Selenium:八种元素定位方法
前言:
我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素。工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素。那么我们怎么来定位他们呢?
在学习元素定位之前,我们最好能懂一点html的知识。
web driver提供了八种元素定位的方法:
| id | name | class name | tag name |
| link text | partial link text | xpath | css selector |
简单介绍:
# 通过ID定位目标元素
driver.find_element_by_id('i1') # 通过className定位目标元素
driver.find_element_by_class_name('c1') # 通过name属性定位目标元素
driver.find_element_by_name('n1') # 通过Xpath定位目标元素
driver.find_element_by_xpath('//*[@id="i1"]') # 通过css Selector定位目标元素
driver.find_element_by_css_selector('#i1') # 通过标签名称定位(注:在一个页面中,标签一定会重复,所以不用这个来进行定位)
driver.find_element_by_tag_name('input') # 通过标签中的文本查找元素
driver.find_element_by_link_text('登录') # 通过标签中文本的模糊匹配查找
driver.find_elements_by_partial_link_text('录')
详细解释:
1、id定位: find_element_by_id()
从上面定位到的搜索框属性中,有个id="kw"的属性,我们可以通过这个id定位到这个搜索框
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 启动浏览器
driver = webdriver.Chrome(executable_path='/usr/local/opt/drivers/chromedriver')
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过id定位搜索框,并输入selenium
driver.find_element_by_id('kw').send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
2、name定位: find_element_by_name()
从上面定位到的搜索框属性中,有个name="wd"的属性,我们可以通过这个name定位到这个搜索框
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过name定位搜索框,并输入selenium
driver.find_element_by_name('wd').send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
3、class定位:find_element_by_class_name()
从上面定位到的搜索框属性中,有个class="s_ipt"的属性,我们可以通过这个class定位到这个搜索框
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过class定位搜索框,并输入selenium
driver.find_element_by_class_name('s_ipt').send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
4、tag定位:find_element_by_tag_name()
如果懂HTML知识,我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等...。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行。下面代码仅做参考,运行时必定报错
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过tag定位搜索框,并输入selenium, 此处必报错
driver.find_element_by_tag_name('input').send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
5、link定位:find_element_by_link_text()
此种方法是专门用来定位文本链接的,比如百度首页右上角有“新闻”,“hao123”,“地图”等链接
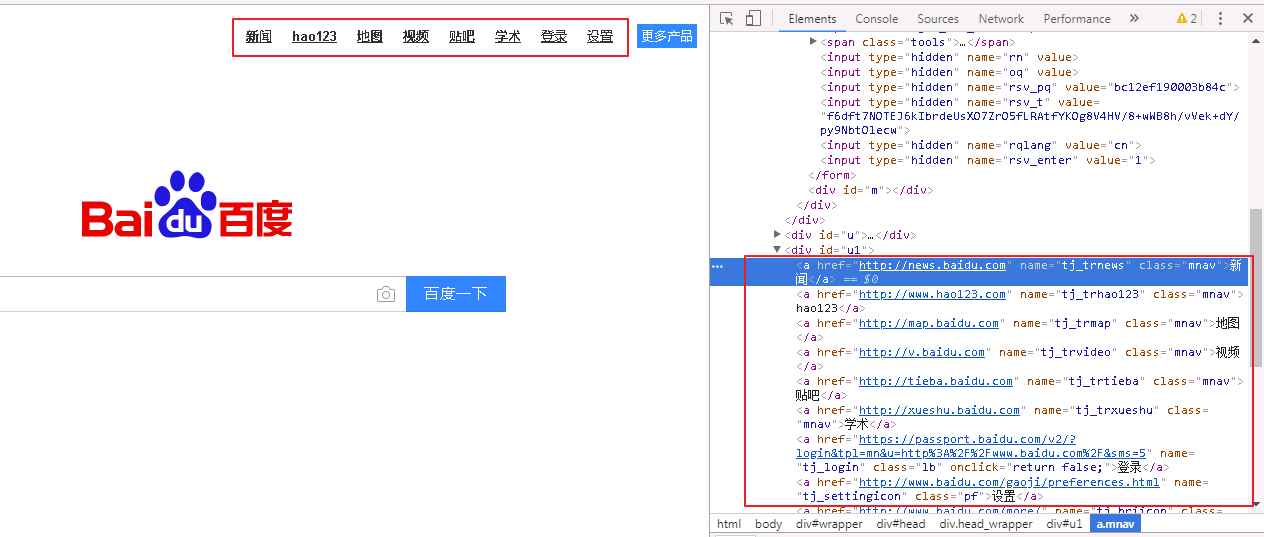
我们来定位“新闻”这个链接元素
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过link定位"新闻"这个链接并点击
driver.find_element_by_link_text('新闻').click()
# 等待5秒
sleep(5)
# 退出
driver.quit()
6、partial_link定位:find_element_by_partial_link_text()
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
我们用这种方法来定位百度首页的“新闻”超链接
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过partial_link定位"新闻"这个链接并点击
driver.find_element_by_partial_link_text('闻').click()
# 等待5秒
sleep(5)
# 退出
driver.quit()
7、xpath定位:find_element_by_xpath()
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过xpath定位搜索框,并输入selenium
driver.find_element_by_xpath("//*[@id='kw']").send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
8、CSS定位:find_element_by_css_selector()
这种方法相对xpath要简洁些,定位速度也要快些,但是学习起来会比较难理解,这里只做下简单的介绍。
CSS定位百度搜索框
# coding = utf-8
from time import sleep
from selenium import webdriver # 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过CSS定位搜索框,并输入selenium
driver.find_element_by_css_selector('#kw').send_keys('selenium')
# 等待5秒
sleep(5)
# 退出
driver.quit()
Selenium:八种元素定位方法的更多相关文章
- Selenium八种元素定位方法源码阅读
接触过Selenium的都知道元素定位有八种方法,但用不同的方法在执行时有什么区别呢? 元素定位8种方法(Python版),当然还有每一个方法对应的find_elements方法 find_eleme ...
- Selenium 八种元素定位方法
前言: 我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素.工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素.那么我们怎么来定位他们呢? 在学 ...
- selenium自动化测试——常见的八种元素定位方法
selenium常用的八种元素定位方法 1.通过 id 定位:find_element_by_id() 2.通过 name 定位:find_element_by_name() 3.通过 tag 定位: ...
- Selenium之WebDriver元素定位方法
Selenium WebDriver 只是 Python 的一个第三方框架, 和 Djangoweb 开发框架属于一个性质. webdriver 提供了八种元素定位方法,python语言中也有对应的方 ...
- Selenium2+python自动化-八种元素定位(Firebug和Firepath)
前言 自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告.本篇主要讲如何用firefox辅助工具进行元素定位.元素定位在这四个环节中 ...
- Selenium-webdriver+八种元素定位
进行Web页面自动化测试,对页面上的元素进行定位和操作是核心.而操作又是以定位为前提的,因此,对页面元素的定位是进行自动化测试的基础. 页面上的元素就像人一样,有各种属性,比如元素名字,元素id,元素 ...
- selenium自动化之元素定位方法
在使用selenium webdriver进行元素定位时,有8种基本元素定位方法(注意:并非只有8种,总共来说,有16种). 分别介绍如下: 1.name定位 (注意:必须确保name属性值在当前ht ...
- selenium常见的元素定位方法
一.获取元素 1)通过谷歌浏览器自动的工具访问百度首页,我们可以看到,页面上的元素都是由一行行的代码组成的,它们之间有层级地组织起来,每个元素之间都有不同的标签和值,我们可以通过这些不同的标签和值来找 ...
- Selenium八种基本定位方式---基于python
from selenium import webdriver driver=webdriver.Firefox() driver.get("https://www.baidu.com&qu ...
随机推荐
- seaborn教程2——颜色调控
原文转载 https://segmentfault.com/a/1190000014966210 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风 ...
- Vue小白篇 - Vue介绍
Vue ?啥是Vue?能干嘛? vue 的介绍 Vue 是一套用于构建用户界面的 渐进式框架 ,与其它大型框架不同的是, Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层 前端三大框 ...
- Jumpserver安装过程
Jumpserver 安装过程 可参照此官方文档搭建: http://docs.jumpserver.org/zh/docs/step_by_step.html 其中,需注意处: # docker ...
- 8VC Venture Cup 2017 - Elimination Round - C
题目链接:http://codeforces.com/contest/755/problem/C 题意:PolandBall 生活在一个森林模型的环境中,定义森林由若干树组成,定义树为K个点,K-1条 ...
- linux的定时任务--crontab
cron是一个linux下的定时执行工具,可以在无需人工干预的情况下运行作业.由于Cron 是Linux的内置服务,但它不自动起来,可以用以下的方法启动.关闭这个服务: /sbin/service c ...
- 第四章 走进jVM
4.1字节码 java文件编译成字节码后由默认解释执行,热点代码编译执行.方法调用到一定程度的时候,进行JIT编译成机器码执行,后面直接运行JIT编译结果(机器码). 4.2类加载过程 加载链接初始化 ...
- sd卡无法启动及zc706更改主频后可以进入uboot无法启动kernel的坑
好长的标题 +_+ 1.sd卡无法启动 起因:kernel底下通过dd测试速度,擦写了sd卡,再启动时发现无法启动 于是重新格式化,再将BOOT.bin 相关dtb u-rootfs zImage和u ...
- Echarts 自定义数据视图
toolbox : { show : true, feature : { dataView : { optionToContent : function(option) { // 行名称 var ax ...
- ARC101E Ribbons on Tree 容斥原理+dp
题目链接 https://atcoder.jp/contests/arc101/tasks/arc101_c 题解 直接容斥.题目要求每一条边都被覆盖,那么我们就容斥至少有几条边没有被覆盖. 那么没有 ...
- ThinkPHP import 类库导入 include PHP文件
ThinkPHP 模拟了 Java 的类库导入机制,统一采用 import 方法进行类文件的加载.import 方法是 ThinkPHP 内建的类库和文件导入方法,提供了方便和灵活的文件导入机制,完全 ...