<node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友。
目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。
思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。
步骤一:安装node.js
下载并安装node,此步骤比较简单就不详细解释了,有问题的可以直接问一下度娘。
步骤二:建立工程
1)打开dos命令条,cd进入想要创建项目的路径(我将此项目直接放在了E盘,以下皆以此路径为例);
2)mkdir node (创建一个文件夹用来存放项目,我这里取名为node);
3)cd 进入名为node的文件夹,并执行npm init初始化工程(期间会让填写一些信息,我是直接回车的);
步骤三:创建爬取到的数据存放的文件夹
1)创建data文件夹用来存放发型师基本信息;
2)创建image文件夹用来存储发型师头像图片;
此时工程下文件如下:

步骤四:安装第三方依赖包(fs是内置模块,不需要单独安装)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分别简单解释一下上面安装的依赖包:
cheerio:是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现,则能够对请求结果进行解析,解析方式和jQuery的解析方式几乎完全相同;
superagent:能够实现主动发起get/post/delete等请求;
async:async模块是为了解决嵌套金字塔,和异步流程控制而生,由于nodejs是异步编程模型,有一些在同步编程中很容易做到的事情,现在却变得很麻烦。Async的流程控制就是为了简化这些操作;
request:有了这个模块,http请求变的超简单,Request使用简单,同时支持https和重定向;
步骤五:编写爬虫程序代码
打开hz.js,编写代码:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require('request');
var page=1; //获取发型师处有分页功能,所以用该变量控制分页
var num = 0;//爬取到的信息总条数
var storeid = 1;//门店ID
console.log('爬虫程序开始运行......');
function fetchPage(x) { //封装函数
startRequest(x);
}
function startRequest(x) {
superagent
.post('http://tweixin.yueyishujia.com/v2/store/designer.json')
.send({
// 请求的表单信息Form data
page : x,
storeid : storeid
})
// Http请求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 请求返回后的处理
// 将response中返回的结果转换成JSON对象
if(err){
console.log(err);
}else{
var designJson = JSON.parse(res.text);
var deslist = designJson.data.designerlist;
if(deslist.length > 0){
num += deslist.length;
// 并发遍历deslist对象
async.mapLimit(deslist, 5,
function (hair, callback) {
// 对每个对象的处理逻辑
console.log('...正在抓取数据ID:'+hair.id+'----发型师:'+hair.name);
saveImg(hair,callback);
},
function (err, result) {
console.log('...累计抓取的信息数→→' + num);
}
);
page++;
fetchPage(page);
}else{
if(page == 1){
console.log('...爬虫程序运行结束~~~~~~~');
console.log('...本次共爬取数据'+num+'条...');
return;
}
storeid += 1;
page = 1;
fetchPage(page);
}
}
});
}
fetchPage(page);
function saveImg(hair,callback){
// 存储图片
var img_filename = hair.store.name+'-'+hair.name + '.png';
var img_src = 'http://photo.yueyishujia.com:8112' + hair.avatar; //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}else{
request(img_src).pipe(fs.createWriteStream('./image/' + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用发型师的姓名和所属门店作为图片的名称。
console.log('...存储id='+hair.id+'相关图片成功!');
}
});
// 存储照片相关信息
var html = '姓名:'+hair.name+'<br>职业:'+hair.jobtype+'<br>职业等级:'+hair.jobtitle+'<br>简介:'+hair.simpleinfo+'<br>个性签名:'+hair.info+'<br>剪发价格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>联系方式:'+hair.telephone+'<br>头像:<img src='+img_src+' style="width:200px;height:200px;">';
fs.appendFile('./data/' +hair.store.name+'-'+ hair.name + '.html', html, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
callback(null, hair);
}
步骤六:运行爬虫程序
输入node hz.js命令运行爬虫程序,效果图如下:
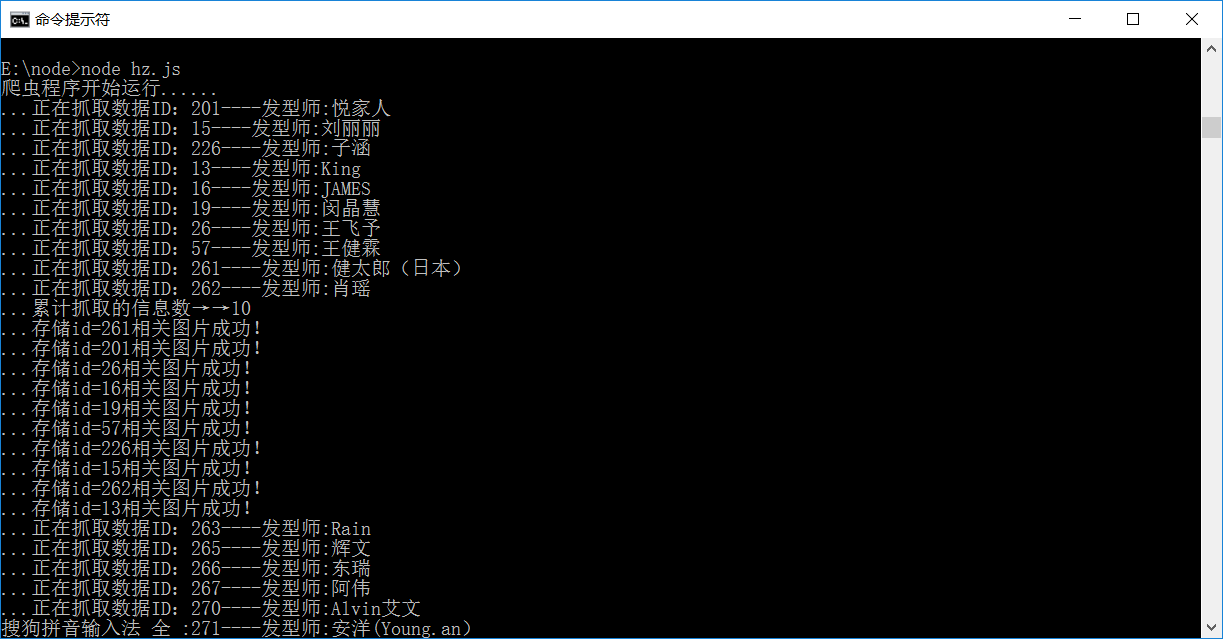
运行成功后,发型师基本信息以html文件的形式存储在data文件夹中,发型师头像图片存储在image文件夹下:
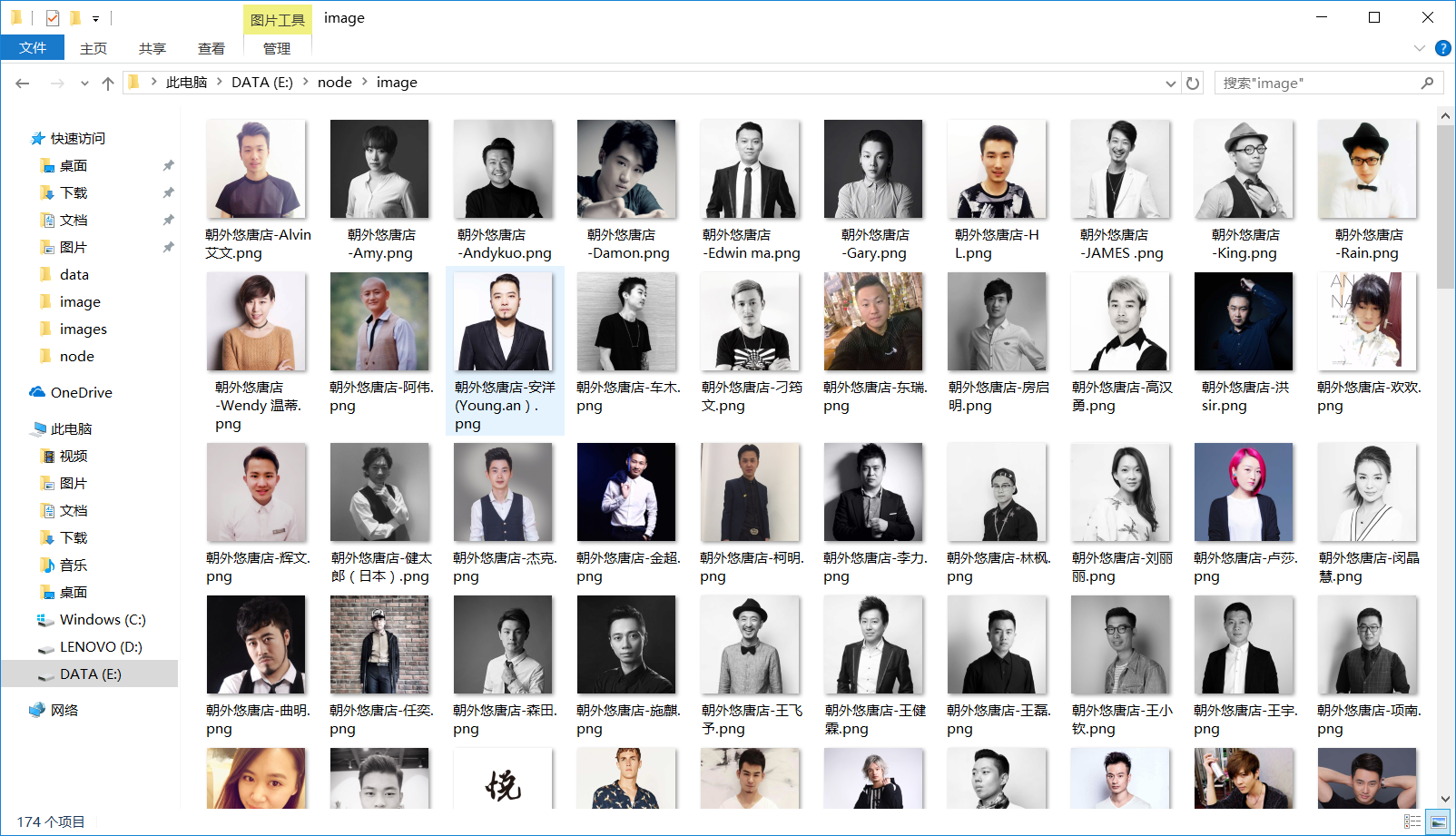
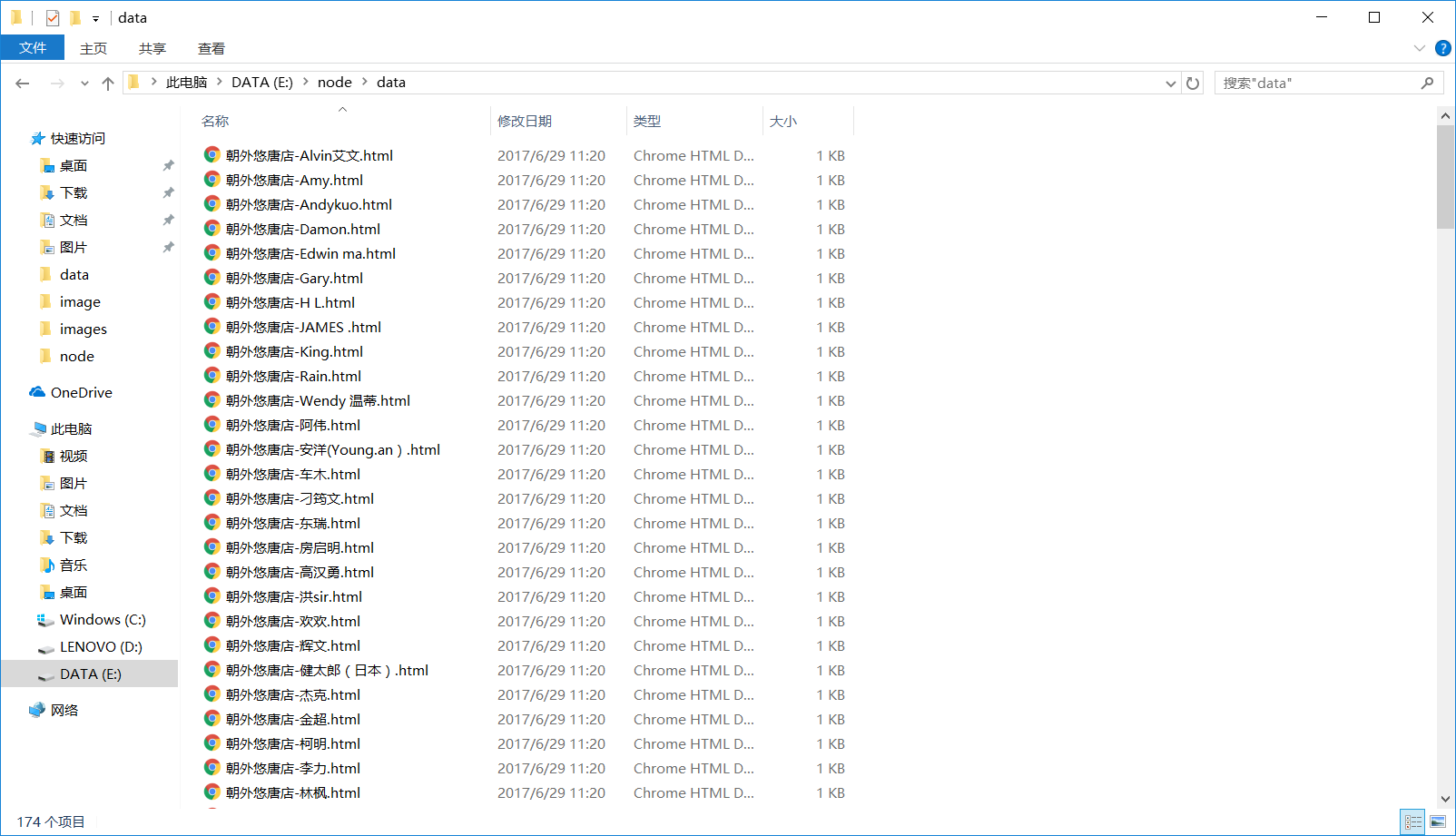
后记:到此一款基于node.js制作的简单爬虫就大功告成了,由于我也是初学者,好多地方也不是很理解,但好在是自己完成了,不足之处敬请谅解。
代码下载地址:https://github.com/yanglei0323/nodeCrawler
<node.js爬虫>制作教程的更多相关文章
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
随机推荐
- C++并发编程 互斥和同步
C++并发编程 异步任务(async) 线程基本的互斥和同步工具类, 主要包括: std::mutex 类 std::recursive_mutex 类 std::timed_mutex 类 std: ...
- Java设计模式の模版方法模式
概述 模板方法模式是类的行为模式.准备一个抽象类,将部分逻辑以具体方法以及具体构造函数的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑.不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的 ...
- [LeetCode] 30. Substring with Concatenation of All Words ☆☆☆
You are given a string, s, and a list of words, words, that are all of the same length. Find all sta ...
- Python进行数据分析(二)MovieLens 1M 数据集
# -*- coding: utf-8 -*- """ Created on Thu Sep 21 12:24:37 2017 @author: Douzi " ...
- 修复 Plugin execution not covered by lifecycle configuration: org.codehaus.mojo:build-helper-maven-plugin:1.8:add-source (execution: add-source, phase: generate-sources)
在maven项目中使用add-source时,pom.xml报如下错误: Plugin execution not covered by lifecycle configuration: org.co ...
- Appium修改源码后重新编译
按照官方的说明下载源码,安装依赖库,具体可从这来: https://github.com/appium/appium/blob/master/docs/en/contributing-to-appiu ...
- Amcharts 柱状图和线形图
最近需要学习 Amcharts ,他的图表功能确实很强大.但是网上搜索到的教程很少,开始学起的确有点不方便.于是我决定把我学习的觉得好的途径,放到博客上. 下面的代码可以直接复制,但是文件要从官网上下 ...
- 【转】CentOS7 yum方式配置LAMP环境
采用Yum方式搭建: Apache+Mysql+PHP环境 原文地址: http://www.cnblogs.com/zutbaz/p/4420791.html 1.安装Apache yum inst ...
- HDU 2516 取石子游戏 (找规律)
题目链接 Problem Description 1堆石子有n个,两人轮流取.先取者第1次可以取任意多个,但不能全部取完.以后每次取的石子数不能超过上次取子数的2倍.取完者胜.先取者负输出" ...
- 127.0.0.1、localhost、0.0.0.0的区别
在开发web应用的测试环境中,如果希望同一个局域网的同事通过内网IP访问自己的应用,则需要把web服务监听的ip地址改为0.0.0.0.为什么用127.0.0.1不行,而用0.0.0.0就可以呢? f ...