[hdu5323]复杂度计算,dfs
题意:求最小的线段树的右端点(根节点表示区间[0,n]),使得给定的区间[L,R]是线段树的某个节点。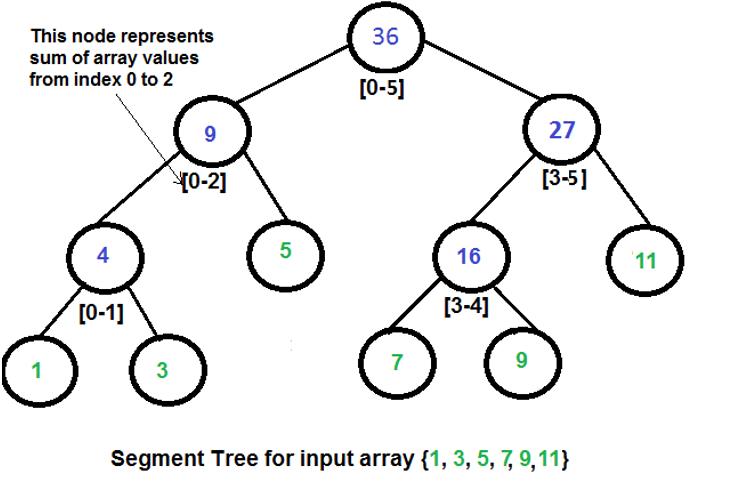
数据范围:L,R<=1e9,L/(R-L+1)<=2015
思路:首先从答案出发来判断是否出现给定区间是行不通的,于是只能从[L,R]出发来寻找答案。如果一个子节点表示区间[L,R],那么它的父节点可能是四种表示方式之一,分别是[L,2R-L],[L,2R-L+1],[2L-R-1,R],[2L-R-2,R],其中父节点为[L,2R-L]时要求R>L,否则它的右儿子就为空了,这是不允许的。接下来看无解的条件,如果L<(R-L+1)了,那么就是无解的,因为左儿子不可能比右儿子表示的区间长度小,也就是说L/(R-L+1)小于1时就可以判定为无解了。注意到由儿子节点到父亲节点,(R-L+1)变为了原来的两倍左右,而L是非增的,所以L/(R-L+1)每经过一层,值变为原来的1/2左右,有题目给定的数据,L/(R-L+1)<=2015,所以层数最多只有log22015=11,这不难想到dfs暴力扩展了,dfs总共只会扩展出4^11=4000000个节点,可以承受。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
/* ******************************************************************************** */#include <iostream> //#include <cstdio> //#include <cmath> //#include <cstdlib> //#include <cstring> //#include <vector> //#include <ctime> //#include <deque> //#include <queue> //#include <algorithm> //using namespace std; // //#define pb push_back //#define mp make_pair //#define X first //#define Y second //#define all(a) (a).begin(), (a).end() //#define foreach(i, a) for (typeof(a.begin()) it = a.begin(); it != a.end(); it ++) // //void RI(vector<int>&a,int n){a.resize(n);for(int i=0;i<n;i++)scanf("%d",&a[i]);} //void RI(){}void RI(int&X){scanf("%d",&X);}template<typename...R> //void RI(int&f,R&...r){RI(f);RI(r...);}void RI(int*p,int*q){int d=p<q?1:-1; //while(p!=q){scanf("%d",p);p+=d;}}void print(){cout<<endl;}template<typename T> //void print(const T t){cout<<t<<endl;}template<typename F,typename...R> //void print(const F f,const R...r){cout<<f<<", ";print(r...);}template<typename T> //void print(T*p, T*q){int d=p<q?1:-1;while(p!=q){cout<<*p<<", ";p+=d;}cout<<endl;} // //typedef pair<int, int> pii; //typedef long long ll; //typedef unsigned long long ull; // ///* -------------------------------------------------------------------------------- */ //template<typename T>bool umax(T &a, const T &b) { return a >= b? false : (a = b, true);}ll ans, L, R;void dfs(ll L, ll R) { if (L == 0) { if (ans == -1 || ans > R) ans = R; return ; } ll s = L, t = R - L + 1; if (s < t) return ; if (L < R) dfs(L, 2 * R - L); dfs(L, 2 * R - L + 1); dfs(2 * L - R - 1, R); dfs(2 * L - R - 2, R);}int main() {#ifndef ONLINE_JUDGE freopen("in.txt", "r", stdin);#endif // ONLINE_JUDGE while (cin >> L >> R) { ans = -1; dfs(L, R); cout << ans << endl; } return 0; //} // // // ///* ******************************************************************************** */ |
[hdu5323]复杂度计算,dfs的更多相关文章
- python 文本相似度计算
参考:python文本相似度计算 原始语料格式:一个文件,一篇文章. #!/usr/bin/env python # -*- coding: UTF-8 -*- import jieba from g ...
- 2019牛客多校第二场F Partition problem 暴力+复杂度计算+优化
Partition problem 暴力+复杂度计算+优化 题意 2n个人分成两组.给出一个矩阵,如果ab两个在同一个阵营,那么就可以得到值\(v_{ab}\)求如何分可以取得最大值 (n<14 ...
- 海量数据相似度计算之simhash短文本查找
在前一篇文章 <海量数据相似度计算之simhash和海明距离> 介绍了simhash的原理,大家应该感觉到了算法的魅力.但是随着业务的增长 simhash的数据也会暴增,如果一天100w, ...
- 海量数据相似度计算之simhash和海明距离
通过 采集系统 我们采集了大量文本数据,但是文本中有很多重复数据影响我们对于结果的分析.分析前我们需要对这些数据去除重复,如何选择和设计文本的去重算法?常见的有余弦夹角算法.欧式距离.Jaccard相 ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 图像相似度计算之哈希值方法OpenCV实现
http://blog.csdn.net/fengbingchun/article/details/42153261 图像相似度计算之哈希值方法OpenCV实现 2014-12-25 21:27 29 ...
- LSF-SCNN:一种基于 CNN 的短文本表达模型及相似度计算的全新优化模型
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 本篇文章是我在读期间,对自然语言处理中的文本相似度问题研究取得的一点小成果.如果你对自然语言处理 (natural language proc ...
- Go 实现字符串相似度计算函数 Levenshtein 和 SimilarText
[转]http://www.syyong.com/Go/Go-implements-the-string-similarity-calculation-function-Levenshtein-and ...
- 皮尔森相似度计算举例(R语言)
整理了一下最近对协同过滤推荐算法中的皮尔森相似度计算,顺带学习了下R语言的简单使用,也复习了概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 因为这里每个数都是等 ...
随机推荐
- selenium Webdriver多窗口切换
应用场景: 在页面操作过程中有时候点击某个链接会弹出新的窗口,这时候就需要主机切换到新打开的窗口上进行操作.WebDriver提供了switch_to.window()方法,可以实现在不同的窗口直接切 ...
- [JS] 自己弄得个倒计时
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- pytorch中CUDA类型的转换
import torch import numpy as np device = torch.device("cuda:0" if torch.cuda.is_available( ...
- 深入分析Redis的主从复制机制
一.前言 最近由于疫情影响,时间比较多,所以开始学习之前一直想学,但是却没时间学的Redis.这两天研究了一下Redis的持久化以及主从复制机制,现在已经很晚了,就不多废话了.这篇博客就来谈一谈R ...
- solr管理集合
其实完全版的管理,在web页面上就有. 同时,在官网文档上,也有:https://lucene.apache.org/solr/guide/6_6/coreadmin-api.html#CoreAdm ...
- thinkphp5.0 url跳转
<a href="{:url('member/index/index',['id'=>5])}">跳转</a> define()自定义常量在thiin ...
- c++中set 的用法
1.关于set C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像vector, string, list等方便的容器,更重要的是STL封装了许多复杂的数据结构算法和大量常用数据结构 ...
- 在java 8 stream表达式中实现if/else逻辑
目录 简介 传统写法 使用filter 总结 简介 在Stream处理中,我们通常会遇到if/else的判断情况,对于这样的问题我们怎么处理呢? 还记得我们在上一篇文章lambda最佳实践中提到,la ...
- 老男孩Linux运维50期 --于海科--决心书
1.我叫于海科,来自于甘肃省天水市,之前就读于兰州石化职业技术学院,我是听之前的学长说老男孩教育出来就业不错,我特此来这培训希望出来能够找到一份不错的工作.2.五个月学完,目标薪资是11k.3.达到目 ...
- 图论--差分约束--HDU\HDOJ 4109 Instrction Arrangement
Problem Description Ali has taken the Computer Organization and Architecture course this term. He le ...