scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式。
我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫,并且把数据都存储到同一个数据库,那不是美滋滋,速度也得到了很大的提升。
要实现分布式,只需要对settings.py文件进行适当的配置就能完成。
文档时间:官方文档介绍如下:
Use the following settings in your project:
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Default requests serializer is pickle, but it can be changed to any module
# with loads and dumps functions. Note that pickle is not compatible between
# python versions.
# Caveat: In python 3.x, the serializer must return strings keys and support
# bytes as values. Because of this reason the json or msgpack module will not
# work by default. In python 2.x there is no such issue and you can use
# 'json' or 'msgpack' as serializers.
#SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # Don't cleanup redis queues, allows to pause/resume crawls.
#SCHEDULER_PERSIST = True # Schedule requests using a priority queue. (default)
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # Alternative queues.
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # Max idle time to prevent the spider from being closed when distributed crawling.
# This only works if queue class is SpiderQueue or SpiderStack,
# and may also block the same time when your spider start at the first time (because the queue is empty).
#SCHEDULER_IDLE_BEFORE_CLOSE = 10 # Store scraped item in redis for post-processing.
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
} # The item pipeline serializes and stores the items in this redis key.
#REDIS_ITEMS_KEY = '%(spider)s:items' # The items serializer is by default ScrapyJSONEncoder. You can use any
# importable path to a callable object.
#REDIS_ITEMS_SERIALIZER = 'json.dumps' # Specify the host and port to use when connecting to Redis (optional).
#REDIS_HOST = 'localhost'
#REDIS_PORT = 6379 # Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
#REDIS_URL = 'redis://user:pass@hostname:9001' # Custom redis client parameters (i.e.: socket timeout, etc.)
#REDIS_PARAMS = {}
# Use custom redis client class.
#REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # If True, it uses redis' ``spop`` operation. This could be useful if you
# want to avoid duplicates in your start urls list. In this cases, urls must
# be added via ``sadd`` command or you will get a type error from redis.
#REDIS_START_URLS_AS_SET = False # Default start urls key for RedisSpider and RedisCrawlSpider.
#REDIS_START_URLS_KEY = '%(name)s:start_urls' # Use other encoding than utf-8 for redis.
#REDIS_ENCODING = 'latin1'
写的很长对不对,完全不想看对不对,那我就直接把里面重点的一部分挑出来说下。
- 核心配置(要实现分布式,这个必须要设置):
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #将调度器修改
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #去重过滤器修改
- 请求队列:
# Schedule requests using a priority queue. (default)
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' #优先级队列,源码里面用分数来设置优先级,有兴趣可以看看 # Alternative queues.
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' #先进先出,也就是说先放进来的请求先取走
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' #先进后出,栈,也就是说后放进来的请求先取走
- redis连接信息配置(必须要配置,如果有密码也要把密码写上):
#REDIS_HOST = 'localhost' #这个地址肯定是要换成服务器的地址的
#REDIS_PORT = 6379 #默认端口,当然你也可以自己改
#REDIS_PASSWORD = xxx #这个就是redis数据库的密码啦
- 队列、指纹处理:
# Don't cleanup redis queues, allows to pause/resume crawls.
#SCHEDULER_PERSIST = True #爬取完成保留队列、不进行清空,默认是不保留。当然如果是手动停止的话,里面没有请求过的还会继续保留,下次运行爬虫继续从里面拿请求
- 配置爬虫开始动作:
SCHEDULER_FLUSH_ON_START = True #是否在开始之前清空 调度器和去重记录,True=清空,False=不清空。分布式爬虫不建议设置该项
- 配置pipeline(数据量多的时候不建议从这个redis数据库存,redis基于内存,我们看重的是速度):
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300 #如果配置了该项,数据item就会存储到redis数据库
}
当然还有很多其他的配置,可以根据实际需要进行选择。
- 下面我们完成我们自己的设置,对settings.py文件修改如下(包括redis和mysql)
#The following is scrapy_redis settings SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" REDIS_HOST = '47.98.xx.xx' #修改未自己的服务器redis地址
REDIS_PORT = 6379 SCHEDULER_PERSIST = True
#The following is mysql settings
MYSQL_HOST = '47.98.xx.xx' #修改为自己的mysql所在的服务器地址
MYSQL_DATABASE = 'lagou'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '@Fxxxxx' #修改为自己的mysql的密码
MYSQL_PORT = 3306
- 把代码打包好上传到远程主机上(打包好后,直接拖动到xshell窗口里)
- 我这里打包成zip格式。建立好项目目录后,把这个zip文件拖进去。
- 解压

现在我们使用python main.py把这个远程主机上的爬虫给跑起来。(注意:远程主机需要安装python3环境,还有scrapy以及相关的包。)
运行本地爬虫,运行远程主机上的爬虫,这样分布式就完成了。
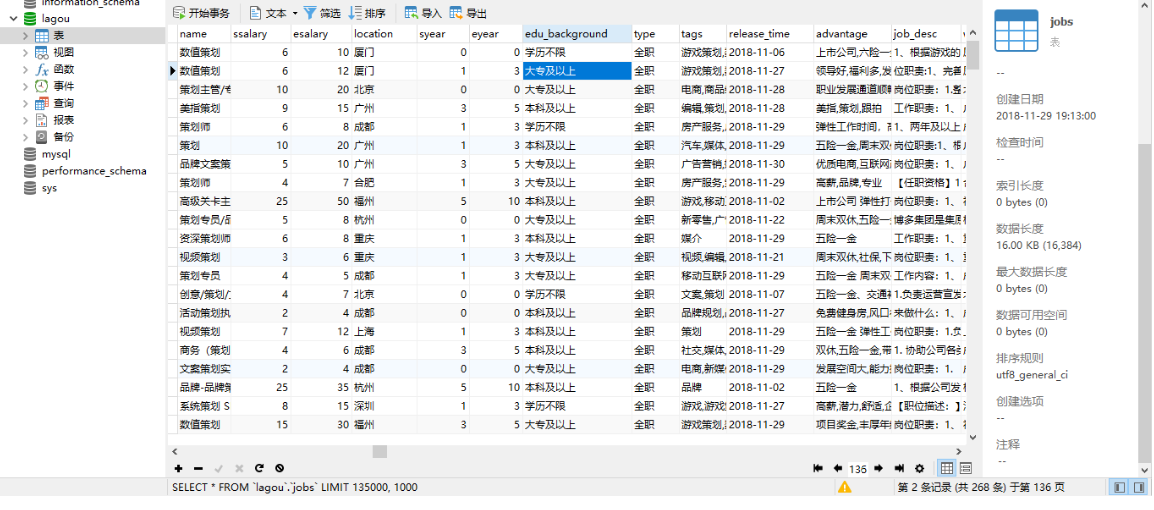
爬虫正常运行,而且数据都存在了远程服务器的mysql上。
同时redis上可以看到requests和du'pefilter指纹信息。
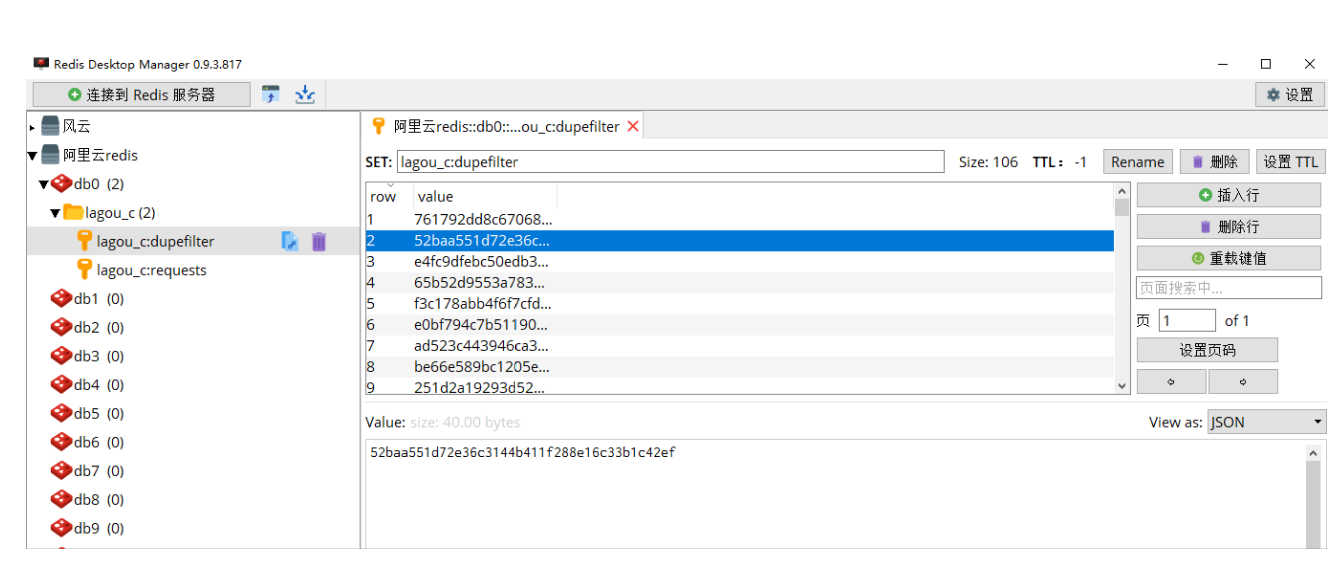
最终爬取的数据图片(总共存储了136页,每一页1000个数据):
scrapy抓取拉勾网职位信息(七)——实现分布式的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- Fire Net(深度优先搜索)
ZOJ Problem Set - 1002 Fire Net Time Limit: 2 Seconds Memory Limit: 65536 KB Suppose that we ha ...
- 不平衡分类学习方法 --Imbalaced_learn
最近在进行一个产品推荐课题时,由于产品的特性导致正负样本严重失衡,远远大于3:1的比例(个人认为3:1是建模时正负样本的一个临界点),这样的样本不适合直接用来建模,例如正负样本的比例达到了50:1,就 ...
- Uploadify & jQuery.imgAreaSelect 插件实现图片上传裁剪
在网站中需要一个图片上传裁剪的功能,借鉴这篇文章 Ajax+PHP+jQuery图片截图上传 的指点,找到了jquery.imgAreaSelect这个不错插件,能对图片进行自定义区域选择并给出坐标, ...
- 【CodeForces】947 C. Perfect Security 异或Trie
[题目]C. Perfect Security [题意]给定长度为n的非负整数数组A和数组B,要求将数组B重排列使得A[i]^B[i]的字典序最小.n<=3*10^5,time=3.5s. [算 ...
- python学习笔记(十四)之字典
字典:是python中唯一的映射类型,字典中每一项都是由键-值对组成的项.字典中没有索引,只有键和值.键的类型可以是整型,变量或字符串. 创建和访问字典: >>> dict1 = { ...
- 爬虫--selenium
什么是selenium? 基本使用 from selenium import webdriver from selenium.webdriver.common.by import By from se ...
- NB二人组(一)----堆排序
堆排序前传--树与二叉树简介 特殊且常用的树--二叉树 两种特殊的二叉树 二叉树的存储方式 二叉树小结 堆排序 堆这个玩意....... 堆排序过程: 构造堆: 堆排序的算法程序(程序需配合着下图理 ...
- 一个爬取https和http通用的工具类(JDK自带的URL的用法)
今天在java爬取天猫的时候因为ssl报错,所以从网上找了一个可以爬取https和http通用的工具类.但是有的时候此工具类爬到的数据不全,此处不得不说python爬虫很厉害. package cn. ...
- 用Centos7搭建小微企业Samba文件共享服务器【转】
转自 用Centos7搭建小微企业Samba文件共享服务器 - 今日头条(www.toutiao.com)http://www.toutiao.com/i6436937837660078593/ 最近 ...
- Django自定义UserModel并实现认证和登录
自定义UserModel 环境:django 1.9.11+python 2.7 from django.contrib.auth.models import AbstractUser class U ...