chapter02 K近邻分类器对Iris数据进行分类预测
寻找与待分类的样本在特征空间中距离最近的K个已知样本作为参考,来帮助进行分类决策。
与其他模型最大的不同在于:该模型没有参数训练过程。无参模型,高计算复杂度和内存消耗。
#coding=utf8 # 从sklearn.datasets 导入 iris数据加载器。 from sklearn.datasets import load_iris # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 从sklearn.preprocessing里选择导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 从sklearn.neighbors里选择导入KNeighborsClassifier,即K近邻分类器。 from sklearn.neighbors import KNeighborsClassifier # 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。 from sklearn.metrics import classification_report iris = load_iris() # 从使用train_test_split,利用随机种子random_state采样25%的数据作为测试集。 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33) # 对训练和测试的特征数据进行标准化。 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) # 使用K近邻分类器对测试数据进行类别预测,预测结果储存在变量y_predict中。 knc = KNeighborsClassifier() knc.fit(X_train, y_train) y_predict = knc.predict(X_test) # 使用模型自带的评估函数进行准确性测评。 print 'The accuracy of K-Nearest Neighbor Classifier is', knc.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=iris.target_names)
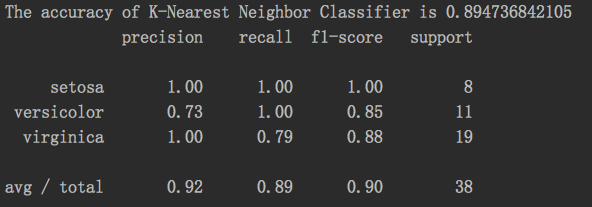
结果:
chapter02 K近邻分类器对Iris数据进行分类预测的更多相关文章
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- 最近邻分类器,K近邻分类器,线性分类器
转自:https://blog.csdn.net/oldmao_2001/article/details/90665515 最近邻分类器: 通俗来讲,计算测试样本与所有样本的距离,将测试样本归为距离最 ...
- sklearn.neighbors.KNeighborsClassifier(k近邻分类器)
KNeighborsClassifier参数说明KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', lea ...
- Python机器学习(基础篇---监督学习(k近邻))
K近邻 假设我们有一些携带分类标记的训练样本,分布于特征空间中,对于一个待分类的测试样本点,未知其类别,按照‘近朱者赤近墨者黑’,我们需要寻找与这个待分类的样本在特征空间中距离最近的k个已标记样本作为 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- sklearn机器学习算法--K近邻
K近邻 构建模型只需要保存训练数据集即可.想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”. 1.K近邻分类 #第三步导入K近邻模型并实例化KN对象 from skl ...
- 1. cs231n k近邻和线性分类器 Image Classification
第一节课大部分都是废话.第二节课的前面也都是废话. First classifier: Nearest Neighbor Classifier 在一定时间,我记住了输入的所有的图片.在再次输入一个图片 ...
随机推荐
- python中sys.stdout、sys.stdin
如果需要更好的控制输出,而print不能满足需求,sys.stdout,sys.stdin,sys.stderr就是你需要的. 1. sys.stdout与print: 在python中调用print ...
- [设计模式][c++]状态切换模式
转自:http://blog.csdn.net/yongh701/article/details/49154439 状态模式也是设计模式的一种,这种设计模式思想不复杂,就是实现起来的代码有点复杂.主要 ...
- SSD论文理解
SSD论文贡献: 1. 引入了一种单阶段的检测器,比以前的算法YOLO更准更快,并没有使用RPN和Pooling操作: 2. 使用一个小的卷积滤波器应用在不同的feature map层从而预测BB的类 ...
- Spring AMQP 源码分析 06 - 手动消息确认
### 准备 ## 目标 了解 Spring AMQP 如何手动确认消息已成功消费 ## 前置知识 <Spring AMQP 源码分析 04 - MessageListener> ## 相 ...
- Python - Cookie绕过验证码登录
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 另一篇博文 P ...
- TimeZone 时区 (JS .NET JSON MYSQL) + work week 闰年
来源参考 : http://www.cnblogs.com/qiuyi21/archive/2008/03/04/1089456.html 来源参考 : http://walkingice.blogs ...
- 家里各台机器的php性能测试
所用脚本: <?php $before = microtime(true); $list= array( "keya" => "the value a&quo ...
- FASTQ 数据质量统计工具
主流工具: FastQC fqcheck readfq 拿到测序数据的第一步就是做质量控制 fqcheck之后得到的结果: 它会统计每条reads,按read 1-100位点计算每个位置的ACGTN含 ...
- English trip -- MC(情景课)6 Time
xu言: 学习就和打仗一样,在开始前一定先要有准备(预习).这样在真正开始打的时候你会发现,本以为很难的仗,你却越战越勇,逐渐进入状态. Vocabulary focus gym [dʒɪm] ...
- Spring Boot 启动 Struts 报冲突
错误信息如下: Caused by: com.opensymphony.xwork2.config.ConfigurationException: Bean type class com.opensy ...