大数据hadoop与spark的区别
学习hadoop已经有很长一段时间了,好像是二三月份的时候朋友给了一个国产Hadoop发行版下载地址,因为还是在学习阶段就下载了一个三节点的学习版玩一下。在研究、学习hadoop的朋友可以去找一下看看(发行版 大快DKhadoop,去大快的网站上应该可以下载到的。)
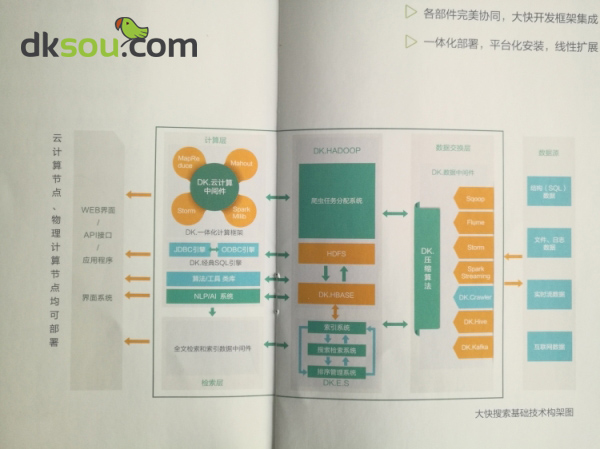
在学习hadoop的时候查询一些资料的时候经常会看到有比较hadoop和spark的,对于初学者来说难免会有点搞不清楚这二者到底有什么大的区别。我记得刚开始接触大数据这方面内容的时候,也就这个问题查阅了一些资料,在《FreeRCH大数据一体化开发框架》的这篇说明文档中有就Hadoop和spark的区别进行了简单的说明,但我觉得解释的也不是特别详细。我把个人认为解释的比较好的一个观点分享给大家:
它主要是从四个方面对Hadoop和spark进行了对比分析:
1、目的:首先需要明确一点,hadoophe spark 这二者都是大数据框架,即便如此二者各自存在的目的是不同的。Hadoop是一个分布式的数据基础设施,它是将庞大的数据集分派到由若干台计算机组成的集群中的多个节点进行存储。Spark是一个专门用来对那些分布式存储的大数据进行处理的工具,spark本身并不会进行分布式数据的存储。
2、两者的部署:Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。所以使用Hadoop则可以抛开spark,而直接使用Hadoop自身的mapreduce完成数据的处理。Spark是不提供文件管理系统的,但也不是只能依附在Hadoop上,它同样可以选择其他的基于云的数据系统平台,但spark默认的一般选择的还是hadoop。
3、数据处理速度:Spark,拥有Hadoop、 MapReduce所具有能更好地适用于数据挖掘与机器学习等需要迭代的的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,
Spark 是一种与hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
4、数据安全恢复:Hadoop每次处理的后的数据是写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理;spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集中,这些数据对象既可以放在内存,也可以放在磁盘,所以spark同样可以完成数据的安全恢复。
大数据hadoop与spark的区别的更多相关文章
- [转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别 https://www.cnblogs.com/adnb34g/p/9233906.html Posted on 2018-06-27 14:43 左手中倒影 阅 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据 Hadoop,Spark和Storm
大数据(Big Data) 大数据,官方定义是指那些数据量特别大.数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理.大数据的主要特点为数据量大(Volume),数据类别复 ...
- 大数据Hadoop与Spark学习经验谈
昨晚听了下Hulu大数据基础架构组负责人–董西成的关于大数据学习方法的直播,挺有收获的,下面截取一些PPT的关键内容,希望对正在学习大数据的人有帮助. 现状是目前存在的问题,比如找百度.查书这种学习方 ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
随机推荐
- Activiti工作流笔记(2)
1.Activiti工作数据表 Activiti用来存放流程数据的表共使用23张表,表名都是以"ACT_"开头,底层操作默认使用mybatis操作 工作流Activiti的表是用来 ...
- OC Copy和内存管理
- java并发编程:线程安全管理类--原子操作类--AtomicReferenceArray<E>
1.类 AtomicReferenceArray<E> public class AtomicReferenceArray<E>extends Objectimplements ...
- POJ 1166 暴力搜索 即 枚举
e.... 米还是没有读懂题....T_T ..... e.... 这就是传说中的暴力吗....太血腥了....太暴力了...九重for循环....就这么赤裸裸的AC了.... 水是水了点..但是.. ...
- SQL Server 调优系列基础篇 - 并行运算总结(二)
前言 上一篇文章我们介绍了查看查询计划的并行运行方式. 本篇我们接着分析SQL Server的并行运算. 闲言少叙,直接进入本篇的正题. 技术准备 同前几篇一样,基于SQL Server2008R2版 ...
- 51nod1615
题解: 首先,当1+2+...+n=x时,答案就是n 如果1+2+...+n不会等于x,那么找一个最小的n,让1+2+....+n>x并且(1+2+.....+n-x)%2=0 代码: #inc ...
- L1-045 宇宙无敌大招呼
据说所有程序员学习的第一个程序都是在屏幕上输出一句“Hello World”,跟这个世界打个招呼.作为天梯赛中的程序员,你写的程序得高级一点,要能跟任意指定的星球打招呼. 输入格式: 输入在第一行给出 ...
- 这是一个专注于电脑技术、软件应用、互联网、嵌入式,电子技术行业等的原创IT博客
http://www.choovin.com/ 这是一个专注于电脑技术.软件应用.互联网.嵌入式,电子技术行业等的原创IT博客
- JavaScript权威指南——跳转语句
前言:JavaScript中有一类语句叫做跳转语句.从名称就可以看出,它使得JavaScript的执行可以从一个位置跳转到另一个位置. return语句让解释器跳出循环体的执行,并提供本次调用的返回值 ...
- Tomcat结合nginx使用入门
Nginx: Nginx是一款高性能,轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器. 特点是:占有内存少,并发能力强. 反向代理服务器: 反向代理(Reverse ...