Introducing Deep Reinforcement
The manuscript of Deep Reinforcement Learning is available now! It makes significant improvements to Deep Reinforcement Learning: An Overview, which has received 100+ citations, by extending its latest version more than one year ago from 70 pages to 150 pages.
It draws a big picture of deep reinforcement learning (RL) with many details. It covers contemporary work in historical contexts. It endeavours to answer the following questions: 1) Why deep? 2) What is the state of the art? and, 3) What are the issues, and potential solutions? It attempts to help those who want to get more familiar with deep RL, and to serve as a reference for people interested in this fascinating area, like professors, researchers, students, engineers, managers, investors, etc. Shortcomings and mistakes are inevitable; comments and criticisms are welcome.
The manuscript introduces AI, machine learning, and deep learning briefly, and provides a mini tutorial for reinforcement learning. The following figure illustrates relationships among these concepts, with major contents for machine learning and AI .Deep reinforcement learning is reinforcement learning integrated with deep learning, or deep artificial neural networks. A blog is dedicated to Resources for Deep Reinforcement Learning.

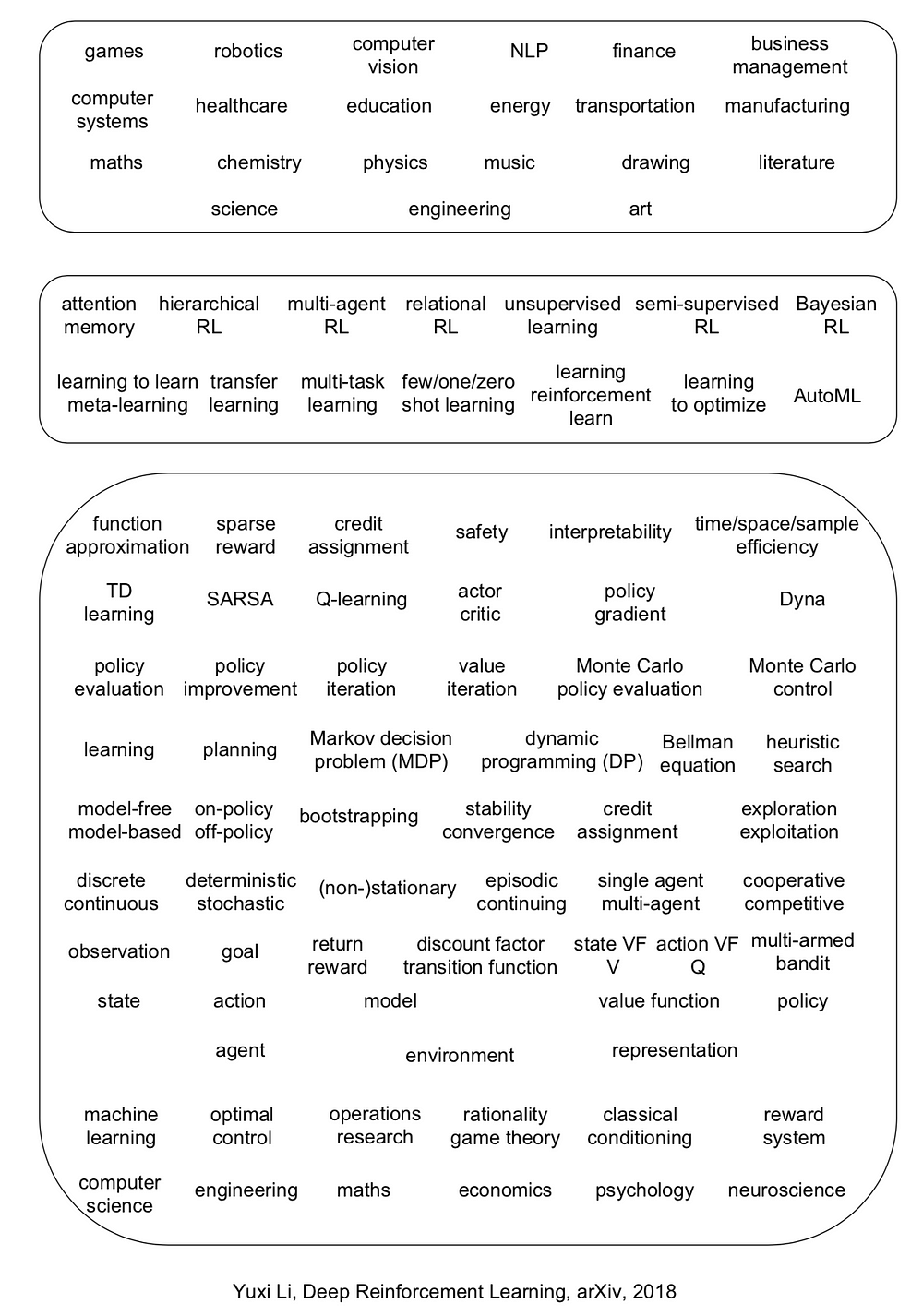
The manuscript covers six core elements: value function, policy, reward, model, exploration vs. exploitation, and representation; six important mechanisms: attention and memory, unsupervised learning, hierarchical RL, multi-agent RL, relational RL, and learning to learn; and twelve applications: games, robotics, natural language processing (NLP), computer vision, finance, business management, healthcare, education, energy, transportation, computer systems, and, science, engineering, and art.

Deep reinforcement learning has made exceptional achievements, e.g., DQN applying to Atari games ignited this wave of deep RL, and AlphaGo (Zero) and DeepStack set landmarks for AI. Deep RL has many newly invented algorithms/architectures, e.g., DQN, A3C, TRPO, PPO, DDPG, Trust-PCL, GPS, UNREAL, DNC, etc. Moreover, deep RL has been enjoying very abound and diverse applications, e.g., Capture the Flag, Dota 2, StarCraft II, robotics, character animation, conversational AI, neural architecture design (AutoML), data center cooling, recommender systems, data augmentation, model compression, combinatorial optimization, program synthesis, theorem proving, medical imaging, music, and chemical retrosynthesis, so on and so forth. A blog is dedicated to Reinforcement Learning applications.
In general, RL is probably helpful, if a problem can be regarded as or transformed to a sequential decision making problem, and states, actions, maybe rewards, can be constructed; sometimes the problem may not appear as an RL problem on the surface. Roughly speaking, if a task involves some manual designed “strategy”, then there is a chance for reinforcement learning to help. Creativity would push the frontiers of deep RL further with respect to core elements, important mechanisms, and applications.
Albeit being so successful, deep RL encounters many issues, like credit assignment, sparse reward, sample efficiency, instability, divergence, interpretability, safety, etc.; even reproducibility is an issue.
Six research directions are proposed as both challenges and opporrtunities. There are already some progress in these directions, e.g., Dopamine, TStarBots, MOREL, GQN, visual reasoning, neural-symbolic learning, UPN, causal InfoGAN, meta-gradient RL, along with many applications as above.
- systematic, comparative study of deep RL algorithms
- “solve” multi-agent problems
- learn from entities, but not just raw inputs
- design an optimal representation for RL
- AutoRL
- develop killer applications for (deep) RL
It is desirable to integrate RL more deeply with AI, with more intelligence in the end-to-end mapping from raw inputs to decisions, to incorporate knowledge, to have common sense, to be more efficient, to be more interpretable, and to avoid obvious mistakes, etc., rather than working as a blackbox.

Deep learning and reinforcement learning, being selected as one of the MIT Technology Review 10 Breakthrough Technologies in 2013 and 2017 respectively, will play their crucial roles in achieving artificial general intelligence. David Silver proposed a conjecture: artificial intelligence = reinforcement learning + deep learning (AI = RL + DL). We will see both deep learning and reinforcement learning prospering in the coming years and beyond. Deep learning is exploding. It is the right time to nurture, educate and lead the market for reinforcement learning.
Deep learning, in this third wave of AI, will have deeper influences, as we have already seen from its many achievements. Reinforcement learning, as a more general learning and decision making paradigm, will deeply influence deep learning, machine learning, and artificial intelligence in general.
Introducing Deep Reinforcement的更多相关文章
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- Learning Roadmap of Deep Reinforcement Learning
1. 知乎上关于DQN入门的系列文章 1.1 DQN 从入门到放弃 DQN 从入门到放弃1 DQN与增强学习 DQN 从入门到放弃2 增强学习与MDP DQN 从入门到放弃3 价值函数与Bellman ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
随机推荐
- CentOS 下安装和使用 Docker
引言: 在服务器开发过程中,环境部署无疑是及其繁琐的事情,特别是当项目数量和规模达到一定级别之后,在一台新的机器上部署项目环境无疑是极其漫长而痛苦的,那么什么办法能够实现我们的目标:在开发环境的一次配 ...
- matlab max()
max()函数 (1)可以找出矩阵元素中每列的最大值 max(A) ,max(A,[],dim ),带返回值的[C,I]=max(A).[C,I]=max(A,[],dim) max(A,[],dim ...
- git中的标签
/*游戏或者运动才能让我短暂的忘记心痛,现如今感觉学习比游戏和运动还重要——曾少锋*/ 1.创建标签: 对于标签来说大家都很熟悉,简单说就是将一个很长的门牌号用另外一个名字来取代,并且好记. 其实利 ...
- HDU 2009
求数列的和 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submiss ...
- CTF密码学之摩斯密码
通过不用的排列顺序来表达不用的英文字母,数字和标点符号,摩斯电码由.和_构成 字母 字符 电码符号 字符 电码符号 A ._ N _. B _... O _ _ _ C _._. P ._ _. D ...
- 一键分享到各个SNS插件
使用百度分享:http://share.baidu.com/code/advance#toid 例: HTML: <div class="bdsharebuttonbox" ...
- spket插件的安装与使用完整图文版
下载最新破解版的spket1.6.18(见下面附件) 对于目前的MyEclipse的插件安装是很简单的,把spket1.6.18破解版.zip解压后直接复制到MyEclipse安装目录的dropins ...
- day32 多进程
一 multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程. ...
- poj 2449 Remmarguts' Date(K短路,A*算法)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u013081425/article/details/26729375 http://poj.org/ ...
- Tensoflw.js - 01 - 安装与入门(中文注释)
Tensoflw.js - 01 - 安装与入门(中文注释) 参考 W3Cschool 文档:https://www.w3cschool.cn/tensorflowjs/ 本文主要翻译一些英文注释,添 ...