Java 使用正则表达式和IO实现爬虫以及503解决
我这边找了个小说网站:
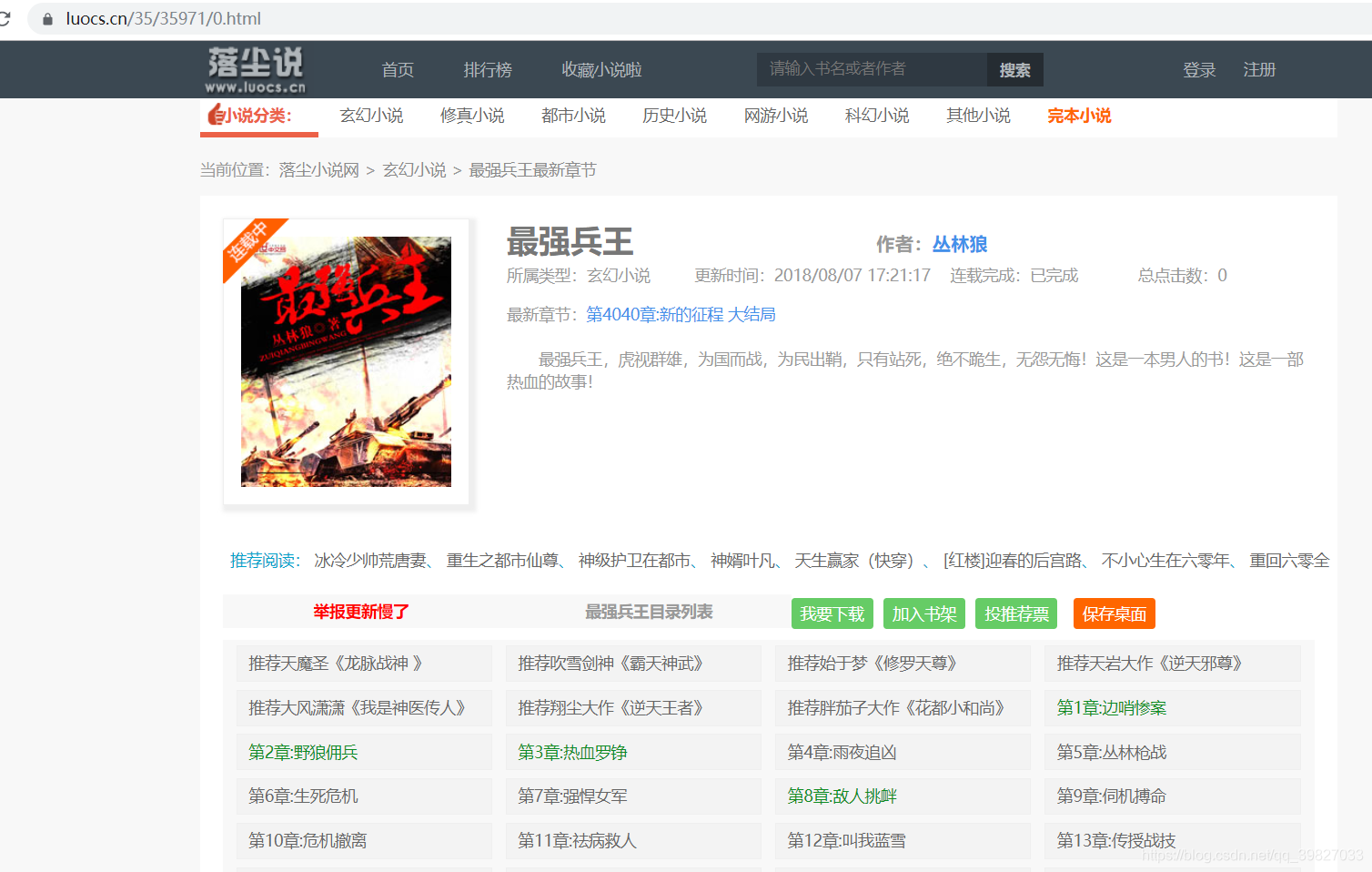
基本套路:
第一步:获取小说每一章的url地址
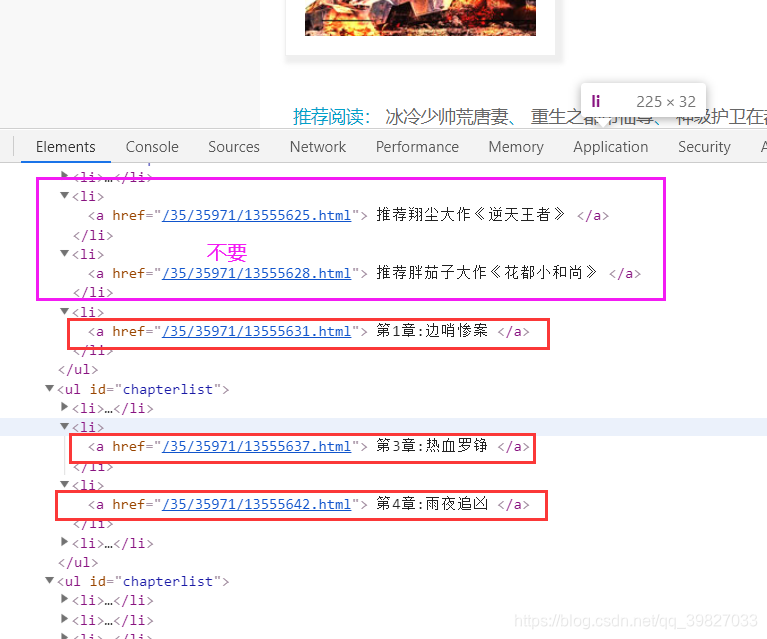
第二步:获取章节url内容并使用正则表达式提取需要的内容

第三步:多线程封装,实现如下效果
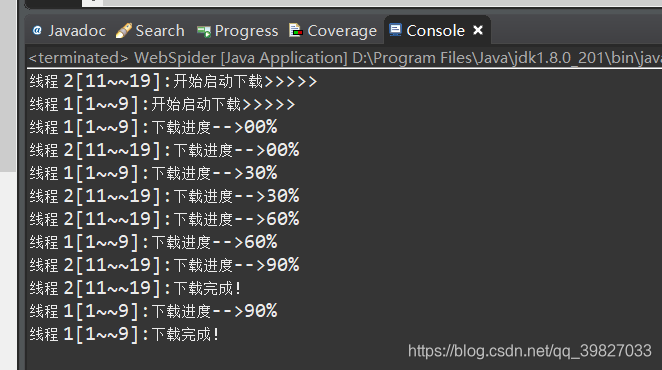
最后测试。
代码:
内容获取封装:
public class WebSpider {
//<a href="/35/35971/13555631.html"> 第1章:边哨惨案 </a> -->{"/35/35971/13555631.html","第1章:边哨惨案"}
// 存放所有章节列表和标题
private List<String[]> urlList;
// 指定下载的跟目录
private String rootDir;
// 指定编码
private String encoding;
public WebSpider() {
urlList = new ArrayList<String[]>();
}
public WebSpider(String titleUrl, Map<String, String> regexMap, String rootDir, String encoding) {
this();
this.rootDir = rootDir;
this.encoding = encoding;
initUrlList(titleUrl, regexMap);
}
/**
* 初始化小说所有章节列表 在构造方法中调用
* @param url
* @param regexMap
*/
private void initUrlList(String url, Map<String, String> regexMap) {
StringBuffer sb = getContent(url, this.encoding);
int urlIndex = Integer.parseInt(regexMap.get("urlIndex"));
int titleIndex = Integer.parseInt(regexMap.get("titleIndex"));
Pattern p = Pattern.compile(regexMap.get("regex"));
Matcher m = p.matcher(sb);
while (m.find()) {
String[] strs = { m.group(urlIndex), m.group(titleIndex) };
this.urlList.add(strs);
}
}
/**
* 获取文本内容
*
* @param urlPath
* @param enc
* @return
*/
public StringBuffer getContent(String urlPath, String enc) {
StringBuffer strBuf;
class Result{
StringBuffer sb;
public Result() {
BufferedReader reader = null;
HttpURLConnection conn = null;
try {
URL url = new URL(urlPath);
conn = (HttpURLConnection) url.openConnection();
conn.setRequestProperty("user-agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36");
reader = new BufferedReader(new InputStreamReader(conn.getInputStream(), enc));
sb = new StringBuffer();
String line;
while ((line = reader.readLine()) != null) {
sb.append(line).append("\r\n");
}
} catch (Exception e) {
// e.printStackTrace();
} finally {
try {
if (reader != null) {
reader.close();
}
conn.disconnect();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
for(int i = 1; ; i++) {
strBuf = new Result().sb;
if(strBuf == null) {
try {
Thread.sleep(5000 * i);
System.out.println("=====================等待 --》" + (5000 * i));
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
break;
}
return strBuf;
}
/**
* 获取正则表达式匹配后内容
* @param url
* @param enc
* @param regex
* @param indexGroup
* @return
*/
public String getDestTxt(String url, String enc, String regex, int indexGroup) {
StringBuffer sb = getContent(url, enc);
StringBuffer result = new StringBuffer();
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(sb);
while (m.find()) {
result.append(m.group(indexGroup).replace("<br />", "\r\n"));
}
return result.toString();
}
public String getRootDir() {
return rootDir;
}
public List<String[]> getUrlList() {
return urlList;
}
}
多线程封装:
class Down implements Runnable {// 线程类
private WebSpider spider;
private String enc;// 编码 这个网站的标题列表编码和正文编码不一样
private String bookName;// 书名
// 分卷下载,指定开始和结束
private int start;
private int end;
private Map<String, String> regexMap;
public Down(WebSpider spider, Map<String, String> regexMap, String enc, String bookName, int start, int end) {
this.spider = spider;
this.regexMap = regexMap;
this.enc = enc;
this.bookName = bookName;
this.start = start;
this.end = end;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "开始启动下载>>>>>");
List<String[]> list = this.spider.getUrlList();
String[] arr = null;
for (int i = start; i < end; i++) {
arr = list.get(i);
String url = "https://www.luocs.cn" + arr[0];
String title = arr[1];
this.writeTOFile(url, this.regexMap.get("regex"), Integer.parseInt(this.regexMap.get("groupIndex")), title);
if (i % 10 % 3 == 0) {
System.out.println(Thread.currentThread().getName() + "下载进度-->" + (i % 10) + "0%");
}
// 暂停1~3秒爬取下一章节
try {
Thread.sleep((long) (1000L + Math.random() * 20000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "下载完成!");
}
/**
* 写入到文件
* @param url 正文url 地址
* @param regex 正文匹配的正则表达式
* @param indexGroup 正文匹配的正则表达式分组
* @param title 每个章节的标题
*/
private void writeTOFile(String url, String regex, int indexGroup, String title) {
String src = this.spider.getDestTxt(url, this.enc, regex, indexGroup);
BufferedWriter writer = null;
try {
writer = new BufferedWriter(new FileWriter(
new File(this.spider.getRootDir() + this.bookName + this.start + "--" + this.end + ".txt"), true));
// 简单美化一下格式
writer.append("*****").append(title).append("*****");
writer.newLine();
writer.append(src, 0, src.length());
writer.newLine();
writer.append("====================");
writer.newLine();
writer.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
测试:
我这边直接写main方法测试:
public static void main(String[] args) {
String url = "https://www.luocs.cn/35/35971/0.html";
Map<String, String> map = new HashMap<String, String>();
map.put("regex", "href='(.+html)'>(.+:{1}.+)</a>");
map.put("urlIndex", "1");
map.put("titleIndex", "2");
WebSpider spider = new WebSpider(url, map, "f:/Game/", "gbk");
Map<String, String> regexMap = new HashMap<String, String>();
regexMap.put("regex", "( ){4}(.+)");
regexMap.put("groupIndex", "2");
for (int i = 0; i < 2; i++) {
Down d = new Down(spider, regexMap, "gb2312", "最强兵王", i * 10, (i + 1) * 10);
new Thread(d, "线程 " + (i + 1) + "[" + (i * 10 + 1) + "~~" + ((i + 1) * 10 - 1) + "]:").start();
}
}
效果:
503失败后,等待一段时间再试
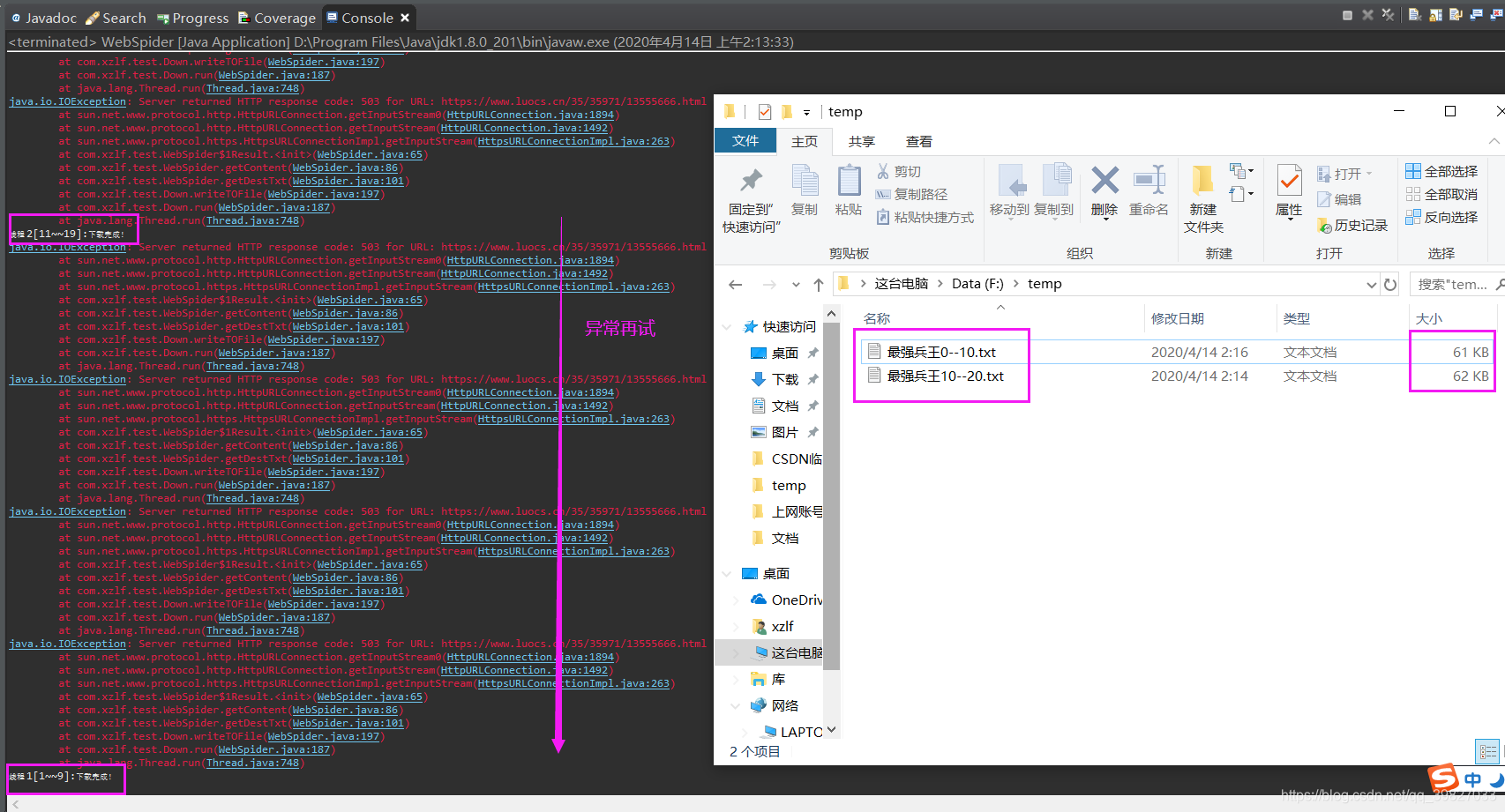
最后写到本地效果

如果把文本导入到手机,用UC或者QQ 浏览器插件打开,会自动区分章节,在配上背景色,那样阅读起来就真的是清爽无弹窗了。
这个网站不怎么好爬,大家可以找个好爬点的网站爬取。当然这个503处理也不是很好,各位路边的大神如果有更好的办法,请指教。
Java 使用正则表达式和IO实现爬虫以及503解决的更多相关文章
- Java面向对象 正则表达式
Java面向对象 正则表达式 知识概要: (1)正则表达式的特点 (2)正则表达的匹配 (3)正则表达式的切割,替换,获取 (4)正则表达式的练习 正则表达式:符合 ...
- Java与正则表达式
Java与正则表达式 标签: Java基础 正则 正如正则的名字所显示的是描述了一个规则, 通过这个规则去匹配字符串. 学习正则就是学习正则表达式的语法规则 正则语法 普通字符 字母, 数字, 汉字, ...
- Java实现一个简单的网络爬虫
Java实现一个简单的网络爬虫 import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileWri ...
- java中正则表达式基本用法
正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它 用以描述在查找文字主体时待匹配的一个或多个字符串.正则表达式作为 ...
- java基础---->java中正则表达式二
跟正则表达式相关的类有:Pattern.Matcher和String.今天我们就开始Java中正则表达式的学习. Pattern和Matcher的理解 一.正则表达式的使用方法 一般推荐使用的方式如下 ...
- Java socket中关闭IO流后,发生什么事?(以关闭输出流为例)
声明:该博文以socket中,关闭输出流为例进行说明. 为了方便讲解,我们把DataOutputstream dout = new DataOutputStream(new BufferedOutpu ...
- Java的正则表达式
package RegexTest; /** * Created by hu on 2016/3/29. */ /* * Java的正则表达式 在正则表达式中,用\d表示一位数字,如果在其它语言中使用 ...
- Java中正则表达式去除html标签
Java中正则表达式去除html的标签,主要目的更精确的显示内容,比如前一段时间在做类似于博客中发布文章功能,当编辑器中输入内容后会将样式标签也传入后台并且保存数据库,但是在显示摘要的时候,比如显示正 ...
- Java 常用正则表达式,Java正则表达式,Java身份证校验,最新手机号码正则表达式
Java 常用正则表达式,Java正则表达式,Java身份证校验,最新手机号码校验正则表达式 ============================== ©Copyright 蕃薯耀 2017年11 ...
随机推荐
- 好记性-烂笔头:JDK8流操作
1):对象 List<User> 转 Map<String,Object> 案例如下: public class User { private Integer id; priv ...
- 在C#MVC三层项目中如何使用SprintNet
0.添加dll文件 1.首先在根目录下新建一个文件夹[Config],然后新建2两个xml文件. 1-1[controllers.xml]用来配置需要创建的对象 1-2[service.xml]用来配 ...
- RuntimeError: PyTorch was compiled without NumPy support
原因:Pytorch和Numpy版本不匹配 查看自己Pytorch和Numpy版本 (1)执行[pip show torch]和[pip show numpy]查看版本信息(可通过[pip -h]查看 ...
- 8.MSFvenom
Meterpreter 01 Meterpreter API调用 Meterpreter提供了多种APl调用,在编写自己的脚本时可以使用这些API来提供额外功能或定制功能. 关于ruby的更多信息,请 ...
- SQL Server中STATISTICS IO物理读和逻辑读的误区
SQL Server中STATISTICS IO物理读和逻辑读的误区 大家知道,SQL Server中可以利用下面命令查看某个语句读写IO的情况 SET STATISTICS IO ON 那么这个命令 ...
- 使用IDEA编写JDBC
省去下载MySQL的过程,创建数据库demo 首先在下载的Java服务中将此jar包复制到项目中的一个空文件夹中 在当前工程下新建目录lib(名字可自定) 找到MySQL的Java服务的jar包 打开 ...
- Tomcat目录解析
bin 可执行文件的储存 conf 配置文件 lib 依赖jar包 logs 日志文件 temp 临时文件 webapps 创建的web应用程序 work 存放运行时数据 如何启动Tomcat? 启动 ...
- String 对象-->substr() 方法
1.定义和用法 substr() 方法可在字符串中抽取从 开始 下标开始的指定数目的字符. 语法: string.substr(start,length) 参数: start:提取开始下标 lengt ...
- C语言实现链表(链式存储结构)
链表(链式存储结构)及创建 链表,别名链式存储结构或单链表,用于存储逻辑关系为 "一对一" 的数据.与顺序表不同,链表不限制数据的物理存储状态,换句话说,使用链表存储的数据元素,其 ...
- "视频播放器"组件:<video-player> —— 快应用组件库H-UI
 <import name="video-player" src="../Common/ui/h-ui/media/c_video_player"> ...