模型蒸馏(Distil)及mnist实践
结论:蒸馏是个好方法。
模型压缩/蒸馏在论文《Model Compression》及《Distilling the Knowledge in a Neural Network》提及,下面介绍后者及使用keras测试mnist数据集。
蒸馏:使用小模型模拟大模型的泛性。
通常,我们训练mnist时,target是分类标签,在蒸馏模型时,使用的是教师模型的输出概率分布作为“soft target”。也即损失为学生网络与教师网络输出的交叉熵(这里采用DistilBert论文中的策略,此论文不同)。
当训练好教师网络后,我们可以不再需要分类标签,只需要比较2个网络的输出概率分布。当然可以在损失里再加上学生网络的分类损失,论文也提到可以进一步优化。
如图,将softmax公式稍微变换一下,目的是使得输出更小,softmax后就更为平滑。
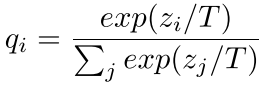
论文的损失定义

本文代码使用的损失为p和q的交叉熵
代码测试部分
1,教师网络,测试精度99.46%,已经相当好了,可训练参数858,618。
# 教师网络
inputs=Input((28,28,1))
x=Conv2D(64,3)(inputs)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(64,3,strides=2)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(128,5)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(128,5)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Flatten()(x)
x=Dense(100)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Dropout(0.3)(x)
x=Dense(10,activation='softmax')(x)
model=Model(inputs,x)
model.compile(optimizer=optimizers.SGD(momentum=0.8,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy'])
model.summary()
model.fit(X_train,y_train,batch_size=128,epochs=30,validation_split=0.2,verbose=2)
# 重新编译后,完整数据集训练18轮,原始16轮后开始过拟合,训练集变大后不易过拟合,这里增加2轮
model.fit(X_train,y_train,batch_size=128,epochs=18,verbose=2)
model.evaluate(X_test,y_test)# 99.46%
2,学生网络,测试精度99.24%,可训练参数164,650,不到原来的1/5。
# 定义温度
tempetature=3
# 学生网络
inputs=Input((28,28,1))
x=Conv2D(16,3)(inputs)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(16,3)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(32,5)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Conv2D(32,5,strides=2)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Flatten()(x)
x=Dense(60)(x)
x=BatchNormalization(center=True,scale=False)(x)
x=Activation('relu')(x)
x=Dropout(0.3)(x)
x=Dense(10,activation='softmax')(x)
x=Lambda(lambda t:t/tempetature)(x)# softmax后除以温度,使得更平滑
student=Model(inputs,x)
student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy'])
# 使用老师和学生概率分布结果的软交叉熵,即除以温度后的交叉熵
student.fit(X_train,model.predict(X_train)/tempetature,batch_size=128,epochs=30,verbose=2)
最后测试一下
student.evaluate(X_test,y_test/tempetature)# 99.24%
3,继续减少参数,去除Dropout和BN,前期卷积使用步长,精度98.80%。参数72,334,大约原来的1/12。
# 定义温度
tempetature=3
# 学生网络
inputs=Input((28,28,1))
x=Conv2D(16,3,activation='relu')(inputs)
# x=BatchNormalization(center=True,scale=False)(x)
# x=Activation('relu')(x)
x=Conv2D(16,3,strides=2,activation='relu')(x)
# x=BatchNormalization(center=True,scale=False)(x)
# x=Activation('relu')(x)
x=Conv2D(32,5,activation='relu')(x)
# x=BatchNormalization(center=True,scale=False)(x)
# x=Activation('relu')(x)
x=Conv2D(32,5,activation='relu')(x)
# x=BatchNormalization(center=True,scale=False)(x)
# x=Activation('relu')(x)
x=Flatten()(x)
x=Dense(60,activation='relu')(x)
# x=BatchNormalization(center=True,scale=False)(x)
# x=Activation('relu')(x)
# x=Dropout(0.3)(x)
x=Dense(10,activation='softmax')(x)
x=Lambda(lambda t:t/tempetature)(x)# softmax后除以温度,使得更平滑
student=Model(inputs,x)
student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy'])
student.fit(X_train,model.predict(X_train)/tempetature,batch_size=128,epochs=30,verbose=2)
student.evaluate(X_test,y_test/tempetature)# 98.80%
4,在3的基础上,loss部分加上学生网络与分类标签的损失,测试精度98.79%。基本没变化,此时这个损失倒不太重要了。
# 冻结老师网络
model.trainable=False
# 定义温度
temperature=3
# 自定义loss,加上学生网络与真实标签的损失,这个损失计算应使学生网络温度为1,即这个损失不用除以温度
class Calculate_loss(Layer):
def __init__(self,T,label_loss_weight,**kwargs):
'''
T: temperature for soft-target
label_loss_weight: weight for loss between student-net and labels, could be small because the other loss is more important
'''
self.T=T
self.label_loss_weight=label_loss_weight
super(Calculate_loss,self).__init__(**kwargs)
def call(self,inputs):
student_output=inputs[0]
teacher_output=inputs[1]
labels=inputs[2]
loss_1=categorical_crossentropy(teacher_output/self.T,student_output/self.T)
loss_2=self.label_loss_weight*categorical_crossentropy(labels,student_output)
self.add_loss(loss_1+loss_2,inputs=inputs)
return labels
# 将标签转化为tensor输入
y_inputs=Input((10,))# 类似placeholder作用
y=Lambda(lambda t:t)(y_inputs)
# 学生网络
inputs=Input((28,28,1))
x=Conv2D(16,3,activation='relu')(inputs)
x=Conv2D(16,3,strides=2,activation='relu')(x)
x=Conv2D(32,5,activation='relu')(x)
x=Conv2D(32,5,activation='relu')(x)
x=Flatten()(x)
x=Dense(60,activation='relu')(x)
x=Dense(10,activation='softmax')(x)
x=Calculate_loss(T=temperature,label_loss_weight=0.1)([x,model(inputs),y])
student=Model([inputs,y_inputs],x)
student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=None)
student.summary()
student.fit(x=[X_train,y_train],y=None,batch_size=128,epochs=30,verbose=2)
提取出预测模型,标签one-hot化了,重新加载一下
softmax_layer=student.layers[-4] predict_model=Model(inputs,softmax_layer.output) res=predict_model.predict(X_test) import numpy as np
result=[np.argmax(a) for a in res] (x_train,y_train),(x_test,y_test)=mnist.load_data() from sklearn.metrics import accuracy_score
accuracy_score(y_test,result)# 98.79%
5,作为对比,相同网络不使用蒸馏,测试精度98.4%
# 对应上面,不使用蒸馏,精度为98.4%
inputs=Input((28,28,1))
x=Conv2D(16,3,activation='relu')(inputs)
x=Conv2D(16,3,strides=2,activation='relu')(x)
x=Conv2D(32,5,activation='relu')(x)
x=Conv2D(32,5,activation='relu')(x)
x=Flatten()(x)
x=Dense(60,activation='relu')(x)
x=Dense(10,activation='softmax')(x)
student=Model(inputs,x)
student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy'])
student.summary()
# student.fit(X_train,y_train,validation_split=0.2,batch_size=128,epochs=30,verbose=2)
student.fit(X_train,y_train,batch_size=128,epochs=10,verbose=2)
student.evaluate(X_test,y_test)
模型蒸馏(Distil)及mnist实践的更多相关文章
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- TensorFlow自编码器(AutoEncoder)之MNIST实践
自编码器可以用于降维,添加噪音学习也可以获得去噪的效果. 以下使用单隐层训练mnist数据集,并且共享了对称的权重参数. 模型本身不难,调试的过程中有几个需要注意的地方: 模型对权重参数初始值敏感,所 ...
- ASP.NET MVC 模型和数据对象映射实践
在使用 MVC 开发项目的过程中遇到了个问题,就是模型和数据实体之间的如何快捷的转换?是不是可以像 Entity Framework 的那样 EntityTypeConfiguration,或者只需要 ...
- IO模型之AIO代码及其实践详解
一.AIO简介 AIO是java中IO模型的一种,作为NIO的改进和增强随JDK1.7版本更新被集成在JDK的nio包中,因此AIO也被称作是NIO2.0.区别于传统的BIO(Blocking IO, ...
- IO模型之NIO代码及其实践详解
一.简介 NIO我们一般认为是New I/O(也是官方的叫法),因为它是相对于老的I/O类库新增的( JDK 1.4中的java.nio.*包中引入新的Java I/O库).但现在都称之为Non-bl ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- Windows下mnist数据集caffemodel分类模型训练及测试
1. MNIST数据集介绍 MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的: MNIST数据库有以下特性: 包含了60000个训练样本集和1000 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
随机推荐
- ACM-ICPC 2015 沈阳赛区现场赛 I. Triple && HDU 5517(二维BIT)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5517 题意:有二元组(a,b),三元组(c,d,e).当b == e时它们能构成(a,c,d)然后,当 ...
- 【AndroidStudio-添加RecyclerView包】 AndroidStudio添加v7包中的RecyclerView
关于AndroidStudio如何添加v7包中的RecyclerView? 左侧Project视图,在External Libraries下找到appcompat-v7包 右击appcompat-v7 ...
- Web自动化简介
在迭代中时,先写出粗略的自动化测试用例,不是非常精准的一些提示,等到项目上线后,提示文案已经确定,再完善用例,使之成为一个完整的自动化测试工程. 用excel管理测试数据,读取效率比较低,需要读取.数 ...
- P2051 [AHOI2009]中国象棋 大力DP
状压个啥$qwq$ 思路:大力$DP$ 提交:2次(自信的开了$int$) 题解:(见注释) #include<cstdio> #include<iostream> using ...
- FtpHelper.cs
网上找了好多,感觉还是自己这个使用起来方便点,记录一下! using System; using System.Collections; using System.IO; using System.L ...
- Gradle 的项目导入到 IntelliJ 后子项目源代码不能导入
在一个 Gradle 项目中,有若干子项目. 当 Gradle 到如后,子项目不能被 IntelliJ 识别代码. 如下图的这个代码就没有被自动识别. 这个有可能是因为你的这个子项目没有被添加到父项 ...
- 【luoguP1311 】选择客栈
题目描述 丽江河边有nn家很有特色的客栈,客栈按照其位置顺序从 11到nn编号.每家客栈都按照某一种色调进行装饰(总共 kk 种,用整数 00 ~k-1k−1 表示),且每家客栈都设有一家咖啡店,每家 ...
- 【CF671D】 Roads in Yusland(对偶问题,左偏树)
传送门 洛谷翻译 CodeForces Solution emmm,先引入一个对偶问题的概念 \(max(c^Tx|Ax \leq b)=min(b^Ty|A^Ty \ge c)\) 考虑这个式子的现 ...
- 实现多列等高布局_flex布局
详情参见此篇博客 http://www.w3cplus.com/css/creaet-equal-height-columns 建议掌握方法四.五 其实,利用最新的flex布局 http://www. ...
- Java中boolean类型占用多少个字节?我说一个,面试官让我回家等通知
摘自:https://www.cnblogs.com/qiaogeli/p/12004962.html 程序员乔戈里 腾讯面试官问我Java中boolean类型占用多少个字节?我说一个,面试官让我回家 ...