Spark 编程模型(中)

先在IDEA新建一个maven项目
我这里用的是jdk1.8,选择相应的骨架

这里选择本地在window下安装的maven

新的项目创建成功
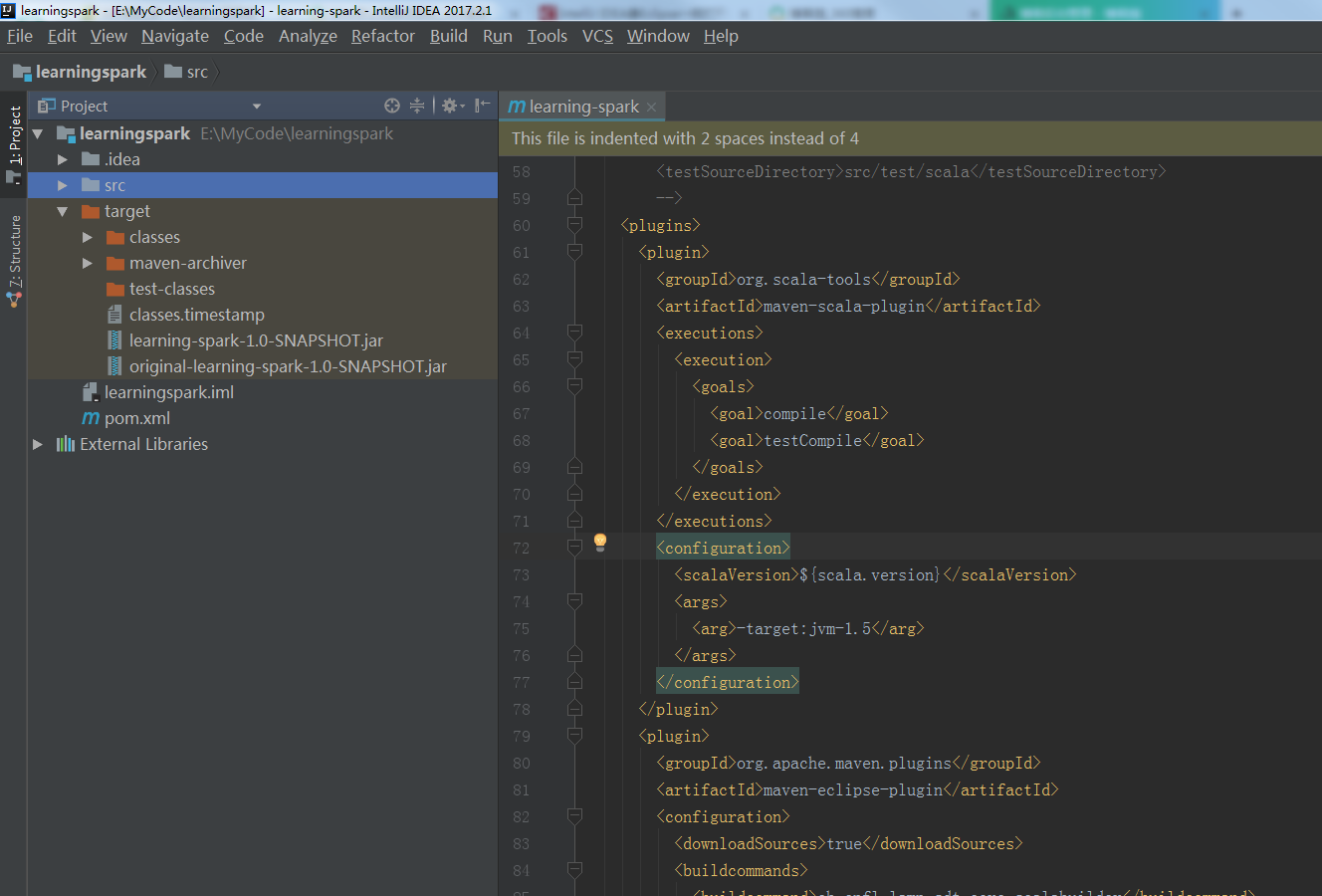
我的开始pom.xml文件配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.</modelVersion>
<groupId>com.gong.spark</groupId>
<artifactId>learning-spark</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear></inceptionYear>
<properties>
<scala.version>2.10.</scala.version>
<spark.version>1.6.</spark.version>
</properties> <repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories> <pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories> <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.</version>
<scope>test</scope>
</dependency>
<!--spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies> <build>
<!--
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
-->
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<!-- add Main-Class to manifest file -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!--<mainClass>com.dajiang.MyDriver</mainClass>-->
</transformer>
</transformers>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
先在终端下试下打包
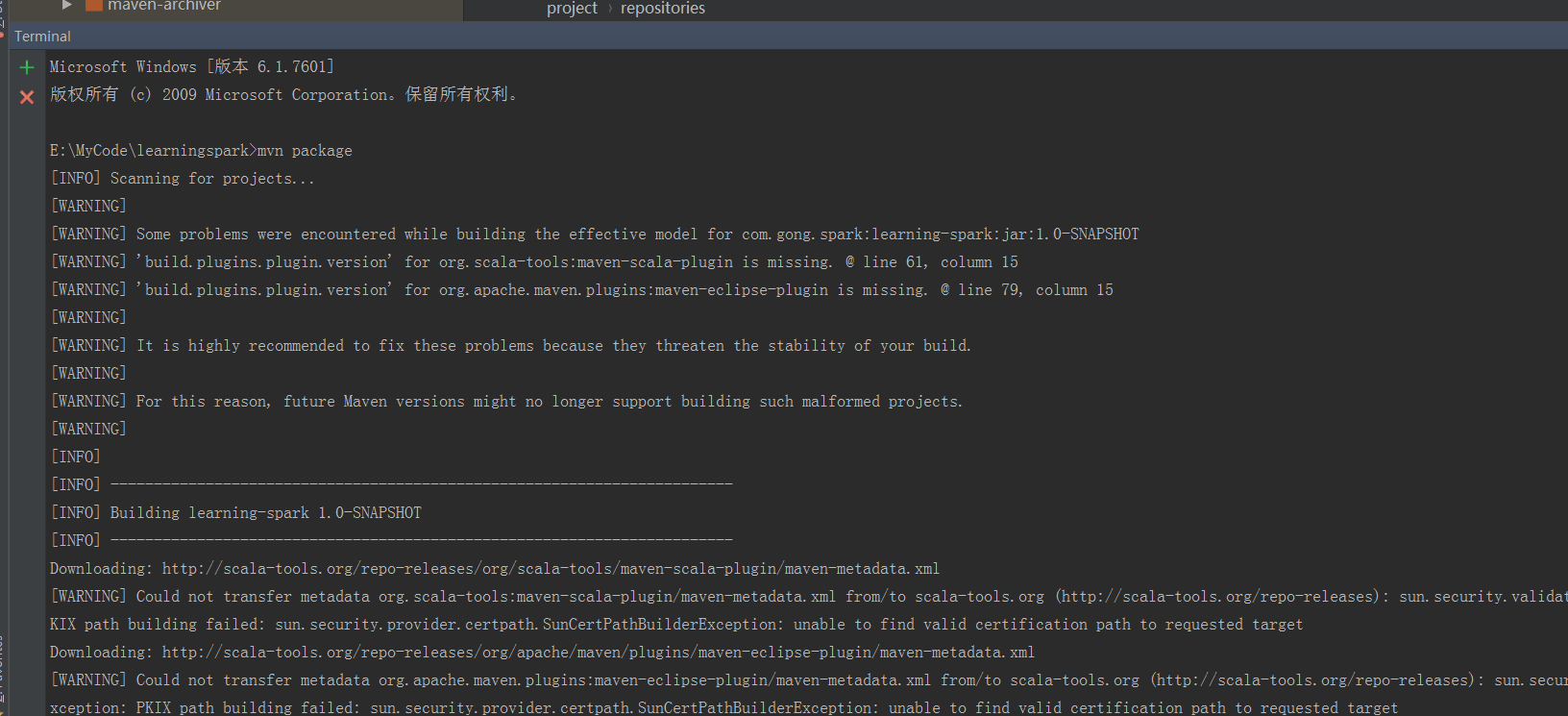
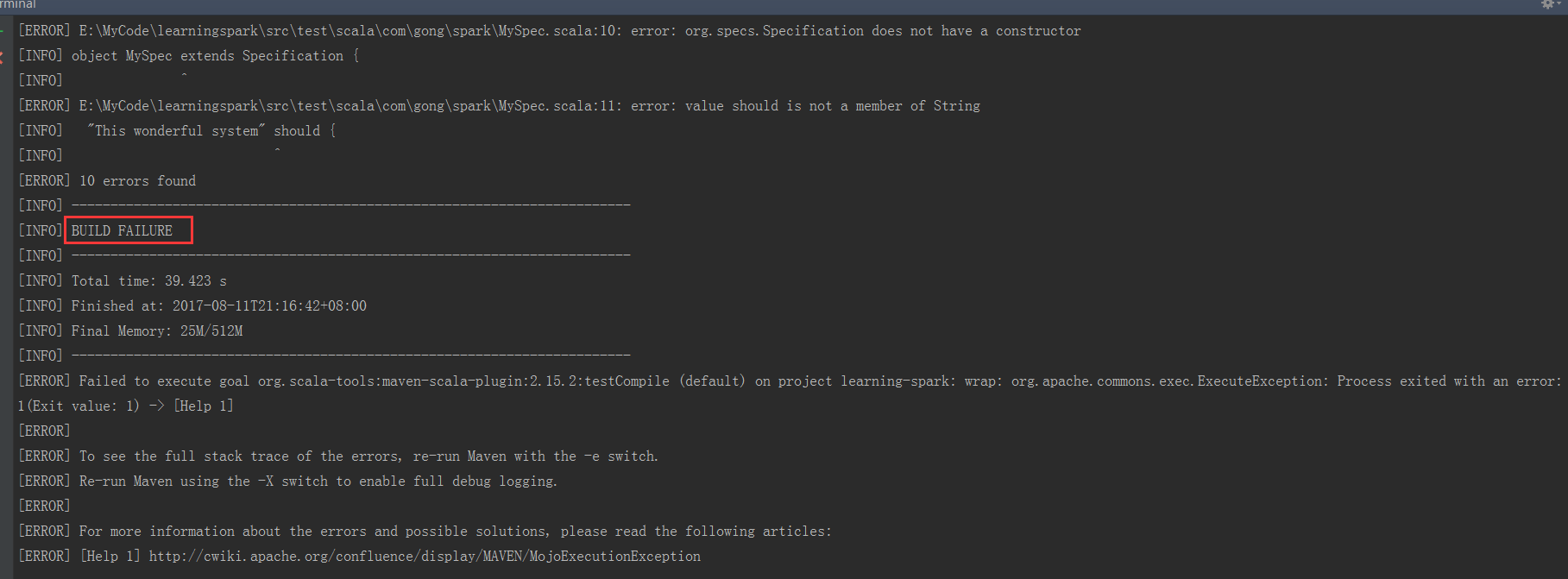
可以看到失败了!!!
把这几个生成默认的东西删除掉
再次测试
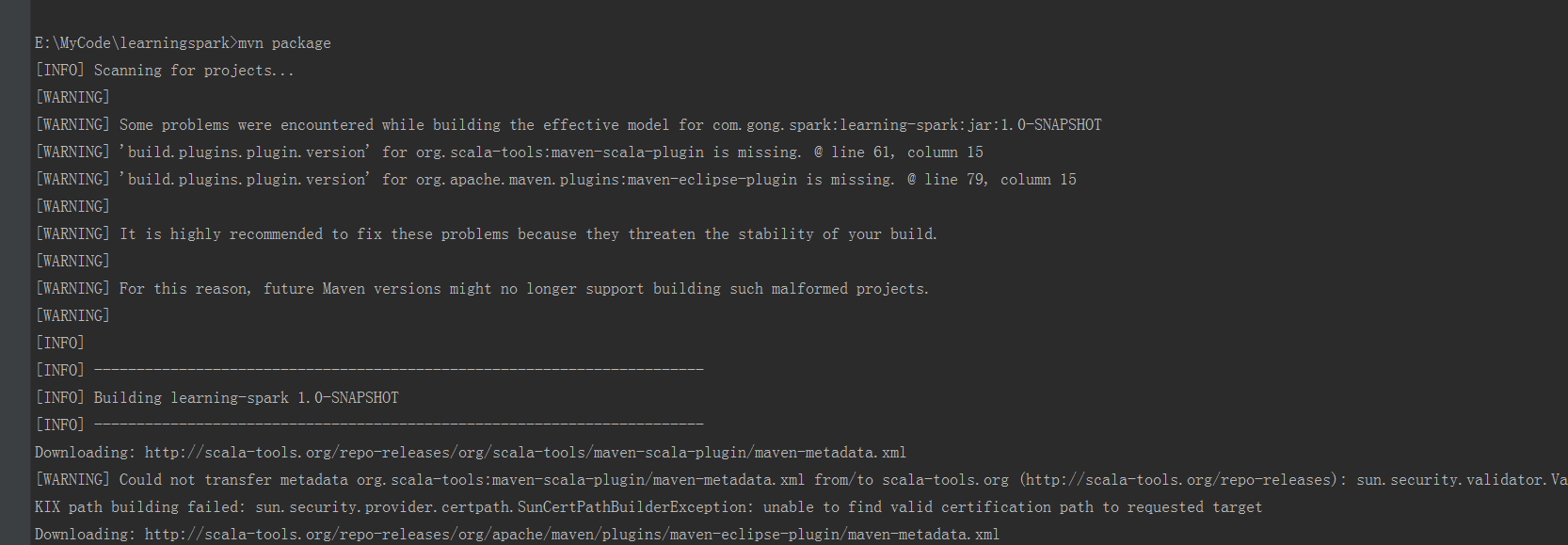
成功了

把他clean一下

进入自己在虚拟机安装的centos里面的spark
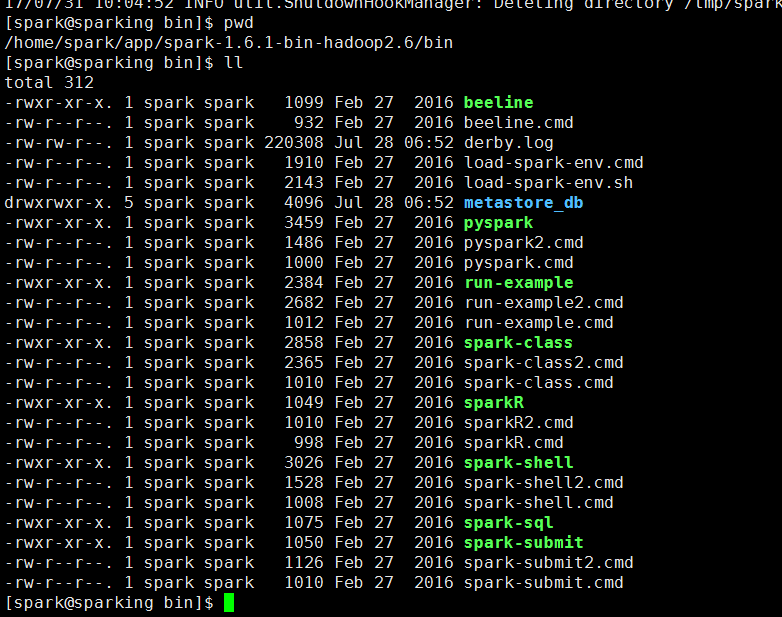
先测试一下spark环境有没有问题
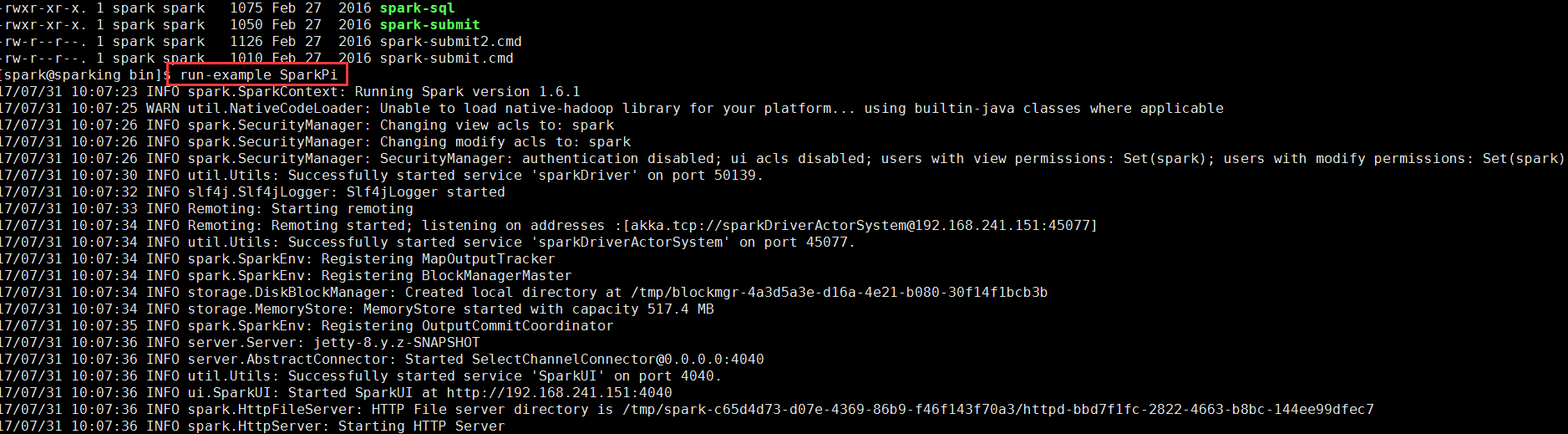
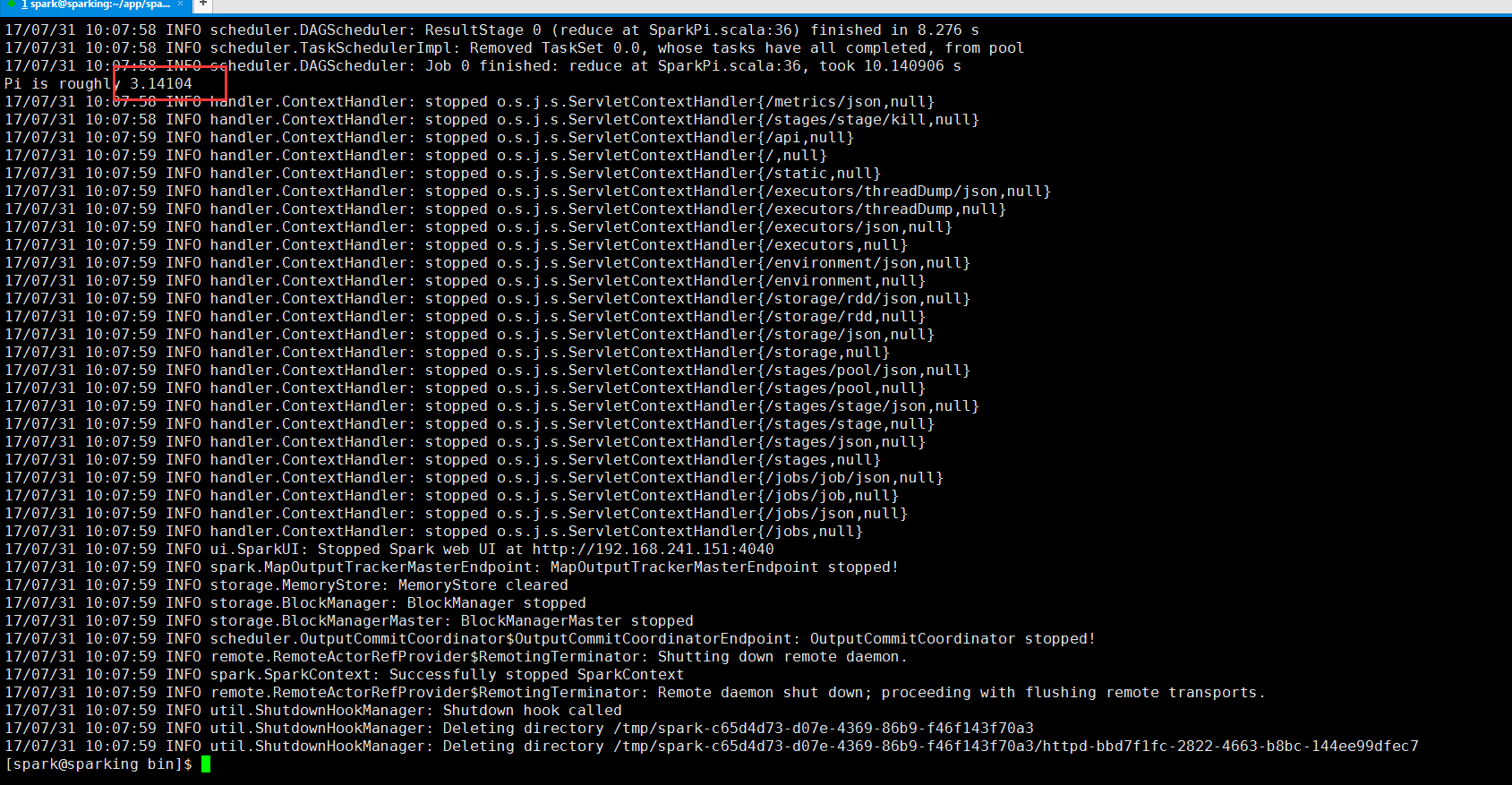
OK运行成,环境没问题!
1.创建RDD
方式一:从集合创建RDD

回到idea,在main路径下新建java目录,并且对其以下操作:
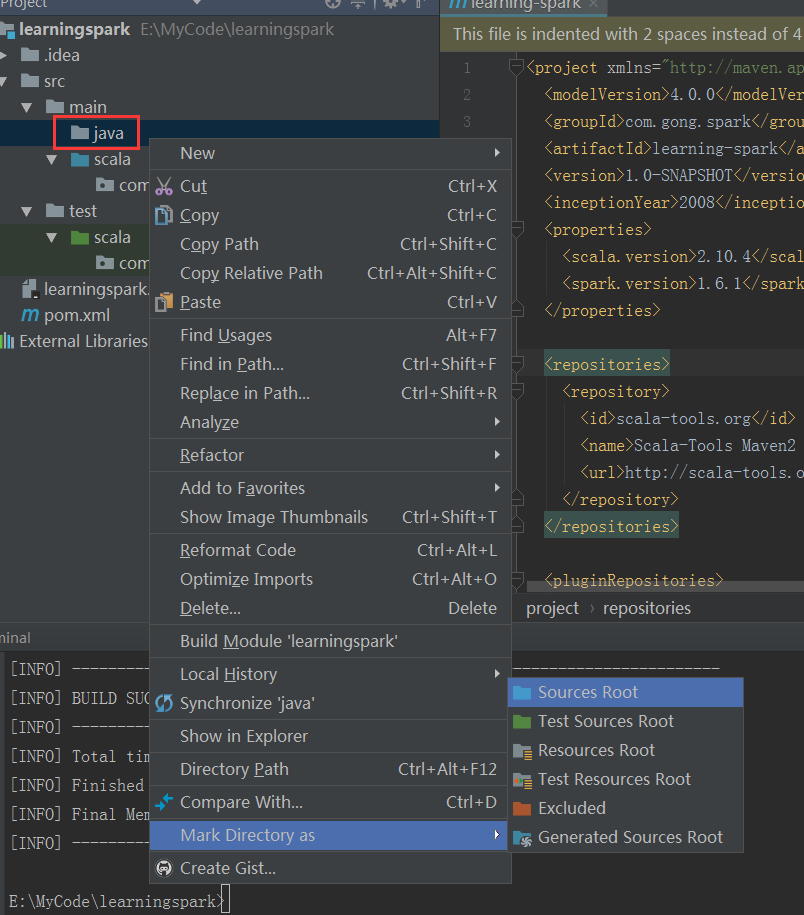
在test路径下新建java目录,对其以下操作:
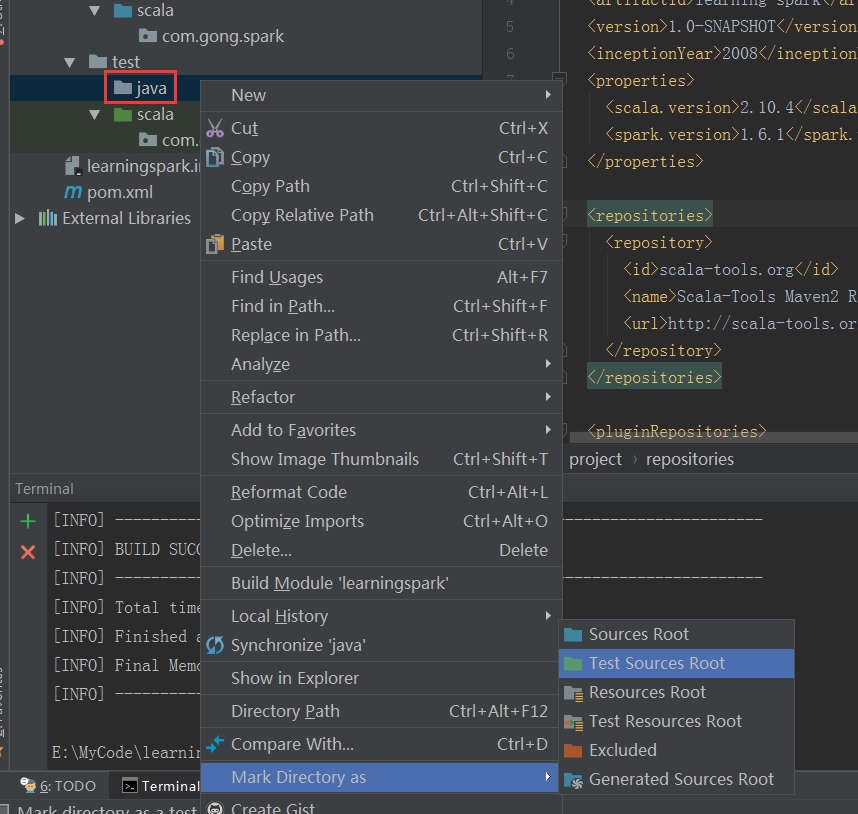
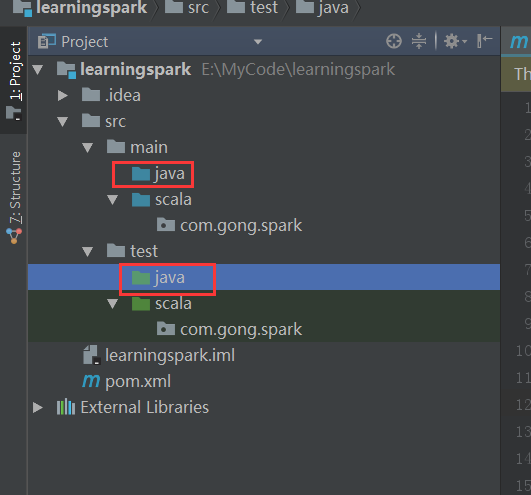
建包
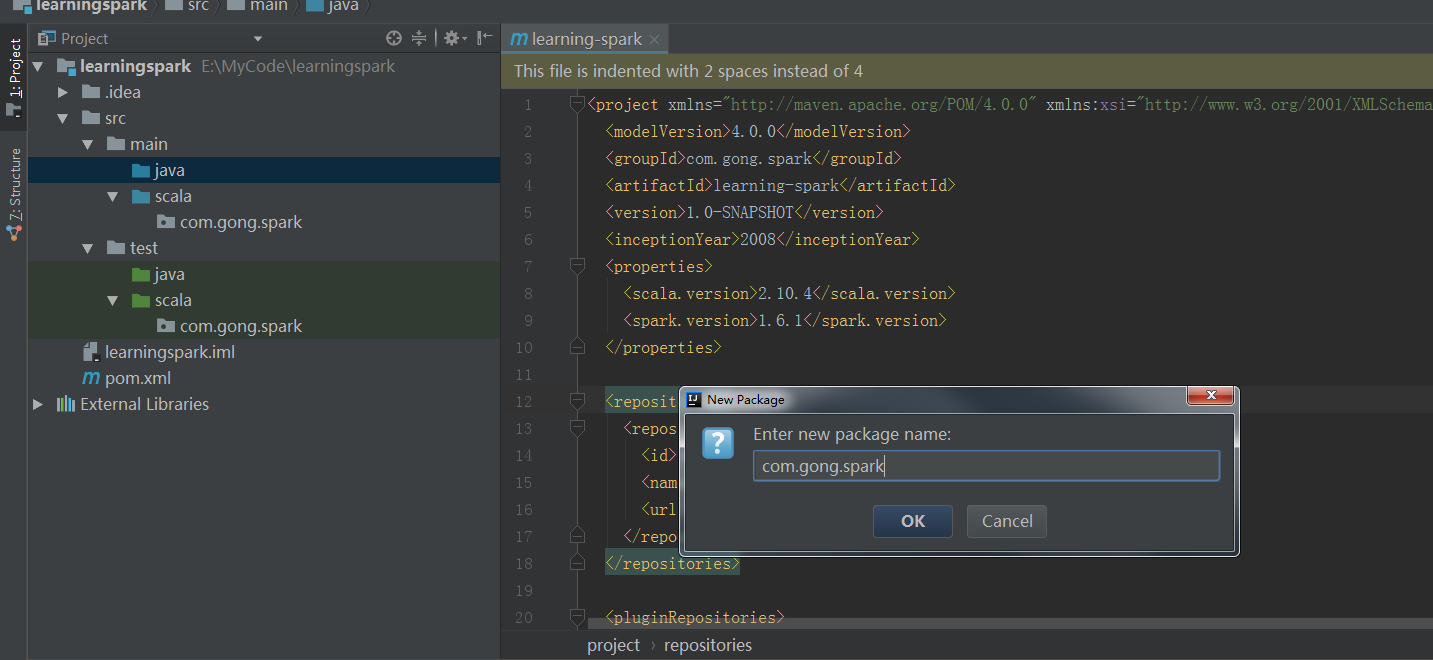

在当前包下起个名字,其实也就是在这个包的路径下再建下一级目录



因为我们现在要写的是java程序,所以新建一个java类

写个简单的程序测下运行一下
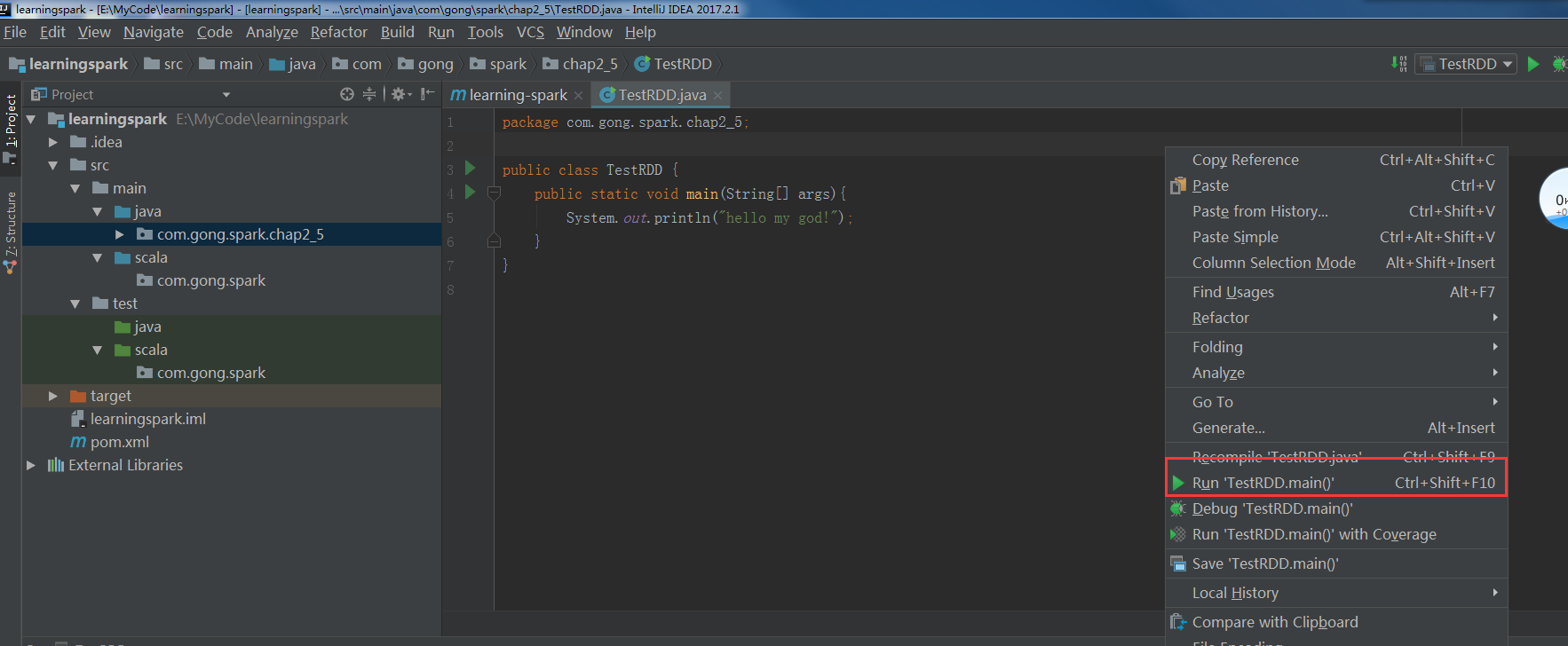
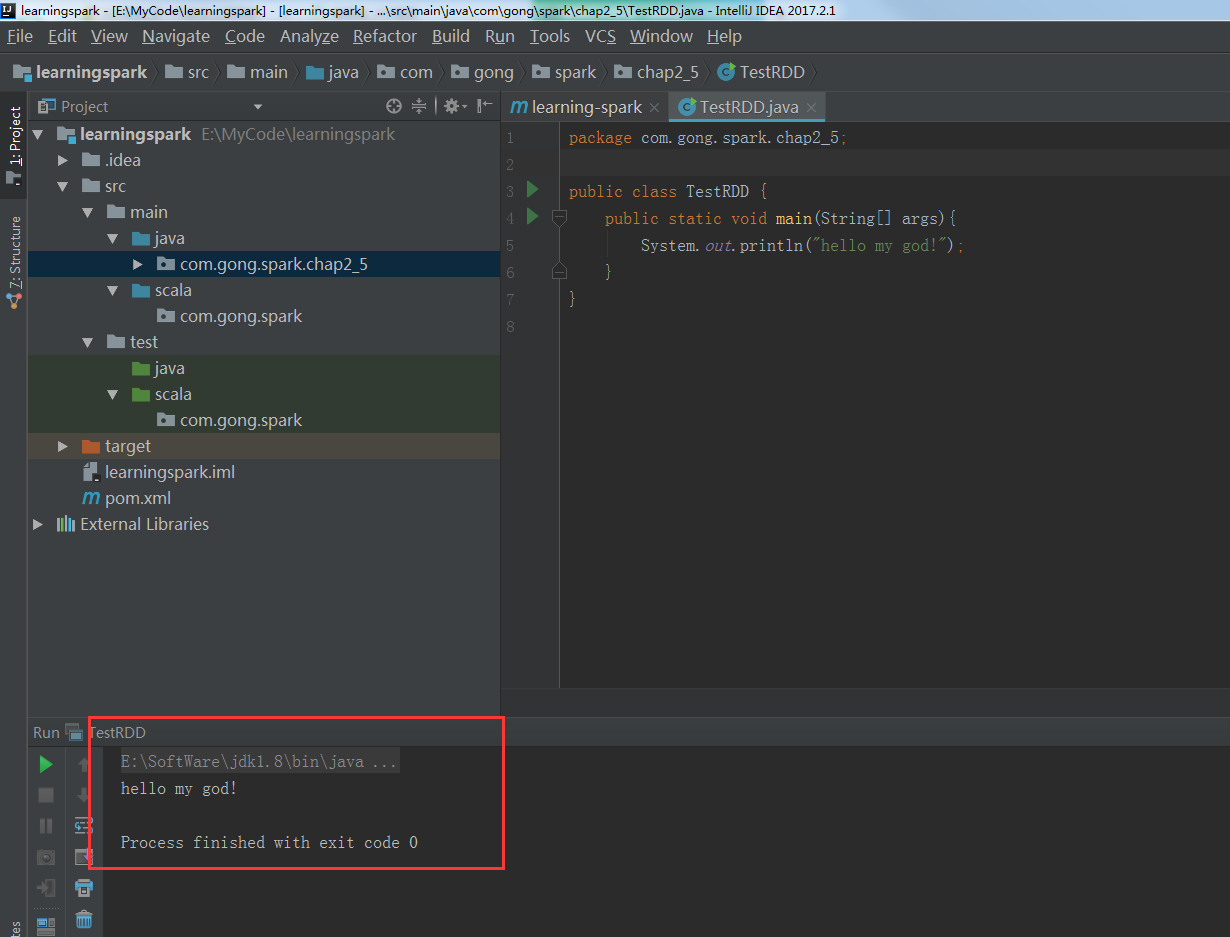
OK没问题,可以运行!
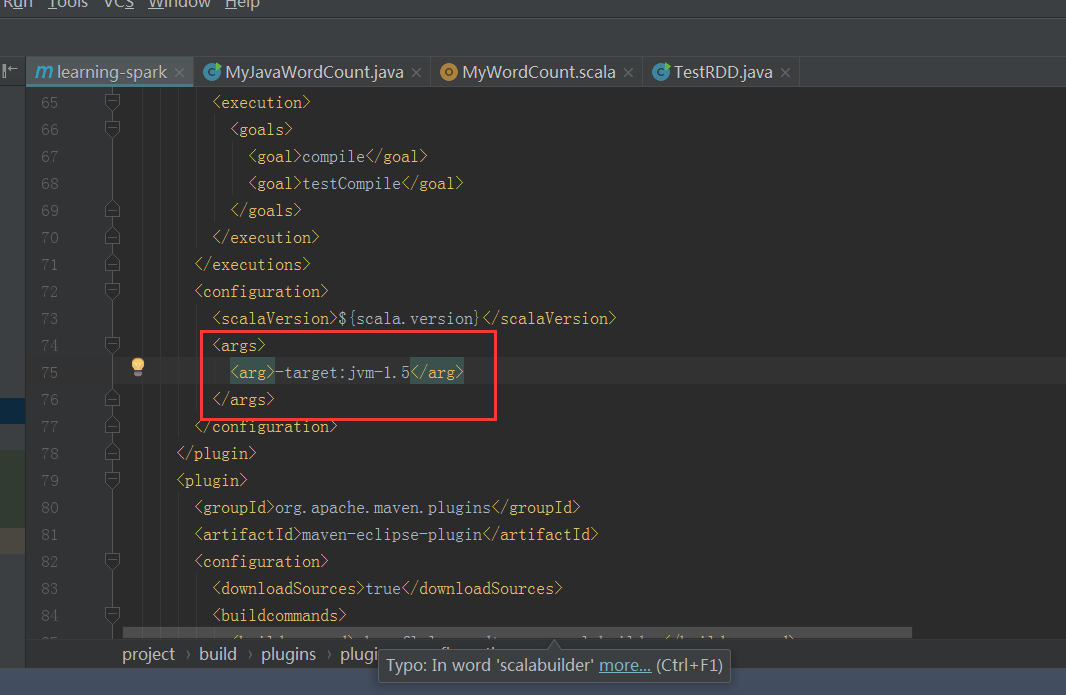
把这里的这个插件由原来的1.5改成1.8,因为刚刚跑的时候有警告
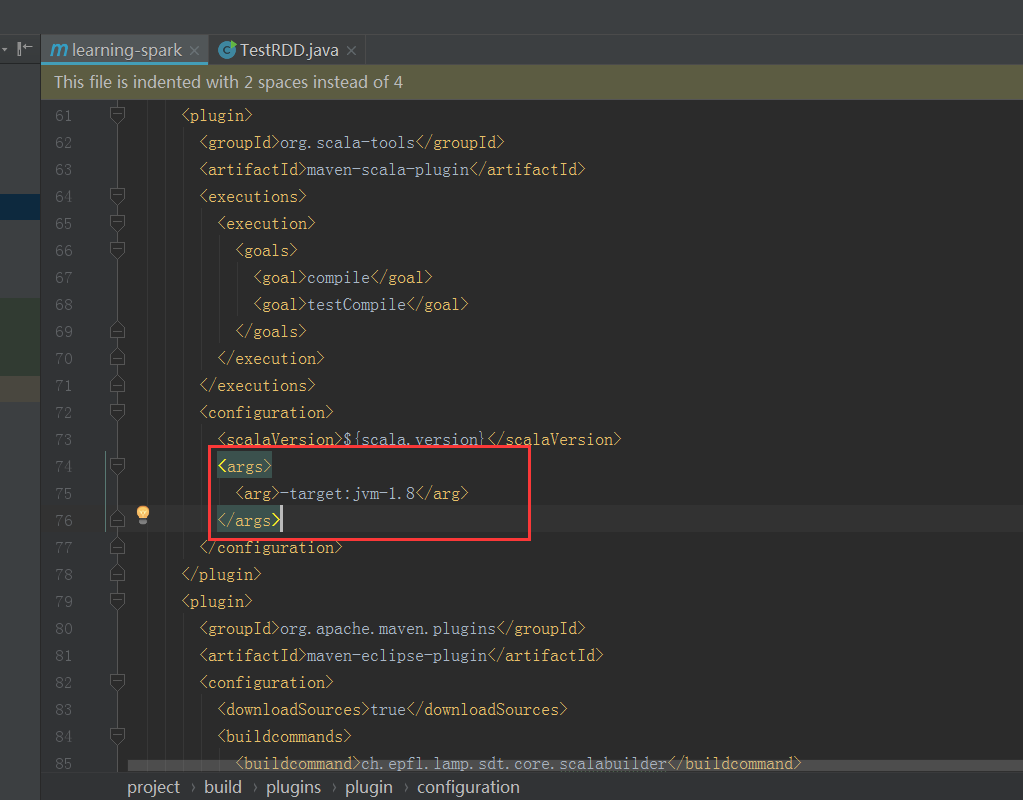
在这里新建一个包,具体怎么操作这里就不重复了
插入之前写好的MyJavaWordCount.java的代码

MyJavaWordCount.java参考代码
package com.gong.spark.chap2_3; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays; public class MyJavaWordCount {
public static void main(String[] args){
//参数检查
if(args.length<) {
System.err.println("Usage:MyJavaCount <input> <output>");
System.exit();
} //获取参数
String input=args[];
String output=args[]; //创建java版本的SparkContext
SparkConf conf=new SparkConf().setAppName("MyJavaWordCount");
JavaSparkContext sc = new JavaSparkContext(conf); //读取数据
JavaRDD<String> inputRdd=sc.textFile(input); //进行相关计算
JavaRDD<String> words=inputRdd.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
}); JavaPairRDD<String,Integer> result = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String,Integer> call(String word) throws Exception{
return new Tuple2(word,);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer x, Integer y) throws Exception {
return x+y;
}
}); //保存结果
result.saveAsTextFile(output); //关闭sc
sc.stop();
}
}
把之前写好的scala版本的WordCount程序放进来
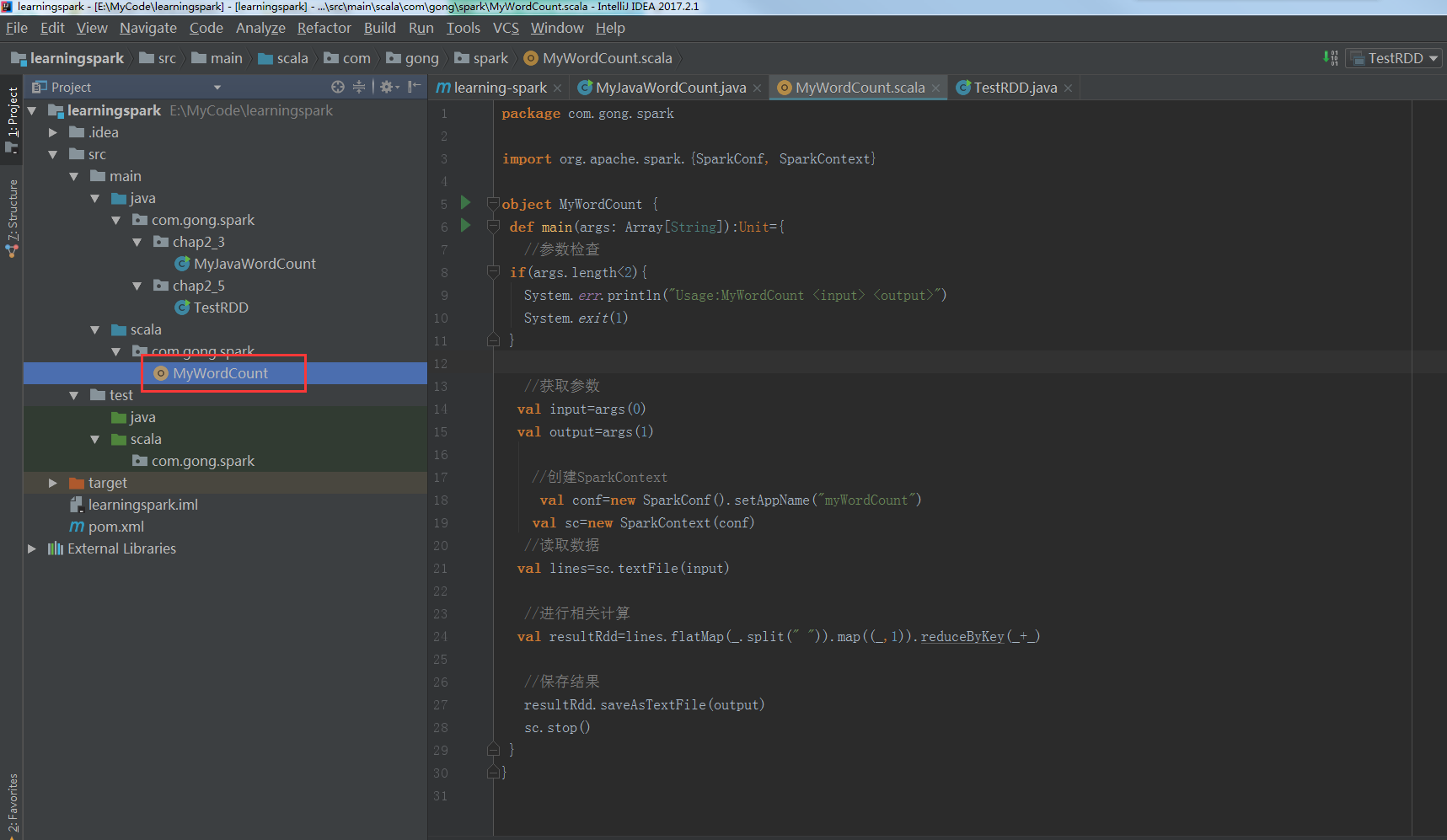
参考代码:
package com.gong.spark
import org.apache.spark.{SparkConf, SparkContext}
object MyWordCount {
def main(args: Array[String]):Unit={
//参数检查
if(args.length<){
System.err.println("Usage:MyWordCount <input> <output>")
System.exit()
}
//获取参数
val input=args()
val output=args()
//创建SparkContext
val conf=new SparkConf().setAppName("myWordCount")
val sc=new SparkContext(conf)
//读取数据
val lines=sc.textFile(input)
//进行相关计算
val resultRdd=lines.flatMap(_.split(" ")).map((_,)).reduceByKey(_+_)
//保存结果
resultRdd.saveAsTextFile(output)
sc.stop()
}
}
在终端mvn package
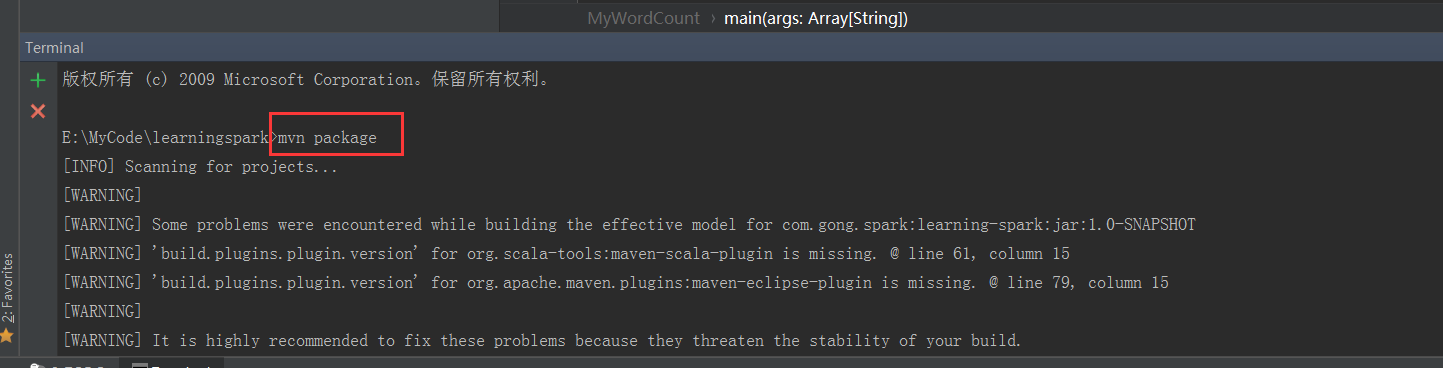
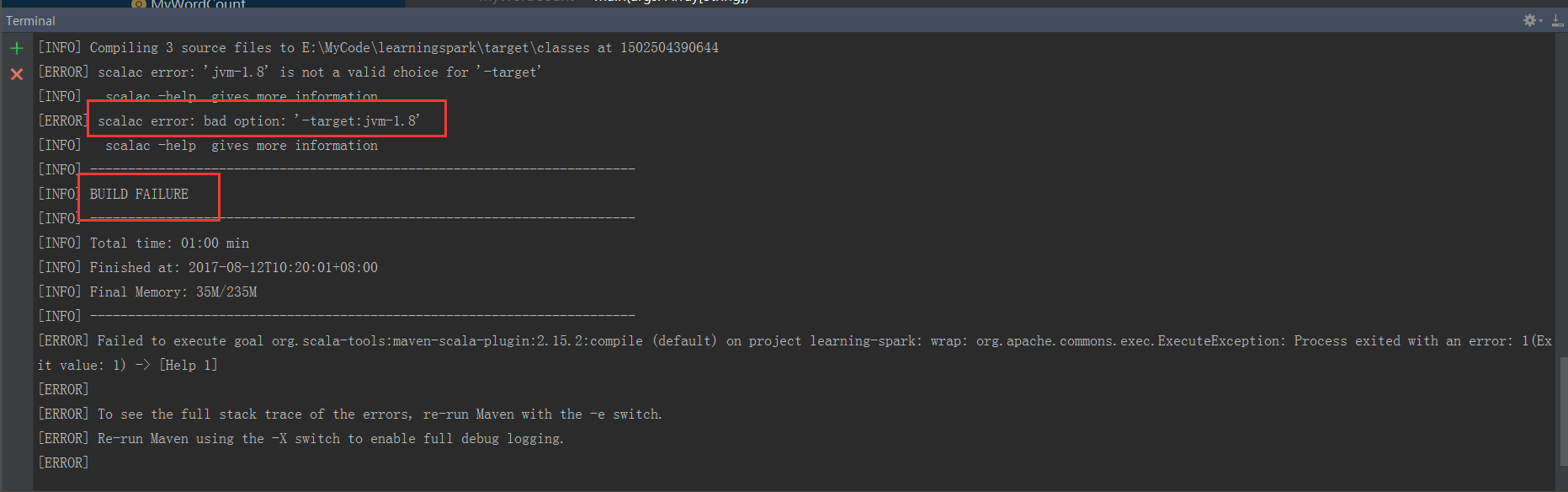
可以看到失败了,看来还是要把这里还回1.5版本的,不能乱改
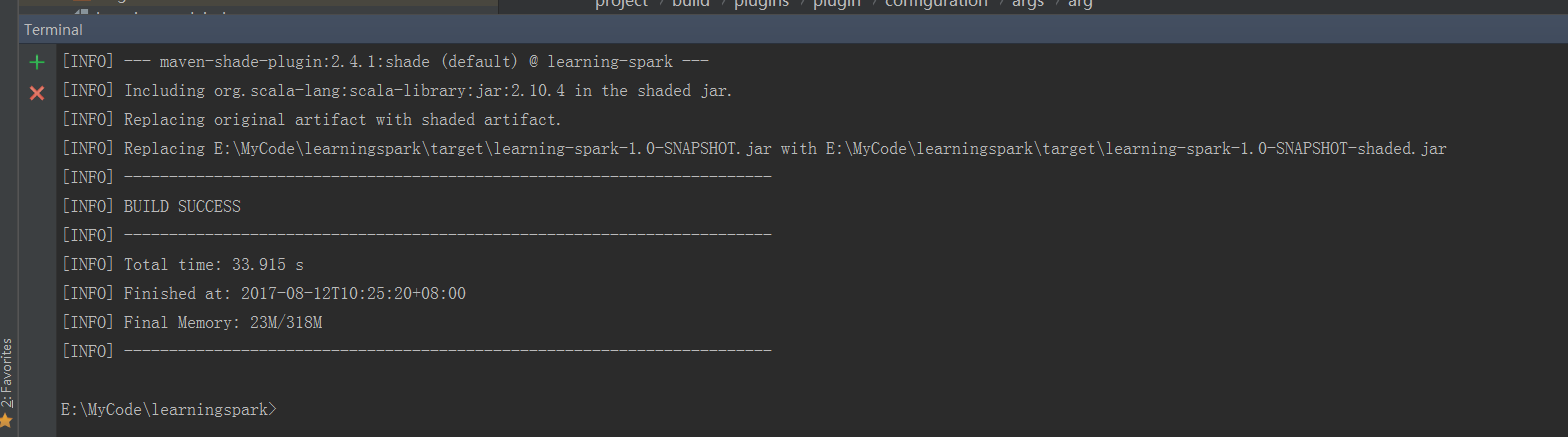
再次在终端mvn package,可以看到成功了!
方式二;读取外部存储创建RDD


transformation操作
惰性求值

转换操作

基本转换操作1

基本转换操作2

控制操作

action操作
Spark 编程模型(中)的更多相关文章
- Spark编程模型(中)
创建RDD 方式一:从集合创建RDD makeRDD Parallelize 注意:makeRDD可以指定每个分区perferredLocations参数parallelize则没有. 方式二:读取外 ...
- Spark编程模型(下)
创建Pair RDD 什么是Pair RDD 包含键值对类型的RDD类型被称作Pair RDD: Pair RDD通常用来进行聚合计算: Pair RDD通常由普通RDD做ETL转化而来. Pytho ...
- Spark编程模型(博主推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
- 转载:Spark中文指南(入门篇)-Spark编程模型(一)
原文:https://www.cnblogs.com/miqi1992/p/5621268.html 前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apac ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
随机推荐
- SWIFT推送之本地推送(UILocalNotification)之二带按钮的消息
上一篇讲到的本地推送是普通的消息推送,本篇要讲一下带按钮动作的推送消息,先上个图瞅瞅: 继上一篇的内容进行小小的改动: 在didFinishLaunchingWithOptions方法内进行以下修改 ...
- SWIFT模糊效果
首先创建一个模糊效果 let blurEffect = UIBlurEffect(style: UIBlurEffectStyle.Light) 接着创建一个承载模糊效果的视图let blurView ...
- OC基础:类和对象 分类: ios学习 OC 2015-06-12 18:55 17人阅读 评论(0) 收藏
OC:Objective-c 面向对象的c语言,简称obj-c或者OC OC和C的区别 1.OC是C语言的超集,OC是在C语言的基础上结合smalltalk的优点,开发出来的语言.oc兼容所有 ...
- eclipse运行报java.lang.OutOfMemoryError: PermGen space解决方法
一.在window下eclipse里面Server挂的是tomcat6,一开始还是以为,tomcat配置的问题,后面发现,配置了tomcat里面的catalina.bat文件,加入 set JAVA_ ...
- c++ json 详解
一. 使用jsoncpp解析json Jsoncpp是个跨平台的开源库,首先从http://jsoncpp.sourceforge.net/上下载jsoncpp库源码,我下载的是v0.5.0,压缩包大 ...
- MySQL设置默认编码
查看默认编码:show variables like "char%" MySQL5.5以下版本: 1.打开配置文件 2.在[client]和[mysqld]字段下面均添加defau ...
- LeetCode Single Number I II Python
Single Number Given an array of integers, every element appears twice except for one. Find that sing ...
- kettle--window开发环境和linux运行环境的迁移
首先要做的是将kettle在linux下搭建好. 一.搭建linux的kettle环境 1.1解压 (my_python_env)[root@hadoop26 ~]# .zip -d /usr/loc ...
- Angular 4 依赖注入
一.依赖注入 1. 创建工程 ng new myangular 2. 创建组件 ng g componet product1 3. 创建服务 ng g service shared/product 如 ...
- hadoop最新版本介绍之dkhadoop版本选择
Hadoop对于从事互联网工作的朋友来说已经非常熟悉了,相信在我们身边有很多人正在转行从事hadoop开发的工作,理所当然也会有很多hadoop入门新手.Hadoop开发太过底层,技术难度远比我们想象 ...