳。
单一属性定位 :
id,name,class name,tag name,link,partial_link多样式定位(强烈推荐):
css,xpath
说明:以下操作统一使用百度首页 https://www.baidu.com 进行示例,鼠标右键然后点击检查(或按f12)可以查看具体的前端代码。

id
从上面定位到的搜索框属性中,有个
id="kw"的属性,我们可以通过这个id定位到这个搜索框find_element_by_id()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过id定位搜索框,并输入selenium
driver.find_element_by_id('kw').send_keys('selenium')
name
从上面定位到的搜索框属性中,有个
name="wd"的属性,我们可以通过这个name定位到这个搜索框;find_element_by_name()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过name定位搜索框,并输入selenium
driver.find_element_by_name('wd').send_keys('selenium')
class
从上面定位到的搜索框属性中,有个
class="s_ipt"的属性,我们可以通过这个class定位到这个搜索框;find_element_by_class_name()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过class定位搜索框,并输入selenium
driver.find_element_by_class_name('s_ipt').send_keys('selenium')
tag
如果懂HTML知识,我们就知道HTML是通过tag来定义功能的,比如
input是输入,table是表格,等等...。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多
div、input、a等tag,所以很难通过tag去区分不同的元素。find_element_by_tag_name()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过tag定位搜索框,并输入selenium, 此处必报错
driver.find_element_by_tag_name('input').send_keys('selenium')
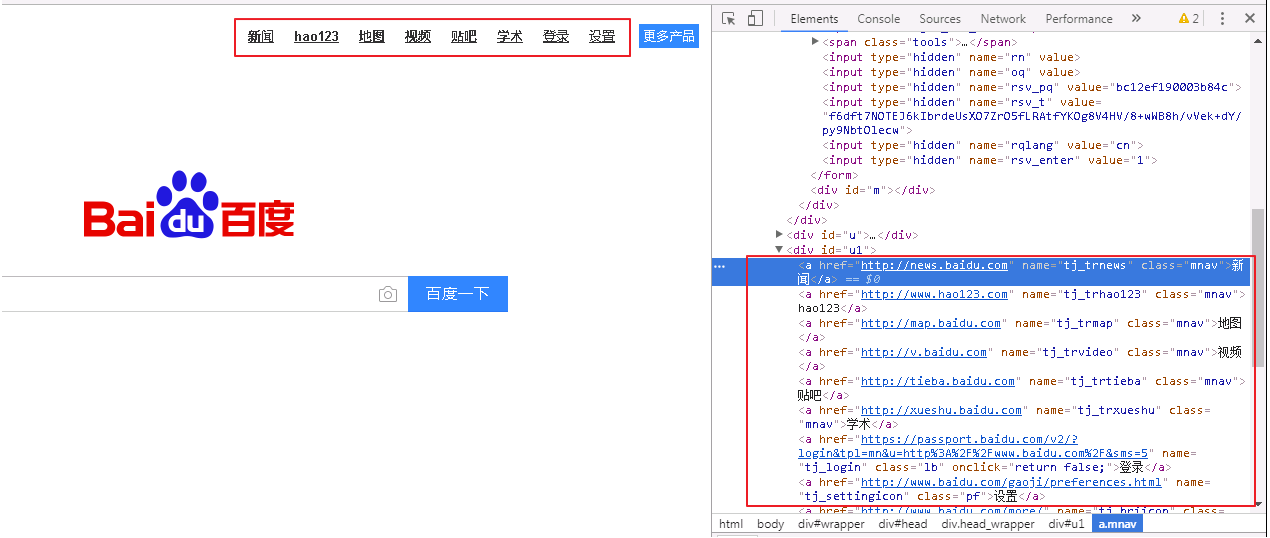
link
此种方法是专门用来定位文本链接的,比如百度首页右上角有“新闻”,“hao123”,“地图”等链接;
我们来定位“新闻”这个链接元素;
find_element_by_link_text()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过link定位"新闻"这个链接并点击
driver.find_element_by_link_text('新闻').click()
partial_link
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
我们用这种方法来定位百度首页的“新闻”超链接;
find_element_by_partial_link_text()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过partial_link定位"新闻"这个链接并点击
driver.find_element_by_partial_link_text('新闻').click()
xpath
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id、name、class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。
那么这个时候我们就只能通过xpath或者CSS来定位了。
find_element_by_xpath()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过xpath定位搜索框,并输入selenium
driver.find_element_by_xpath("//*[@id='kw']").send_keys('selenium')
CSS
这种方法相对xpath要简洁些,定位速度也要快些,但是学习起来会比较难理解,这里只做下简单的介绍,详细的可以查看CSS进阶。
CSS定位百度搜索框。
find_element_by_css_selector()
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
# 通过CSS定位搜索框,并输入selenium
driver.find_element_by_css_selector('#kw').send_keys('selenium')
定位多个元素
上述的八种定位方法,均只能定位到指定元素的信息,不能定位多个元素;
我们仅需在 element 后面,增加 s ,就可以定位多个元素;
from selenium import webdriver
driver = Webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_elements_by_id()
driver.find_elements_by_class_name()
driver.find_elements_by_tag_name()
driver.find_elements_by_link_text()
driver.find_elements_by_name()
driver.find_elements_by_pratial_link_text()
driver.find_elements_by_xpath()
driver.find_elements_by_css_selector()
Selenium - 元素定位(1) - 八种元素定位的更多相关文章
- selenium自动化测试——常见的八种元素定位方法
selenium常用的八种元素定位方法 1.通过 id 定位:find_element_by_id() 2.通过 name 定位:find_element_by_name() 3.通过 tag 定位: ...
- Selenium:八种元素定位方法
前言: 我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素.工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素.那么我们怎么来定位他们呢? 在学 ...
- Selenium八种元素定位方法源码阅读
接触过Selenium的都知道元素定位有八种方法,但用不同的方法在执行时有什么区别呢? 元素定位8种方法(Python版),当然还有每一个方法对应的find_elements方法 find_eleme ...
- Selenium2+python自动化-八种元素定位(Firebug和Firepath)
前言 自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告.本篇主要讲如何用firefox辅助工具进行元素定位.元素定位在这四个环节中 ...
- Selenium2学习(三)-- 八种元素元素定位(Firebug和firepath)
前言 自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告.本篇主要讲如何用firefox辅助工具进行元素定位.元素定位在这四个环节中是至关 ...
- Selenium Webdriver元素定位的八种常用方式
楼主原创,欢迎学习和交流,码字不容易,转载请注明出处,谢谢. 在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素 ...
- Selenium Webdriver元素定位的八种常用方法
如果你只是想快速实现控件抓取,而不急于了解其原理,可直接看: http://blog.csdn.net/kaka1121/article/details/51878346 如果你想学习web端自动化, ...
- Selenium Webdriver元素定位的八种常用方式(转载)
转载自 https://www.cnblogs.com/qingchunjun/p/4208159.html 在使用selenium webdriver进行元素定位时,通常使用findElement或 ...
- 爬虫-【selenium—Webdriver元素定位的八种常用方式
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下 ...
- Selenium Webdriver元素定位的八种常用方式【转】
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下 ...
随机推荐
- AI来实现代码转换!Python转Java,Java转Go不在话下?
今天看到个有趣的网站,给大家分享一下. 该网站的功能很神奇,可以实现编程语言的转化.感觉在一些场景之下还是有点作用的,比如你原来跟我一样是做Java的,因为工作需要突然转Go.这个时候用你Java的经 ...
- jsp页面中的正则表达式--主要用于js判断文本格式
一.方括号[] 举例: 二.^ 三.元字符 举例的话,就可以这么说,要实现要表示整数的话: []就表示输入的文本框里面的数字的第一位,可以这么写--->[1-9] 然后已知\d表示的与[0-9] ...
- java多线程--6 死锁问题 锁Lock
java多线程--6 死锁问题 锁Lock 死锁问题 多个线程互相抱着对方需要的资源,然后形成僵持 死锁状态 package com.ssl.demo05; public class DeadLock ...
- flutter---->flutter orientation
Get the orientation 1. Media Query import 'package:flutter/material.dart'; void main() => runApp( ...
- TypeScript 学习总结
TypeScript JavaScript 语言 面向对象编程语言 面向脚本编程 是否支持可选参数 支持 不支持 是否支持静态类型 支持 不支持 是否支持接口 支持 不支持 TS:是JS的超集,即对J ...
- ArcGIS JS API加载带参数的rest服务参数被截掉问题处理
我们在做一些项目的时候,会对ArcGIS的图层服务进行转发,增加一些权限参数以保证数据访问的安全, 但使用ArcGIS JS API加载的时候,对于rest服务?后增加的参数会被截掉. 为解决这个问题 ...
- 搭建Hadoop2.7.2和Hive2.3.3以及Spark3.1.2
Hadoop 简介 Hadoop是一个用Java编写的Apache开源框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集.Hadoop框架工作的应用程序在跨计算机集群提供分布式存储和计算的环 ...
- day3 函数的定义和调用,练习编写简单的程序(记录3)
0331.h #ifndef _0331_H #define _0331_H /************************************************************ ...
- python之爬虫三
20xpath入门 在编写爬虫程序的过程中提取信息是非常重要的环节,但是有时使用正则表达式无法匹配到想要的信息,或者书写起来非常麻烦,此时就需要用另外一种数据解析方法,也就是本节要介绍的 Xpath ...
- 五月十四号java基础知识点
class Person{ private String name; private int age; public Person(String name,int age){ this.name = ...