[Python数据挖掘]第3章、数据探索
1、缺失值处理:删除、插补、不处理
2、离群点分析:简单统计量分析、3σ原则(数据服从正态分布)、箱型图(最好用)
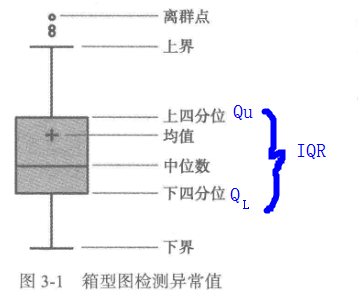
离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR
import pandas as pd catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列 import matplotlib.pyplot as plt #导入图像库
#plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
#plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.figure() #建立图像
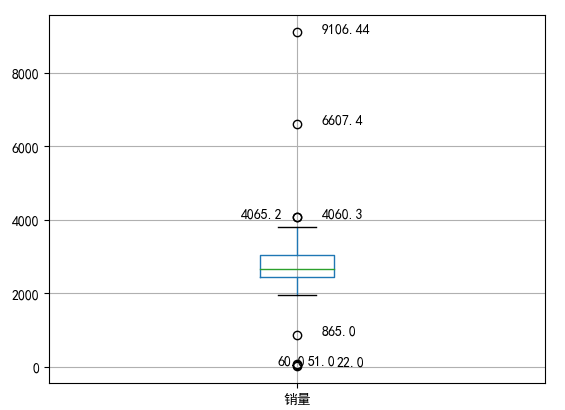
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'fliers'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象 #用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i])) plt.show() #展示箱线图
3、贡献度分析(帕累托分析,20/80定律)
import pandas as pd
import matplotlib.pyplot as plt #导入图像库 dish_profit = 'data/catering_dish_profit.xls' #餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()
data.sort_values(ascending = False) plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.show()

4、相关性分析(以餐饮数据为例)
导入数据

求相关系数的三种方式


5、统计作图函数



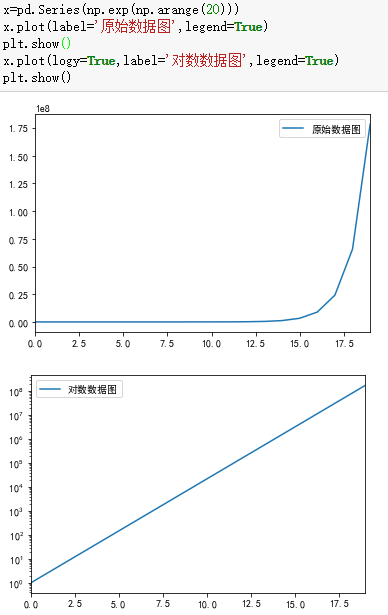
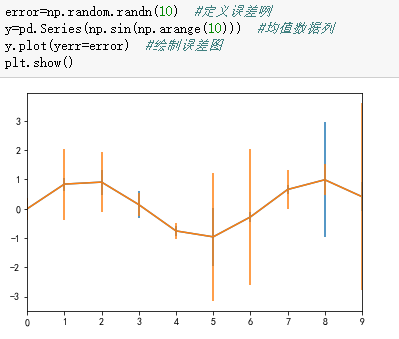
[Python数据挖掘]第3章、数据探索的更多相关文章
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- [Python数据挖掘]第5章、挖掘建模(上)
一.分类和回归 回归分析研究的范围大致如下: 1.逻辑回归 #逻辑回归 自动建模 import pandas as pd from sklearn.linear_model import Logist ...
- Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一.数据库风格的Dataframe合并 import pandas as pd import numpy as np df1 = pd.DataFrame({'1key':['b','b','a',' ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
随机推荐
- gitIgnore说明
有些内容不需要提交到git服务器上,这时我们可以配置.gitIgnore文件.可参考:https://www.cnblogs.com/kevingrace/p/5690241.html 可能有时候你会 ...
- 如何设置默认以管理员权限运行cmd
设置cmd以管理员权限运行 目的:创建或删除文件等命令时,需要管理员权限运行cmd(linux以root用户登录). 例如,创建日志目录. 方法一: 1.激活administrator用户 2 ...
- CentOS7 FTP安装与配置
1.FTP的安装 #安装yum install -y vsftpd #设置开机启动systemctl enable vsftpd.service #启动systemctl start vsftpd.s ...
- JAVA的第一次作业
读后感:这个学期开始接触一门新的学科就是JAVA,老师对这么学科介绍了很多,我也从中了解到了许多,它可能是相对于C语言而已可能要更加方便一些,也是现在世界上所用最多的语音(软件方面),C语言都是排在它 ...
- std unorder_map insert 和 emplace的区别
std::unordered_map<int, int > map; map.insert(std::make_pair(, )); map.insert(std::make_pair(, ...
- mysql本地安装
1.下载地址: https://downloads.mysql.com/archives/community/ 2.安装: 解压目录:D:\mysql\mysql-5.6.36-winx64 2.1. ...
- c语言中对于移位运算符的用法
//1 << 0 是把1 按2进制 左移0位,结果还是 1 ,2进制 0000 0001 //1 << 1, 是把1 按2进制 左移1位,结果是2,2进制 0000 0010 ...
- Rsync数据同步工具
Rsync数据同步工具 什么是Rsync? Rsync是一款开源的.快速的.多功能的,可以实现全量及增量的本地或原程数据同步备份 ...
- Jmeter笔记(Ⅱ)使用Jmeter实现轻量级的接口自动化测试
接口测试虽然作为版本的一环,但是也是有一套完整的体系,有接口的功能测试.性能测试.安全测试:同时,由于接口的特性,接口的自动化低成本高收益的,使用一些开源工具或一些轻量级的方法,在测试用例开发的成本不 ...
- WebApi接口访问异常问题。尝试创建“testController”类型的控制器时出错。请确保控制器具有无参数公共构造函数
本来运行的好好的webAPI 接口突然报了个 :“尝试创建“testController”类型的控制器时出错.请确保控制器具有无参数公共构造函数” 错误.耗了半宿最终解决了, 原因: api控制器中引 ...