JDK1.7HashMap源码分析
1.1首先HashMap中的Hash(哈希)是什么?
Hash也称散列,哈希,对应的英文都是Hash。基本原理就是把任意长度的输入通过Hash算法变成固定长度的输出,这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制就是哈希值。开发中经常使用的MD5和SHA都是属于Hash算法
MD5方法加密后的你好
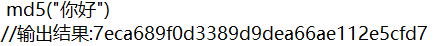
在这个例子里 "你好" 是原始值, "7eca689f0d3389d9dea66ae112e5cfd7" 就是经过Hash算法得到的Hash值。整个Hash算法的过程就是把原始任意长度的值变成固定长度的值的过程。
1.2Hash算法的特点
1.Hash不可以反推导出原始的数据从上面的例子就可以看出经过Hash算法计算过的值和原始的数据是没有对应关系的。
2.输入数据的微小变化会得到不同的Hash值,相同的数据会获得相同的值,

这里就可以看到我们只加了一个数字1,但是整个获得的Hash值发生了非常大的变化。
3.Hash算法的执行效率要高效,就算是很长的文本信息也能够快速的计算出Hash值。
1.3Hash的用途
由于哈希的不可逆的特性使其能在以下的领域使用:
1. 密码:我们日常使用的各种电子密码本质上都是基于hash的,你不用担心支付宝的工作人员会把你的密码泄漏给第三方,因为你的登录密码是先经过 hash+各种复杂算法得出密文后 再存进支付宝的数据库里的。
2.文件完整性校验:通过对文件进行hash,得出一段hash值 ,这样文件内容以后被修改了,hash值就会变。
3.数字签名:数字签名技术是将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。
此外还有区块链领域Hash算法也使用广泛。
1.4哈希表是什么?
说哈希表前要先说一下数组和链表
数组是在内存中的一片连续区域,同类型数据的集合,有索引,查询快,增删慢,不可扩容
链表是不连续的区域,每个节点放值和指向下一个节点的指针。查询慢,增删快。
而哈希表可以理解为数组和链表的结合,即一个一维数组,但是数组中的每一个元素是一个链表。
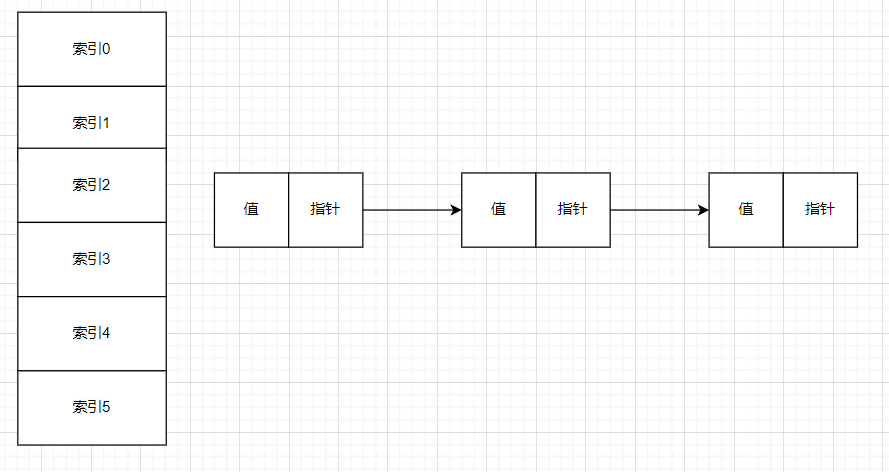
1.5为什么使用哈希表
首先我们有六个箱子(长度为6的数组)存储了数据
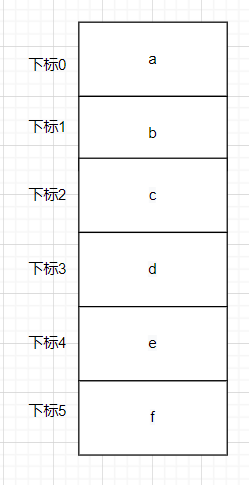
如果我们想查询这个数组里的 f 但是我们不知道 f 存储在哪个箱子里 只能从头开始查询这个操作叫做线性查询
于是从0号箱子先开始查询,这时候发现0号箱子里装的并不是 f 而是 a ,因此继续查找1号箱子 直到查找5号箱子的时候发现里面装的是 f
但是这样查找下来我们会发现数据量越大,查找消耗的时间就越长因此我们就得知了由于数据的查询比较耗时,所以这里不适合使用数组来存储数据。
所以这时候我们使用哈希表就可以解决这个问题,首先准备好数组,我们准备用五个箱子的数组来存储数据
如果我们想把one存入进去我们使用Hash计算one的值也就是字符one的哈希值比如得到的是4928,将得到的哈希值除以数组长度的5,求得的余数,这样的求余运算叫做mod运算
这里得到的结果是3。
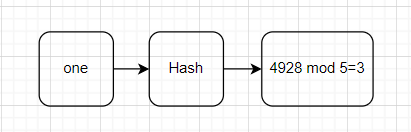
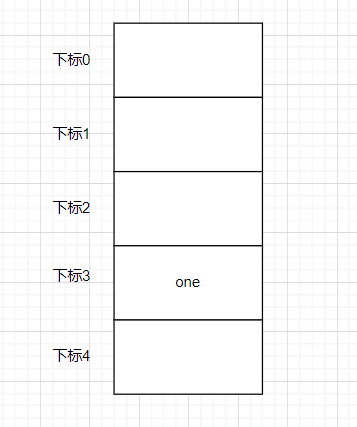
于是我们将one的数据装进三号箱子里,重复前面的操作,将其他数据都存进数组中
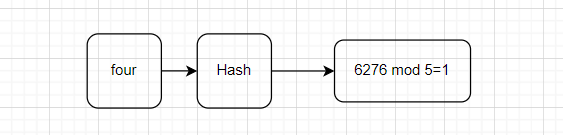
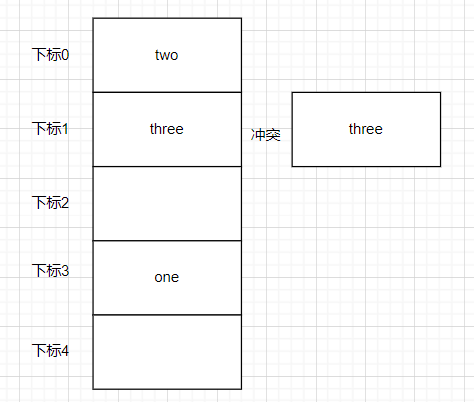
但是当我们存入four键的哈希值经过计算后结果为1本应存入一号箱子中,但是此时一号箱子已经存储了three的数据,在哈希表中这种存储位置重复的情况叫冲突。
这时候我们可以使用链表在已有的数据后面继续存储新的数据
那么在哈希表中,我们可以利用哈希函数快速访问到数组中的目标。如果发生哈希冲突就使用链表进行存储,如果数组的空间太小,使用哈希表的时候就容易发生冲突,线性查找的使用频率会更高,反过来,如果数组的空间太大,就会出现很多空箱子,造成内存浪费。因此给数组设置合适的空间非常重要。
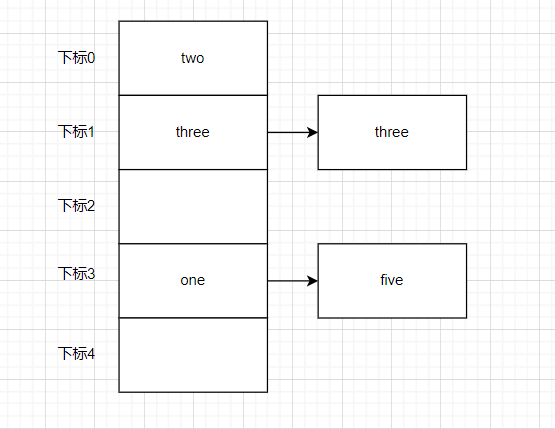
1.6哈希冲突的四种解决方法
第一种开放定址法(再散列法):
开发定址法就是一旦发生冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1)
比如说我们有一个集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。我们用散列函数f(key) = key mod 12
当计算前几个数的时候是都的没有发生冲突的散列地址直接存入

可是当我们计算key = 37 时发现 f(37) = 1 ,此时就与25所在的位置冲突,于是我们应用上面的公式f(37) = (f(37) + 1) mod 12 = 2。于是将37存入下标为二的位置

2. 再哈希法:
当有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,. . . , 等哈希函数
计算地址,直至无冲突。虽然不易发生聚集,但是增加了计算时间。
3.链地址法:
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来。
4.建立公共溢出区:
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
1.7HashMap源码JDK1.7
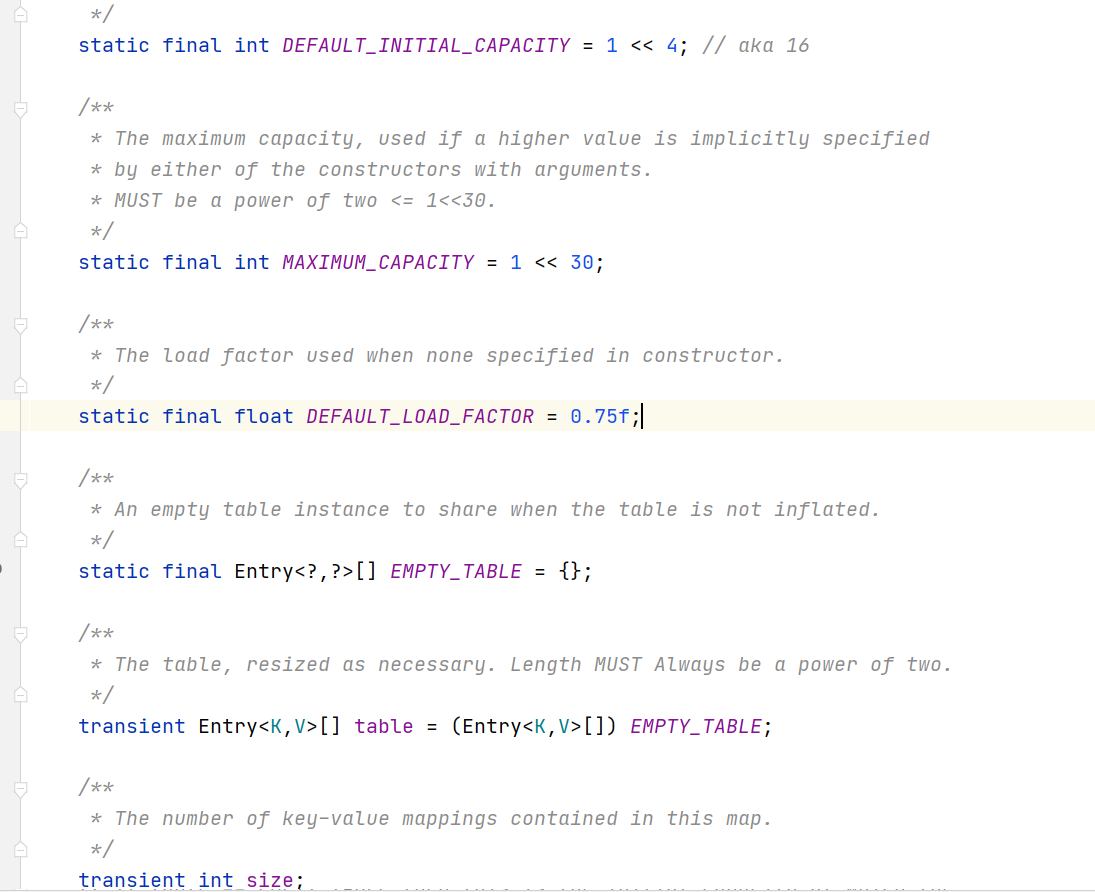
以上是定义的常量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; 默认初始容量,为2的四次方 16。
static final int MAXIMUM_CAPACITY = 1 << 30; 最大容量为2的三十次方。
static final float DEFAULT_LOAD_FACTOR = 0.75f; 默认的负载因子(扩容因子) 0.75。
static final Entry<?,?>[] EMPTY_TABLE = {}; 一个空数组。
transient int size; 这个是键值对的个数。
构造方法
HashMap有三个构造方法,我们经常用到是第三个无参构造方法。
第一个构造方法需要传入自定义的负载因子与容器大小。
第二个构造方法也是要传入一个自定义的负载因子而容器的初始大小为16。

put方法
1 public V put(K key, V value) {
2 if (table == EMPTY_TABLE) { //首先判断内容是否是空的,tbale是一个默认为空的键值对数组。
3 inflateTable(threshold); //如果内容是空的那么就进行初始化。
4 }
5 if (key == null) //判断传入的键是否为空
6 return putForNullKey(value); //如果为空就调用这个方法
7 int hash = hash(key); //如果键不为空就计算键的Hash值
8 int i = indexFor(hash, table.length); //根据计算后的Hash值和数组的长度计算索引,就是这个键要存入的位置。
9 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //循环遍历数组,数组上每个元素都是一个链表。
//这时我们已经获得索引就遍历索引上的链表,这样做是为了检查传进来的key是否存在在表里了
10 Object k;
11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //判断如果传进来的key和链表上的元素 Hash,地址,内容都一样那么说明已经存在在表里了
12 V oldValue = e.value; //那么就保持key不变,更新value 并且返回旧的value
13 e.value = value;
14 e.recordAccess(this);
15 return oldValue;
16 }
17 }
18
19 modCount++;//被修改次数加一,这个值主要是为了线程安全考虑,和本方法的业务无关
20 addEntry(hash, key, value, i);//创建一个节点到数组上
21 return null;
22 }
初始方法 inflateTable(threshold) 做了些什么

private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); //初始化时无论存入的初始容量值是多少都会向上取整变为2的幂。也就是我们看到有一个构造方法可以让用户去自定义容量大小
但是传进来的容量也会向上取整变成2的密。在这里可以看见他做了一个-1的操作是为了防止把正确的容量翻一倍比如你传进来的是15,那么向上取整为16.如果传进来的是16,向上取整就成了32。
所以在任何数取整时先-1。
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //计算扩容值
table = new Entry[capacity]; //初始化
initHashSeedAsNeeded(capacity);
}
如果key为null的时候做了什么
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {//首先循环遍历如果发现链表里还有null,那么就替换value,也就是说key可以为空,但是只能有一个。
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);//如果第一次插入的key为null的元素就直接保存到索引为0的位置上
return null;
}
在JDK1.7中插入数据采用的是头插法,新来的元素会加在链表的开头,类似于栈。因为开发者认为后加的元素可能被用到的几率更大,所以头插法可以快速查询。
当然这也带来了安全隐患,就是在多线程环境下,可能会出现死循环。
for循环的数组如果数据很大.执行到Entry<K,V> next = e.next; 之后,既next的指针已经被记录,并在最后指向了下一次要循环的e.
突然.被阻塞.另一个线程过来,对同一个e对象进行了赋值,此时进行1到7步的操作,链表的数据都被插入到了新的索引下标,并且头插法将数据由原来的顺序变为倒序,
而原始指向的e.next对象已经有原来的头节点变为了尾节点,此时继续走1到7步.会产生原来的头结点和尾节点相互next指向.既发生死锁(自旋操作)
有可能在下次get的时候出现死循环的问题。
因为没有加锁,所以在多个线程并发的时候,不能保证数据是安全的.就是我put进去的一个值,不能保证我get的时候还是原来的值。
为了解决这个问题,jdk8采用了尾插法。不过HashMap本身就不是线程安全的,所以不建议在多线程下用。
小结:
1.jdk1.7采用数组+单向链表的数据结构进行存储数据,好处是便于解决hash冲突,坏处是可能增大get元素的遍历成本。
2.插入链表数据时采用头插法来进行插入。
3.hash寻址计算索引下表是通过hashCode计算出来的hash值跟集合的length-1进行与操作算出来的。
4.put时没有加锁,会导致get时不一定是自己添加的值。
以上就是我对JDK1.7HashMap的源码分析了,JDK1.8我会新写一篇文章。。。。。。。。
JDK1.7HashMap源码分析的更多相关文章
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 【JUC】JDK1.8源码分析之ArrayBlockingQueue(三)
一.前言 在完成Map下的并发集合后,现在来分析ArrayBlockingQueue,ArrayBlockingQueue可以用作一个阻塞型队列,支持多任务并发操作,有了之前看源码的积累,再看Arra ...
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之LinkedHashSet(含JDK1.8源码分析)
一.前言 上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的. 二.linkedHas ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- 【1】【JUC】JDK1.8源码分析之ArrayBlockingQueue,LinkedBlockingQueue
概要: ArrayBlockingQueue的内部是通过一个可重入锁ReentrantLock和两个Condition条件对象来实现阻塞 注意这两个Condition即ReentrantLock的Co ...
- 【1】【JUC】JDK1.8源码分析之ReentrantLock
概要: ReentrantLock类内部总共存在Sync.NonfairSync.FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQ ...
随机推荐
- 假期任务一:安装好JAVA开发环境并且在Eclipse上面成功运行HelloWorld程序
(本周主要做了java环境的安装,安装完jdk后又安装了eclipse,平均每天两小时Java吧,这周敲代码的时间比较少,大多是在b站看java入门视频和菜鸟教程的基础语法,也就打开eclipse验证 ...
- 搭建 SpringBoot 项目(前端页面 + 数据库 + 实现源码)
SpringBoot 项目整合源码 SpringBoot 项目整合 一.项目准备 1.1 快速创建 SpringBoot 项目 1.2 项目结构图如下 1.3 数据表结构图如下 1.4 运行结果 二. ...
- Java中重载的应用
学习目标: 掌握Java方法的重载 学习内容: 1.重载定义 参数列表: 参数的类型 + 参数的个数 + 参数的顺序 方法签名: 方法名称 + 方法参数列表,在同一个类中,方法签名是唯一的,否则编译报 ...
- thymeleaf的具体语法
thymeleaf模板引擎是什么?请点击我查看 文章目录 thymeleaf模板引擎是什么?请点击我查看 代码 该实例代码延续[thymeleaf模板引擎](https://blog.csdn.net ...
- 微服务状态之python巡查脚本开发
背景 由于后端微服务架构,于是各种业务被拆分为多个服务,服务之间的调用采用RPC接口,而Nacos作为注册中心,可以监听多个服务的状态,比如某个服务是否down掉了.某个服务的访问地址是否改变.以及流 ...
- PDCA循环——快速提升软件质量的必备工具
近年来,软件项目的规模及其复杂性正在以空前的速度增长,互联网用户市场庞大,互联网公司和相应的软件产品层出不穷.快速响应需求变化往往是互联网行业的常态,软件产品的快速开发迭代对于公司迅速占领市场.抢占商 ...
- 忘记VMware vcenter的Administrator@vsphere.local密码
忘记VMware vcenter的Administrator@vsphere.local密码的解决办法一. 重置密码:ssh root@192.168.230.100Connecting to 192 ...
- HTTP协议4.14
测试开发学习笔记 一. Saas software as a service 软件即服务 Platform as a service 平台即服务 单体架构---垂直架构---面向服务架构---微服务架 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- [题解] 序列(sequence)
题目大意 给定一个长度为 \(N\) 的非负整数序列 \(A_1,A_2, \ldots ,A_N\),和一个正整数 \(M\).序列 \(A\) 满足 \(\forall 1 \le i \ ...