centos-7部署kafka-v2.13.3.0.1集群
1、部署测试机器规划
| ip | kafka 版本 | zookeeper 版本 |
| 192.168.113.132 | v2.13.3.0.1 | v3.6.3 |
| 192.168.113.135 | v2.13.3.0.1 | v3.6.3 |
| 192.168.113.136 | v2.13.3.0.1 | v3.6.3 |
kafka下载官网:https://kafka.apache.org/downloads.html
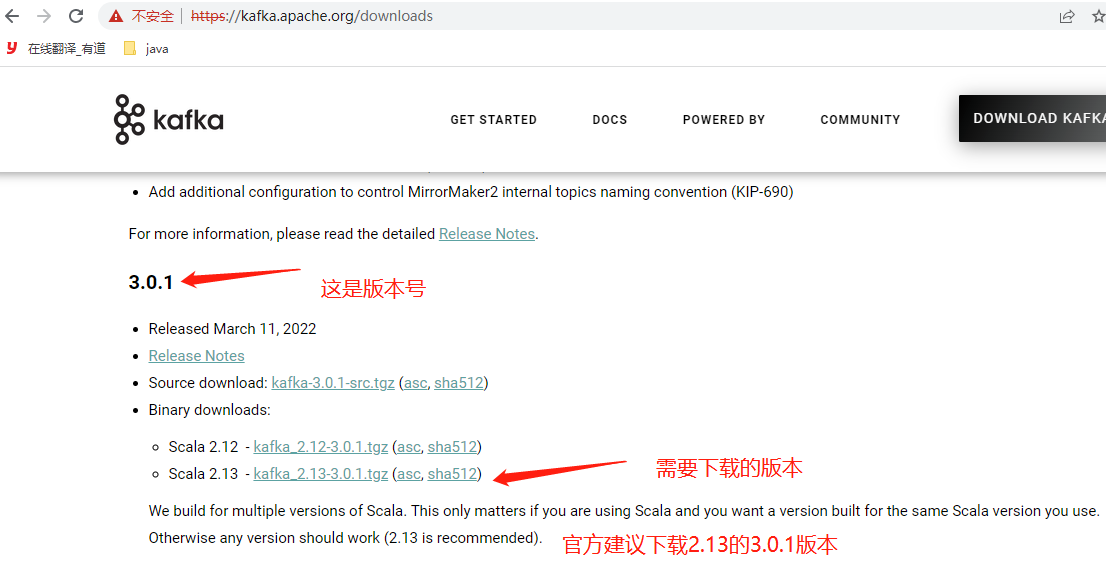
[root@localhost ~]# cd /opt/ #计划安装kafka的位置
[root@localhost opt]# wget https://archive.apache.org/dist/kafka/3.0.1/kafka_2.13-3.0.1.tgz #下载包
[root@localhost opt]# tar xf kafka_2.13-3.0.1.tgz #解压
[root@localhost opt]# mv kafka_2.13-3.0.1/ kafka #重命名
[root@localhost opt]# ls kafka/libs/ #查看kfaka的包名查看zk的版本,如果不使用kafka包里面自带的zk服务,自己搭建的话,最好下载对应版本的zk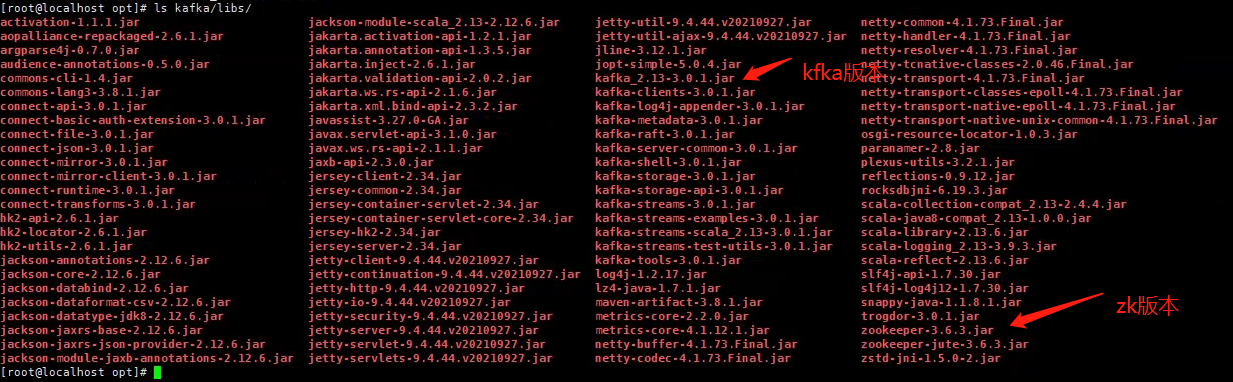
zookeeper下载官网:http://zookeeper.apache.org/
下载二进制包

每台节点执行操作
[root@localhost ~]# cd /opt/
[root@localhost opt]# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz --no-check-certificate
[root@localhost opt]# tar xf apache-zookeeper-3.6.3-bin.tar.gz
[root@localhost opt]# mv apache-zookeeper-3.6.3-bin zookeeper2、使用二进制安装zookeeper集群
应用场景:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
kafka需要使用zookeeper来进行调度所以首先安装,也可以不单独安装直接使用kafka包里面的zookeeper进行配置启动,但是建议单独安装
2.1、前面已经将包下载好并解压重命名了,接下来进行配置zookeeper
没安装jdk的先安装jdk,我这里是yum安装的也可以下载二进制包进行
[root@localhost conf]# yum -y install java-1.8.0-openjdk*对每台节点进行操作
[root@localhost opt]# cd zookeeper/conf/ #切换目录
[root@localhost conf]# ls #查看配置文件
configuration.xsl log4j.properties zoo_sample.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg #拷贝配置文件并重命名
[root@localhost conf]# vim zoo.cfg #编辑配置文件进行修改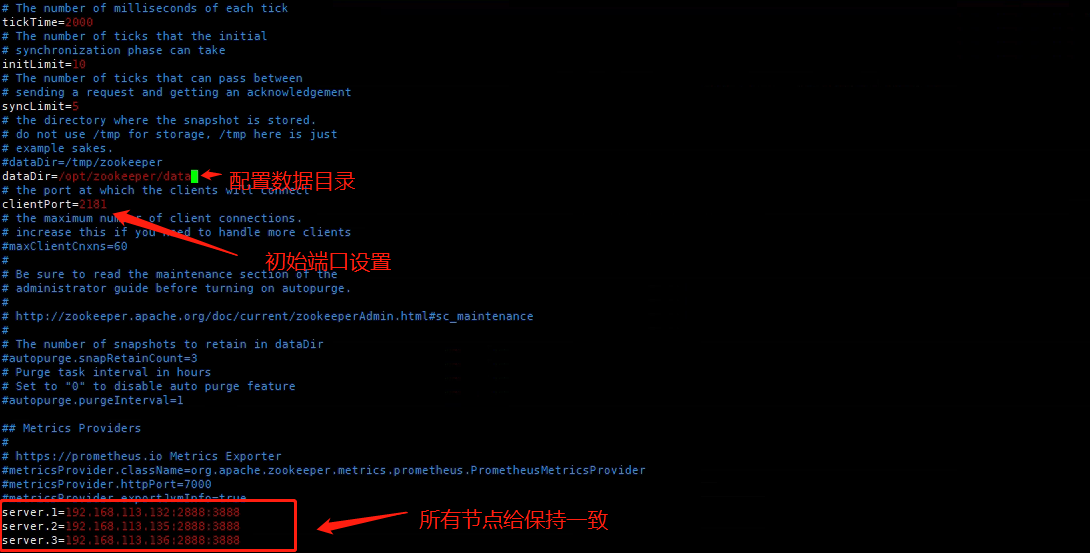
注意!zk-3.6过后的版本在开启服务器后会默认占用8080端口
可以修改配置来修改端口
# admin.serverPort 默认占8080端口
admin.serverPort=88882.2、添加myid文件这个配置是区分节点的
[root@localhost conf]# mkdir /opt/zookeeper/data
[root@localhost conf]# vim /opt/zookeeper/data/myid
[root@localhost conf]# echo 1 > /opt/zookeeper/data/myid #分别给三个server节点定向一个编号到myid文件里面(1 2 3)来进行节点区分
切换到启动目录
[root@localhost zookeeper]# cd /opt/zookeeper/bin/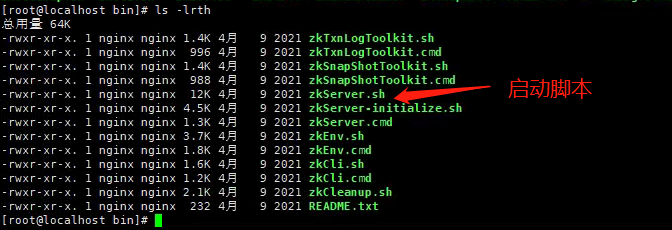
启动zk
[root@localhost bin]# /opt/zookeeper/bin/zkServer.sh start #源码包安装的方式需要指定配置文件查看启动状态

提示下面错误表示没有关闭selinux或者防火墙(或者直接配置iptables规则)
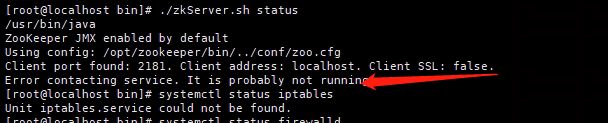
关闭防火墙跟selinux后状态正常(这是被分配到的从节点)

再看看分配到的主节点(leader)

zkCli.sh客户端使用
[root@localhost bin]# ./zkCli.sh -server 192.168.113.135:2181 #连接本机
[root@localhost bin]# ./zkCli.sh -server 192.168.113.135 #不适用端口连接本机,默认去连接2181端口
[root@localhost bin]# ./zkCli.sh -server 192.168.113.132:2181 #连接到其他机器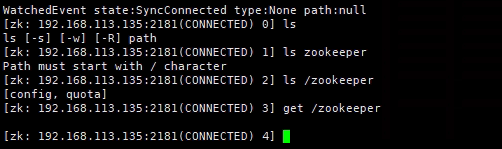
2.3、为了安全起见可以给zk集群添加ip白名单,本来zk只是kafka使用只需要集群ip能访问就可以了
登陆zookeeper
进入zookeeper安装目录下的bin目录下执行
./zkCli.sh -server ip:port
./zkCli.sh -server 192.168.113.135:2181 #例!在bin目录下面执行,进入集群的任意一台zk查看当前权限,未配置会提示允许所有
getAcl /添加可访问IP
setAcl / ip:192.168.113.132:cdrwa,ip:192.168.113.135:cdrwa,ip:192.168.113.136:cdrwa,ip:127.0.0.1:cdrwa注:1.在设置IP白名单时,将本机ip 127.0.0.1也加上,让本机也可以访问及修改
在第一次添加完ip白名单后,又想继续添加白名单,则在设置的时候,以前的ip也都是写在命令里,不然以前添加的都会被覆盖掉,那就坑了
查看是否正常添加
getAcl /如果要恢复所有ip皆可访问,则执行
setAcl / world:anyone:cdrwa3、配置kafka
[root@localhost opt]# cd /opt/kafka/config/
[root@localhost config]# vim /opt/kafka/config/server.properties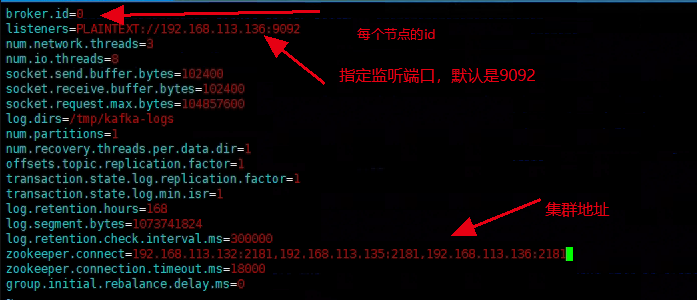
注意!:log.dirs在生产中不要配置到tmp目录下面不然系统定时清理掉这个下面的文件会导致系统崩溃。
启动kafka
[root@localhost ~]# nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties 1> /dev/null 2>&1 &测试创建topic
[root@localhost bin]# ./kafka-topics.sh --create --topic quickstart-events --bootstrap-server 192.168.113.132:9092查看topic
[root@localhost bin]# ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 192.168.113.132:9092
生产者:发送消息
[root@localhost bin]# ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server 192.168.113.132:9092消费者:处理消息
[root@localhost bin]# ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server 192.168.113.132:9092命令使用拓展
指定创建多个副本及分区
./kafka-topics.sh --create --replication-factor 2 --partitions 4 --topic quickstart-events --bootstrap-server 192.168.113.132:9092
# --replication-factor 参数是指定副本数
# --partitions 指定分区动态调整分区只能网上调不能向下
./kafka-topics.sh --alter --bootstrap-server 192.168.113.132:9092 --topic quickstart-events --partitions 12删除topic
./kafka-topics.sh --delete --bootstrap-server 192.168.113.132:9092 --topic quickstart-events kafka查看所有组
./kafka-consumer-groups.sh --bootstrap-server 192.168.113.132:9092 --list查看topIc消费组consumer的积压情况
./kafka-consumer-groups.sh --bootstrap-server 192.168.113.132:9092 --describe --group +需要查询的groupcentos-7部署kafka-v2.13.3.0.1集群的更多相关文章
- K8S学习笔记之二进制部署Kubernetes v1.13.4 高可用集群
0x00 概述 本次采用二进制文件方式部署,本文过程写成了更详细更多可选方案的ansible部署方案 https://github.com/zhangguanzhang/Kubernetes-ansi ...
- 2、kubeadm快速部署kubernetes(v1.15.0)集群190623
一.网络规划 节点网络:192.168.100.0/24 Service网络:10.96.0.0/12 Pod网络(默认):10.244.0.0/16 二.组件分布及节点规划 master(192.1 ...
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- [转帖]Breeze部署kubernetes1.13.2高可用集群
Breeze部署kubernetes1.13.2高可用集群 2019年07月23日 10:51:41 willblog 阅读数 673 标签: kubernetes 更多 个人分类: kubernet ...
- kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)
一.准备三台服务器,配置好主机名和ip地址 二.服务器初始化:包括安装常用命令工具,修改系统时区,校对系统时间,关闭selinux,关闭firewalld,修改主机名,修改系统文件描述符,优化内核参数 ...
- Storm1.0.3集群部署
Storm集群部署 所有集群部署的基本流程都差不多:下载安装包并上传.解压安装包并配置环境变量.修改配置文件.分发安装包.启动集群.查看集群是否部署成功. 1.所有的集群上都要配置hosts vi ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- lvs+keepalived部署k8s v1.16.4高可用集群
一.部署环境 1.1 主机列表 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 lvs-keepal ...
- Centos7.6部署k8s v1.16.4高可用集群(主备模式)
一.部署环境 主机列表: 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 master01 7.6. ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
随机推荐
- 最新2019Java调用百度智能云人脸识别流程
首先先注册账户 https://console.bce.baidu.com/?fromai=1#/aip/overview 点击链接 有账户直接登录 如无 则注册 进入控制台后 点击人脸识别 随便选 ...
- Kubernetes--容器重启策略和Pod终止过程
容器的重启策略 容器程序发生崩溃或容器申请超出限制的资源等原因都可能会导致Pod对象的终止,此时是否应该重建该Pod对象则取决于其重启策咯(restartPolicy)属性的定义. 1)Always: ...
- 【RTOS】RTOS汇编入门 (1)
引言 为了提高效率,进行更为底层的操作,RTOS常采用汇编语句,因此了解常用的汇编语句,很有必要 汇编指令 1..equ:类似于c中的#define,表声明常量 例如:.equ PSW 0x10000 ...
- jdbc(工具类和配置文件)
原始的jdbc要操作7步 导入jar包 加载驱动 获取连接 获取执行者对象 编写sql语句 处理结果 释放对象资源 当我们每次都要注册驱动,获取连接的时候,都感觉很烦,这时候怎么才能懒呢? 把driv ...
- Jmeter学习:插件
第三方插件官方下载网址:https://jmeter-plugins.org/install/Install/ 第三方插件官方文档网址:https://jmeter-plugins.org/wiki/ ...
- 剑指 Offer II 二分查找
068. 查找插入位置 class Solution { public: int searchInsert(vector<int>& nums, int target) { int ...
- 实验1task4
<实验结论> #include <stdio.h> #include <stdlib.h> int main() { int x, t, m; x = 123; p ...
- python exec_command 命令无效的原因
当使用Python Paramiko exec_command执行时,某些Unix命令失败并显示"未找到"_互联网集市 (qyyshop.com) 链接里的解释解决了问题 本来直接 ...
- 在线访问GET/POST及格式化json工具
http://coolaf.com/在线访问及格式化json工具谷歌浏览器json插件不是很好实现.安装,替代方案
- JAVA格式化数字
DecimalFormat df = new DecimalFormat("#.##"); System.out.println(df.format(100.1234)); // ...