需要弥补的那部分SQL
一、前言
虽然我们大多数人都学习过SQL,但是经常忽略它。总是会自以为学到的已经足够用了,从而导致我们在实际开发的过程中遇到复杂的问题后只能在检索数据后通过传统的代码来完成,但是其中很多的功能利用SQL就可以轻松的办到,所以我们开始重视SQL,它的地位不亚于C#,javascript。
二、目录
三、正文
1.多行插入
大家都学习过INSERT,但是每次我们都只插入一条数据,如果我们需要插入多条数据呢,那么情况就会和图1.1一样。
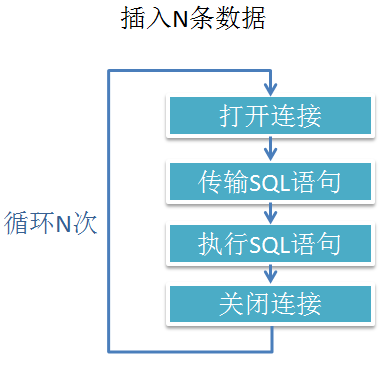
图1.1
上面是最简单的示例,我们还可以进行一定的优化,避免循环建立和关闭连接的次数,比如下图(图1.2)
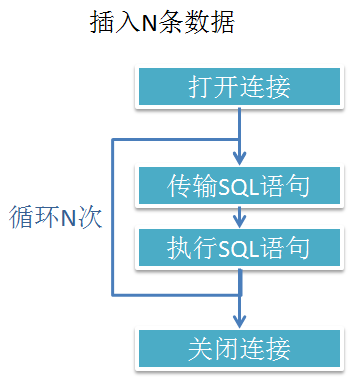
图1.2
即使我们采用了图1.2所示的方式,既然会长时间的占据带框,并且Web服务器和数据库服务器既然要进行多次连接,如果使用本节的知识我们就可以做到图1.3所示的效果。
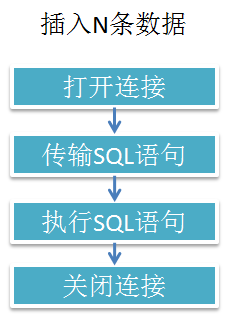
图1.3
首先我们先来看看普通的插入语句:
INSERT INTO Cou_Course(CourseID,TeacherID,SemesterID,CourseName,CourseType,CourseState)
VALUES('','','','awefweagwaeg','','')
每次插入一条新的数据都要重新一次,如果是批量的添加就可想而知了,而如果我们直接通过一条插入语句插入多条数据就可以这样做:
INSERT INTO Cou_Course(CourseID,TeacherID,SemesterID,CourseName,CourseType,CourseState)
VALUES('','','','awefweagwaeg','',''),
('','','','awefweagwaeg','',''),
('','','','awefweagwaeg','','')
当然语法也很简单,只要用逗号来分割就可以了。虽然仅仅只是一个简单的技巧,但是又有多少人会使用呢?
2.将其他表数据插入
解决了批量插入的问题,我们还会遇到将其他表的数据插入到另一个表中的需求,特别是在编写存储过程中我们可能会对数据进行处理,并把处理的结果存放在临时表中,最后才将临时表中的数据全部添加到实际的表中,如果利用传统的做法会非常麻烦,而通过本节介绍的知识将可以很轻松的实现。
首先我们需要做一些简单的准备工作,这里我们需要创建两个表,A表(id为自增),B表跟A表一样,然后我们在A表中随意写一些内容:

然后利用 INSERT INTO … SELECT … 来实现将A表的数据添加到B表中去:
INSERT INTO B(Name) SELECT Name FROM A
当然读者看过之后会觉得非常简单,因为我们现在仅仅只是学习这个知识点,重点在于我们能够记住它,并能够在后面使用它(实际开发中会比这更复杂,但是基本的东西还是不变的)
3.子查询
在正常的使用中我们经常会遇到无法使用链接的情况,但是我们需要根据另一个表的情况来决定当前的SELECT,这个时候我们就需要子查询。笔者在这里只能例举简单的示例,实际的需求会出现非常复杂的子查询。这里我们还是借助上面的A、B表,首先实现的功能是检索A表,但是条件是A表的Name要在B表中存在:
SELECT id,Name FROM A
WHERE EXISTS(
SELECT Name FROM B
WHERE B.Name = A.Name
)
上面的语句中我们在WHERE中就使用了子查询负责去B表中查询是否存在记录,而EXISTS的作用就是EXISTS括号中的语句只要返回了一个或一个以上的结果则成立。所以最后我们可以看到所有的数据都呈现了。当然子查询不仅仅可以用于条件中,我们还可以用于SELECT后,比如我们根据A表的Name去B表中查询Name跟它一样的id号:
SELECT (SELECT TOP 1 B.id FROM B WHERE B.Name = A.Name) FROM A
子查询的用处非常多,也非常强大,远不止笔者这里介绍的这么一点。
4.通用表表达式(CTE)
虽然这个名字很专业,但是实际用起来是非常简单的,当然简单的同时也帮助我们解决了很多的问题,最终的效果跟临时表一样,但是使用起来比临时表更方便。比如下面的代码我们将创建一个名为MyCTE的临时表:
WITH MyCTE AS(
SELECT * FROM A
)
SELECT * FROM MyCTE
是不是非常简单,当然还可以同时定义多个通用表,比如下面的代码所示:
WITH MyCTE AS(
SELECT * FROM A
), MyCTE2 AS(
SELECT * FROM B
)
SELECT * FROM MyCTE,MyCTE2
多个通用表只需要用逗号分割即可,当然我们这里还涉及了一个知识点,相信有人会发觉出来。
5.MERGE指令
这个指令是SQL SERVER 2008中新增的,相比前面几个来说比较难懂,但是作用却非常强大,利用这个指令我们可以同时进行添加、修改和删除,并且是由条件的。具体的实现方式就是根据源表与目标表进行对比,如果匹配则执行对应的更新操作,如果源表中存在,但是目标表不存在则执行添加操作,如果相反则执行删除操作。下面我们将通过循序渐进的方式来介绍如何使用MERGE,首先我们需要确定目标表,因为后面的更新,添加和删除操作都是针对目标表的,所以目标表只能是一个表不能是检索后的数据,比如下面的代码我们将前面我们示例中使用的A表作为目标表:
MERGE A AS itarget
有了目标表还不足够,我们还要需要一个源表,用来形成对比,而源表则可以是检索语句,因为笔者这里只是简单的示例,所以直接检索了B表中的数据:
USING(
SELECT * FROM B
) AS isource
这样我们就有了目标表和源表,最后合并:
MERGE A AS itarget
USING(
SELECT * FROM B
) AS isource
接着我们需要指定对应的条件,从而根据是否符合这个条件而决定对目标表进行什么操作,比如下面的语句将判断两表中是否存在相同id的数据:
ON (itarget.id = isource.id)
有了条件后,我们就可以根据这个条件进行对应的操作了,笔者将在满足这个条件后修改目标表的Name,在后面追加change字符串:
WHEN MATCHED THEN
UPDATE SET itarget.Name = itarget.Name + 'change'
最后的语句如下所示:
MERGE A AS itarget
USING(
SELECT * FROM B
) AS isource
ON (itarget.id = isource.id)
WHEN MATCHED THEN
UPDATE SET itarget.Name = itarget.Name + 'change';
最后我们查看A表,发现数据都改变了:

这个时候我们在A表新添加一条数据,以满足源表不匹配的情况,然后在原本的语句后面添加如下的语句:
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
我们可以猜测出,当目标表中存在源表中不存在的数据后将会删除这条数据,所以执行后我们将看到A表新添加的数据已经被删除了,完整的语句如下所示:
MERGE A AS itarget
USING(
SELECT * FROM B
) AS isource
ON (itarget.id = isource.id)
WHEN MATCHED THEN
UPDATE SET itarget.Name = itarget.Name
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
最后就是源表中存在,但是目标表中不存在的情况了,我们只需要将上面的BY SOURCE改成BY TARGET即可,通过下面这条语句我们将把源表与目标表不匹配的数据添加到目标表中去(当然我们需要提前在源表中新增一条数据):
WHEN NOT MATCHED BY TARGET THEN
INSERT (Name) VALUES(isource.Name);
执行完成后我们将看到A表多了几条数据。下面是完整的语句:
MERGE A AS itarget
USING(
SELECT * FROM B
) AS isource
ON (itarget.id = isource.id)
WHEN MATCHED THEN
UPDATE SET itarget.Name = itarget.Name
WHEN NOT MATCHED BY SOURCE THEN
DELETE
WHEN NOT MATCHED BY TARGET THEN
INSERT (Name) VALUES(isource.Name);
6.窗口化函数
首先是ROW_NUMBER,顾名思义,就是给我们检索出来的数据加上序号,旧的分页都是采用这种方式,但是往往我们仅仅只是使用了它的一点,他还可以分块进行标序号,比如我们将上面的A表改成如下形式:

然后采用如下所示的SQL语句,就可以按照Name进行标序号:
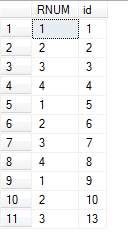
SELECT ROW_NUMBER() OVER(PARTITION BY A.Name ORDER BY A.id) AS 'RNUM',id FROM A
结果如下所示:
下面我们通过一段SQL以及对应的结果呈现其他的窗口化函数:
SELECT ROW_NUMBER() OVER(PARTITION BY A.Name ORDER BY A.id) AS 'RNUM',
RANK() OVER(ORDER BY A.Name) AS 'RANK',
DENSE_RANK() OVER(ORDER BY A.Name) AS 'DENSE RANK',
NTILE(4) OVER(ORDER BY A.id) AS 'NTILE' FROM A
结果如下所示:
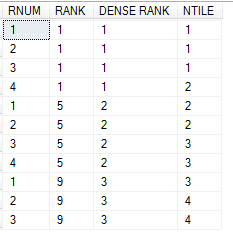
其中简单介绍下NTILE,我们传了一个4那么它会将前面1/4标记为1,然后接着标记1/4为2,以此类推。关于RANK和DENSE_RANK比较好理解,看看最后的结果就可以得出结论了。
7.分页查询
这是最后一节了,但是相关的语句却很简单,我们只要记住以下关键字就可以了:
OFFSET…FETCH NEXT…
比如下面的SQL语句,我们将跳过前面5条数据,获取3条数据:
SELECT * FROM A
ORDER BY A.id
OFFSET 5 ROWS
FETCH NEXT 3 ROWS ONLY
需要弥补的那部分SQL的更多相关文章
- 如何从Python负零基础到精通数据分析
一.为什么学习数据分析 1.运营的尴尬:运营人需要一个硬技能每个初入行的新人都会察觉到,运营是一个似乎并没有自己的核心竞争力和安全感的工作.因为每天的工作好像都被各种琐事所围绕,而只有一个主题是永恒不 ...
- 防止SQL注入攻击
了解了SQL注入的方法,如何能防止SQL注入?如何进一步防范SQL注入的泛滥?通过一些合理的操作和配置来降低SQL注入的危险. 使用参数化的过滤性语句 要防御SQL注入,用户的输入就绝对不能直接被嵌入 ...
- Atitit sql计划任务与查询优化器--统计信息模块
Atitit sql计划任务与查询优化器--统计信息模块 每一个统计信息的内容都包含以上三部分的内容. 我们依次来分析下,通过这三部分内容SQL Server如何了解该列数据的内容分布的. a.统计信 ...
- 积累一下SQL
开篇先自我检讨一下,写了博客几年以来首次试过连续两个月没出过博文,有客观也有主观原因,但是最近这年里博文数量也越来越少,博文的质量也每况日下.希望自己一直能坚持下来,多写写博文,这月尽量多写几篇来弥补 ...
- 即使用ADO.NET,也要轻量级动态生成更新SQL,比Ormlite性能更高
先上测试结果: //测试1000次针对同一个表同一个字段更新,比Ormlite平均快2.34倍 //生成SQL+ExecuteNonQuery Ormlite 倍数 //6513ms 15158ms ...
- Sql常用语法以及名词解释
Sql常用语法以及名词解释 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) D ...
- ORACLE常用SQL优化hint语句
在SQL语句优化过程中,我们经常会用到hint,现总结一下在SQL优化过程中常见Oracle HINT的用法: 1. /*+ALL_ROWS*/ 表明对语句块选择基于开销的优化方法,并获得最佳吞吐量, ...
- SQL SERVER 简介及应用 - 数据库系统原理
SQL SERVER 是一个分布式的关系型数据库管理系统(RDBMS),具有客户 - 服务器体系结构,一般发行的版本有企业版.标准版.个人版.开发版. SQL SERVER 提供的服务 MS SQL ...
- 不可小觑的SQL语句
在前面学的我们通过点鼠标给数据表插数据,虽然这种方法很靠谱,但是有那么的一些缺点,就是比较麻烦和效率不高.所以现在我们的好好学SQL语句,来弥补这么的一个漏洞,能提高我们工作的效率. SQL语句能做什 ...
随机推荐
- QuerySet创建新对象的方法和获取对象的方法
新建一个对象的方法有以下几种: Person.objects.create(name=name,age=age) p = Person(name="WZ", age=23) p.s ...
- vim总结
1.vim基础用法 注:该思维导图来自笔者<Linux就该这么学>读书笔记. 移动光标: 命令 描述 k 向上移动光标(移动一行) j 向下移动光标(移动一行) h 向左移动光标(移动一个 ...
- 如何进行服务器的批量管理以及python 的paramiko的模块
最近对公司的通道机账号进行改造管理,全面的更加深入的理解了公司账号管理的架构.(注:基本上所有的机器上的ssh不能使用,只有部分机器能够使用.为了安全的角度考虑,安装的不是公版的ssh,而都是定制版的 ...
- [Tomcat 源码分析系列] (附件) : catalina.bat 脚本
摘自 apache-tomcat-8.0.39-src 源码包中的 catalina.bat 脚本内容 @echo off rem Licensed to the Apache Software Fo ...
- Web前端之html_day1
1.html结构 1 2 3 4 5 6 7 8 9 10 <!DOCTYPE html> <html lang="en"> <head> ...
- notepad++ 右键
在网上搜索建立reg 后运行, 虽然右键菜单出现了建立的右键项目名,但与软件不关联 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\*\ ...
- 【软件工程】电梯调度的初步实现 李亚文&&郭莉莉
一.开门见山,代码粘 using System; using System.Collections.Generic; using System.Data; using System.Drawing; ...
- Tomcat启动过程中找不到JAVA_HOME解决方法
在XP上明明已经安装了JDK1.5并设置好了JAVA_HOME,可偏偏Tomcat在启动过程中找不到. 报错信息如下:Neither the JAVA_HOME nor the JRE_HOME en ...
- Google上的Cookie Matching
Cookie Matching This guide explains how the Cookie Matching Service enables you to make more effecti ...
- 开发Android应用怎么更改LOGO图标
开发安卓应用怎么更改LOGO图标,我们知道我们开发安卓程序的时候,都需要给他整一个logo,一般开发程序都会自动一个图标,我们怎么给他更换自己想要的logo图标,之前大家看过我们写的怎么安装程序到虚拟 ...