【学习】005 线程池原理分析&锁的深度化
线程池
什么是线程池
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序
都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
线程池作用
线程池是为突然大量爆发的线程设计的,通过有限的几个固定线程为大量的操作服务,减少了创建和销毁线程所需的时间,从而提高效率。
如果一个线程的时间非常长,就没必要用线程池了(不是不能作长时间操作,而是不宜。),况且我们还不能控制线程池中线程的开始、挂起、和中止。
线程池的分类
ThreadPoolExecutor
Java是天生就支持并发的语言,支持并发意味着多线程,线程的频繁创建在高并发及大数据量是非常消耗资源的,因为java提供了线程池。在jdk1.5以前的版本中,线程池的使用是及其简陋的,但是在JDK1.5后,有了很大的改善。JDK1.5之后加入了java.util.concurrent包,java.util.concurrent包的加入给予开发人员开发并发程序以及解决并发问题很大的帮助。这篇文章主要介绍下并发包下的Executor接口,Executor接口虽然作为一个非常旧的接口(JDK1.5 2004年发布),但是很多程序员对于其中的一些原理还是不熟悉,因此写这篇文章来介绍下Executor接口,同时巩固下自己的知识。如果文章中有出现错误,欢迎大家指出。
Executor
框架的最顶层实现是ThreadPoolExecutor类,Executors工厂类中提供的newScheduledThreadPool、newFixedThreadPool、newCachedThreadPool方法其实也只是ThreadPoolExecutor的构造函数参数不同而已。通过传入不同的参数,就可以构造出适用于不同应用场景下的线程池,那么它的底层原理是怎样实现的呢,这篇就来介绍下ThreadPoolExecutor线程池的运行过程。
corePoolSize: 核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中
maximumPoolSize: 线程池最大线程数,它表示在线程池中最多能创建多少个线程;
keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。
unit: 参数keepAliveTime的时间单位
线程池四种创建方式
Java通过Executors(jdk1.5并发包)提供四种线程池,分别为:
Executors.newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
Executors.newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
Executors.newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
Executors.newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
Executors.newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。示例代码如下:
// 可缓存的线程池,线程可重复利用
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++)
{
int temp = i;
newCachedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
System.out.println("threadName:" + Thread.currentThread().getName() + ",i:" + temp);
}
});
}
//关闭线程池
newCachedThreadPool.shutdown();
总结: 线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
Executors.newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。示例代码如下:
// 可固定长度线程池
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++)
{
int temp = i;
newFixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
// 关闭线程池
newFixedThreadPool.shutdown();
总结:定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
Executors.newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。延迟执行示例代码如下:
package hongmoshui.com.cnblogs.www.study.day05; public class WorkerThread implements Runnable
{ private int i = 1; private long runTime = 0; WorkerThread(long runTime)
{
this.runTime = runTime;
} @Override
public void run()
{
System.out.println(Thread.currentThread().getName() + " Start.i = " + i);
processCommand();
System.out.println(Thread.currentThread().getName() + " End.i = " + i);
i++;
} private void processCommand()
{
try
{
Thread.sleep(runTime);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
package hongmoshui.com.cnblogs.www.study.day05; import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit; public class ScheduledThreadPool
{ public static void main(String[] args) throws InterruptedException
{
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
// 创建一个线程,线程模拟执行时间为2s
WorkerThread worker = new WorkerThread(2000);
// 可定时线程池,定时开始执行【这里设置为5s后开始执行】
scheduledThreadPool.schedule(worker, 5, TimeUnit.SECONDS);
/*
* 可定时线程池,定时开始执行,然后以固定的频率来循环执行某项计划(任务)
* 如果period【设置的频率,即执行单位时间】>线程执行时间,
* 则按设置的period单位时间执行,否则period不起作用,按照线程执行时间来循环执行任务
*/
scheduledThreadPool.scheduleAtFixedRate(worker, 0, 5, TimeUnit.SECONDS);
/*
* 可定时线程池,定时开始执行,然后以固定时间延迟时间来循环执行某项计划(任务)
* 【相对与线程执行完后的时间延迟,即:实际间隔时间=线程执行时间+设置间隔时间】
*/
scheduledThreadPool.scheduleWithFixedDelay(worker, 0, 1, TimeUnit.SECONDS); Thread.sleep(10000);
scheduledThreadPool.shutdown();
while (!scheduledThreadPool.isTerminated())
{
}
System.out.println("Finished all threads");
} }
Executors.newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。示例代码如下:
// 单线程
ScheduledExecutorService newSingleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
for (int i = 0; i < 10; i++)
{
int temp = i;
newSingleThreadScheduledExecutor.execute(new Runnable()
{
@Override
public void run()
{
try
{
Thread.sleep(1000);
}
catch (Exception e)
{
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
// 关闭线程池
newSingleThreadScheduledExecutor.shutdown();
线程池原理剖析
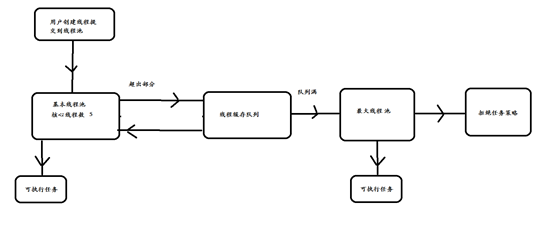
提交一个任务到线程池中,线程池的处理流程如下:
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
合理配置线程池
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。【什么是CPU密集型、IO密集型?】
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
Java锁的深度化
悲观锁、乐观锁、排他锁
数据库乐观锁机制
数据中的锁分为两类:悲观锁和乐观锁,锁还有表级锁、行级锁
表级锁例如:
SELECT * FROM table WITH (HOLDLOCK) 其他事务可以读取表,但不能更新删除
SELECT * FROM table WITH (TABLOCKX) 其他事务不能读取表, 更新和删除
行级锁例如:
select * from table_name where id = 1 for update;
悲观锁(Pressimistic Locking)
对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。例如:
select * from table_name where id = ‘xxx’ for update;
这样查询出来的这一行数据就被锁定了,在这个update事务提交之前其他外界是不能修改这条数据的,但是这种处理方式效率比较低,一般不推荐使用。
乐观锁(Optimistic Locking)
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几百上千个并发,这样的情况将导致怎样的后果。
乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
乐观锁的实现:
Update Account set field1=? and field2=? and version = version+1 where version = ?...(another contidition)
重入锁
锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如 synchronized 和 ReentrantLock等等 ) 。这些已经写好提供的锁为我们开发提供了便利。
重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。
在JAVA环境下 ReentrantLock 和synchronized 都是 可重入锁
package hongmoshui.com.cnblogs.www.study.day05; import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock; public class Test002 extends Thread
{
private Lock lock = new ReentrantLock(); public void get()
{
lock.lock();
try
{
Thread.sleep(10);
}
catch (Exception e)
{
e.printStackTrace();
}
System.out.println(Thread.currentThread().getId() + ",get");
set();
lock.unlock();
} public void set()
{
// lock.lock();
try
{
Thread.sleep(10);
}
catch (Exception e)
{
e.printStackTrace();
}
System.out.println(Thread.currentThread().getId() + ",set");
// lock.unlock(); } @Override
public void run()
{
get();
} public static void main(String[] args)
{
Test002 ss = new Test002();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
} }
读写锁
相比Java中的锁(Locks in Java)里Lock实现,读写锁更复杂一些。假设你的程序中涉及到对一些共享资源的读和写操作,且写操作没有读操作那么频繁。在没有写操作的时候,两个线程同时读一个资源没有任何问题,所以应该允许多个线程能在同时读取共享资源。但是如果有一个线程想去写这些共享资源,就不应该再有其它线程对该资源进行读或写(译者注:也就是说:读-读能共存,读-写不能共存,写-写不能共存)。这就需要一个读/写锁来解决这个问题。Java5在java.util.concurrent包中已经包含了读写锁。尽管如此,我们还是应该了解其实现背后的原理。
package hongmoshui.com.cnblogs.www.study.day05; import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock; public class Cache
{ static private volatile Map<String, Object> map = new HashMap<>(); static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
static Lock read = rwl.readLock();
// 写锁
static Lock write = rwl.writeLock(); /**
* 写
*/
static public Object put(String key, Object value)
{
try
{
write.lock();
System.out.println("正在写入 key:" + key + ",value:" + value + "开始.....");
try
{
Thread.sleep(100);
}
catch (Exception e)
{
e.printStackTrace();
}
Object oj = map.put(key, value);
System.out.println("正在写入 key:" + key + ",value:" + value + "结束.....");
System.out.println();
return oj;
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
write.unlock();
}
return value;
} /**
* 读
*/
static public void get(String key)
{
try
{
read.lock();
System.out.println("正在读取 key:" + key + "开始");
try
{
Thread.sleep(100);
}
catch (Exception e)
{
e.printStackTrace();
}
Object value = map.get(key);
System.out.println("正在读取 key:" + key + ",value:" + value + "结束.....");
System.out.println();
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
read.unlock();
}
} public static void main(String[] args)
{
new Thread(new Runnable()
{
@Override
public void run()
{
for (int i = 1; i <= 10; i++)
{
Cache.put(i + "", i + "");
}
}
}).start();
new Thread(new Runnable()
{
@Override
public void run()
{
for (int i = 1; i <= 10; i++)
{
Cache.get(i + "");
}
}
}).start();
} }
CAS无锁机制
(1)与锁相比,使用比较交换(下文简称CAS)会使程序看起来更加复杂一些。但由于其非阻塞性,它对死锁问题天生免疫,并且,线程间的相互影响也远远比基于锁的方式要小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
(2)无锁的好处:
第一,在高并发的情况下,它比有锁的程序拥有更好的性能;
第二,它天生就是死锁免疫的。
就凭借这两个优势,就值得我们冒险尝试使用无锁的并发。
(3)CAS算法:
一个CAS方法包含三个参数CAS(V,E,N)。V表示要更新的变量,E表示预期的值,N表示新值。只有当V的值等于E时,才会将V的值修改为N。如果V的值不等于E,说明已经被其他线程修改了,当前线程可以放弃此操作,也可以再次尝试次操作直至修改成功。基于这样的算法,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰(临界区值的修改),并进行恰当的处理。
- 额外引申技术点:volatile
上面说到当前线程可以发现其他线程对临界区数据的修改,这点可以使用volatile进行保证。volatile实现了JMM中的可见性。使得对临界区资源的修改可以马上被其他线程看到,它是通过添加内存屏障实现的。具体实现原理请自行搜索**volatile**
(4)CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
(5)简单地说,CAS需要你额外给出一个期望值,也就是你认为这个变量现在应该是什么样子的。如果变量不是你想象的那样,那说明它已经被别人修改过了。你就重新读取,再次尝试修改就好了。
(6)在硬件层面,大部分的现代处理器都已经支持原子化的CAS指令。在JDK 5.0以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且,这种操作在虚拟机中可以说是无处不在。
自旋锁
自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时 才能进入临界区。如下:
package hongmoshui.com.cnblogs.www.study.day05; import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicReference; /**
* 自旋锁
* @author 洪墨水
*/
public class SpinLock
{
// 用于判断是否是新线程进入等待区
Map<String, Thread> map = new ConcurrentHashMap<>();
// 原子性操作Object【对象】
private AtomicReference<Thread> spin = new AtomicReference<Thread>(); /**
* 上锁
* @author 洪墨水
*/
public void lock()
{
Thread current = Thread.currentThread();
String currentThreadName = current.getName();
while (!spin.compareAndSet(null, current))
{
if (!map.containsKey(currentThreadName))
{
map.put(currentThreadName, current);
System.out.println("线程:" + currentThreadName + ",正在等待...");
}
}
} /**
* 释放锁
* @author 洪墨水
*/
public void unlock()
{
Thread current = Thread.currentThread();
spin.compareAndSet(current, null);
}
}
package hongmoshui.com.cnblogs.www.study.day05; public class TestRunnable implements Runnable
{
private SpinLock spinLock; public TestRunnable(SpinLock spinLock)
{
this.spinLock = spinLock;
} @Override
public void run()
{
this.spinLock.lock();
try
{
Thread.sleep(1000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
String currentThreadName = Thread.currentThread().getName();
System.out.println("----------------------------------------");
System.out.println("线程:" + currentThreadName + ",执行中...");
System.out.println("线程:" + currentThreadName + "准备退出...");
this.spinLock.unlock();
System.out.println("线程:" + currentThreadName + "退出成功...");
} public static void main(String[] args)
{
SpinLock spinLock = new SpinLock();
for (int i = 1; i <= 3; i++)
{
TestRunnable testRunnable = new TestRunnable(spinLock);
Thread t = new Thread(testRunnable);
t.start();
}
} }
语句spin.compareAndSet(V expect, V update):如果 current【当前值】== expect【预期值】,则以原子方式将【当前值】设置为【更新值】,即 current = update
(1)使用了CAS原子操作,lock函数将owner设置为当前线程,并且预测原来的值为空。unlock函数将owner设置为null,并且预测值为当前线程。
(2)当有第二个线程调用lock操作时由于owner值不为空,导致循环一直被执行,直至第一个线程调用unlock函数将owner设置为null,第二个线程才能进入临界区。
(3)由于自旋锁只是将当前线程不停地执行循环体,不进行线程状态的改变,所以响应速度更快。但当线程数不停增加时,性能下降明显,因为每个线程都需要执行,占用CPU时间。如果线程竞争不激烈,并且保持锁的时间段。适合使用自旋锁。
注:该例子为非公平锁,获得锁的先后顺序,不会按照进入lock的先后顺序进行。
分布式锁
如果想在不同的jvm中保证数据同步,使用分布式锁技术。
有数据库实现、缓存实现、Zookeeper分布式锁
---------------------------------------------------------------------------------
关于锁的参考文章:Java中的锁分类 、Java并发之AQS详解
【学习】005 线程池原理分析&锁的深度化的更多相关文章
- java并发包&线程池原理分析&锁的深度化
java并发包&线程池原理分析&锁的深度化 并发包 同步容器类 Vector与ArrayList区别 1.ArrayList是最常用的List实现类,内部是通过数组实现的, ...
- Java 线程池原理分析
1.简介 线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销.在应用上,线程池可应用在后端相关服务中.比如 Web 服务器,数据库服务器等 ...
- 【java】-- 线程池原理分析
1.为什么要学习使用多线程? 多线程的异步执行方式,虽然能够最大限度发挥多核计算机的计算能力,但是如果不加控制,反而会对系统造成负担. 线程本身也要占用内存空间,大量的线程会占用内存资源并且可能会导致 ...
- 手写一个线程池,带你学习ThreadPoolExecutor线程池实现原理
摘要:从手写线程池开始,逐步的分析这些代码在Java的线程池中是如何实现的. 本文分享自华为云社区<手写线程池,对照学习ThreadPoolExecutor线程池实现原理!>,作者:小傅哥 ...
- Java线程池ThreadPoolExecutor使用和分析(三) - 终止线程池原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
- 《java学习三》并发编程 -------线程池原理剖析
阻塞队列与非阻塞队 阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞.试图从空的阻塞队列中获取元素的线程将会被阻塞,直到 ...
- 5分钟看懂系列:Python 线程池原理及实现
概述 传统多线程方案会使用"即时创建, 即时销毁"的策略.尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器 ...
- java多线程系类:JUC线程池:03之线程池原理(二)(转)
概要 在前面一章"Java多线程系列--"JUC线程池"02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包 ...
- Java多线程系列--“JUC线程池”03之 线程池原理(二)
概要 在前面一章"Java多线程系列--“JUC线程池”02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包括:线程池示例参考代 ...
随机推荐
- Conturbatio
Conturbatio Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total ...
- 使用@Test报java.lang.NullPointerException at org.eclipse.jdt.internal.junit4.runner.SubForestFilter.shouldRun(SubForestFilter.java:81)异常
对公司的项目进行二次开发时,在调试过程中用到@Test注解,运行使发现控制台报空指针异常,如图: 参考网上相应资料后,删除项目中自带的Junit4.jar,然后使用eclipse开发工具自带的Juni ...
- 主流Linux可视化运维面板&安装包
一.AMH面板 1.官方网站 官方网站:http://amh.sh 2.面板介绍 截止到AMH4. 2 版本都是提供免费安装的,后来从5. 0 开始提供付费安装,可以理解开发者的盈利问题,毕竟提供免费 ...
- 蒙特卡洛(Monte Carlo)方法求面积
如图,刷微博时,看到一个问题,第一个想到的就是用蒙特卡洛方法求解,当时正在练python,于是尝试用python编写程序. import random # 先求s1 k=0 n=100000000 f ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- java中 使用输入+输出流对对象序列化
对象: 注意记得实现 Serializable package com.nf147.sim.entity; import java.io.Serializable; public class News ...
- 史上最详细的XGBoost实战
史上最详细的XGBoost实战 0. 环境介绍 Python 版 本: 3.6.2 操作系统 : Windows 集成开发环境: PyCharm 1. 安装Python环境 安装Python 首先,我 ...
- canvas介绍(画布)
canvas(画布)主要是位图 svg(矢量图) canvas标签,必须要写的3个属性 id width height 为什么不再style中设置width和height呢? 因为这设置width和h ...
- 几个FFmpeg 视频参数 fps、tbr、tbn、tbc
我们用Ffplay播放文件或者视频流命令行会出现fps.tbr.tbn.tbc等参数如下图所示 图1 ffplay 播放文件示意图 fps表示平均帧率,总帧数除以总时长(以s为单位). tbr 表示 ...
- selinux 了解2
凡是对内核级, 如selinux的修改, 不只是对软件, 程序的修改, 那么修改之后都要重新启动. 针对windows下的截图, 像linux下的screenshot截图那样设置快捷键 shift+s ...