【Python学习笔记四】获取html内容之后,如何提取信息:使用正则表达式筛选
在能够获取到网页内容之后,发现内容很多,那么下一步要做信息的筛选,就和之前的筛选图片那样
而在python中可以通过正则表达式去筛选自己想要的数据
1.首先分析页面内容信息,确定正则表达式。例如想获取下面这些内容的链接

可以通过筛选出符合<li><a href="xxx"的内容,获取到href中的链接,设置正则:reg = r'<li><a href="(.+?)"'去筛选数据就OK了;
2.在python中用正则表达式去筛选数据,在python中有两种方法实现:
第一种:
reg = r'<li><a href="(.+?)"'
hrefreg = re.compile(reg)
hreflist = hrefreg.findall(html)
第二种:
reg = r'<li><a href="(.+?)"'
hreflist = re.findall(reg, html)
这两种方法都能实现数据的筛选,他们的区别主要是:是否使用re.compile()。这个实际影响到的是大数据量级时的性能,目前仅作了解。
另外,关于正则学习的内容可以参考这里:https://www.runoob.com/regexp/regexp-tutorial.html
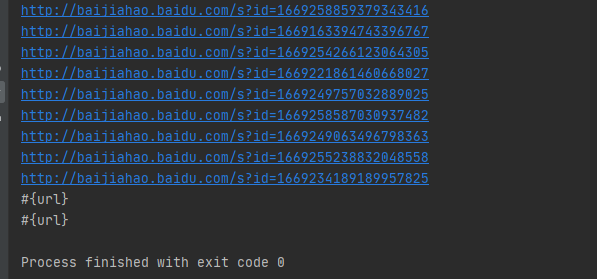
最后是简单的筛选href内容的代码和结果,结果里看出有些href内容并不是http链接,这个时候可以做二次处理。例如,判断是否包含"http"字符串等:
import re
import urllib.request # 设置headers和URL
url = "https://news.baidu.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url=url, headers=headers) # 请求指定URL,获取内容
html = urllib.request.urlopen(req).read().decode('UTF-8', 'ignore') #筛选出href内容并打印
reg = r'<li><a href="(.+?)"'
hreflist = re.findall(reg, html)
for href in hreflist:
print(href)
【Python学习笔记四】获取html内容之后,如何提取信息:使用正则表达式筛选的更多相关文章
- 大学四年的Python学习笔记分享之一,内容整理的比较多与仔细
翻到以前在大学坚持记录的Python学习笔记,花了一天的时间整理出来,整理时不经回忆起大学的时光,一眨眼几年就过去了,现在还在上学的你们,一定要珍惜现在,有个充实的校园生活.希望这次的分享对于你们有学 ...
- Python学习笔记四:面向对象编程
一:定义类并创建实例 Python中定义类,通过class关键字,类名开头大写,参数列表为所继承的父类.如果没有需要明确继承的类,则继承object. 使用类来创建对象,只需 类名+() 形式即可,p ...
- Python学习笔记(四)Python函数的参数
Python的函数除了正常使用的必选参数外,还可以使用默认参数.可变参数和关键字参数. 默认参数 基本使用 默认参数就是可以给特定的参数设置一个默认值,调用函数时,有默认值得参数可以不进行赋值,如: ...
- python学习笔记(四) 思考和准备
一.zip的坑 zip()函数接收多个可迭代数列,将数列中的元素重新组合,在3.0中返回迭代器指向 数列首地址,在3.0以下版本返回List类型的列表数列.我用的是3.5版本python, 所以zip ...
- python学习笔记四 迭代器,生成器,装饰器(基础篇)
迭代器 __iter__方法返回一个迭代器,它是具有__next__方法的对象.在调用__next__方法时,迭代器会返回它的下一个值,若__next__方法调用迭代器 没有值返回,就会引发一个Sto ...
- Python学习笔记四--字典与集合
字典是Python中唯一的映射类型.所谓映射即指该数据类型包含哈希值(key)和与之对应的值(value)的序列.字典是可变类型.字典中的数据是无序排列的. 4.1.1字典的创建及赋值 dict1={ ...
- Python学习笔记四
一.装饰器 1.知识储备 函数对象 函数可以被引用 函数可以当参数传递 返回值可以是函数 可以当作容器的元素 def func1(): print (666) def func2(): print ( ...
- python学习笔记(四)、条件、循环及其他语句
1 再谈print和import 1.1 打印多个参数 print 能够同时打印多个表达式,并且能自定义分隔符.如下: print('a','b','c') ——> a b c print('a ...
- Python学习笔记_获取当前目录和上级目录
实验目标:获取当前目录和上级目录 系统环境: 1.OS:Win10 64位 2.Pythoh 3.7 3.实验路径:C:\Work\Python\MergeExcel 代码参考: # -*- codi ...
随机推荐
- WeChair项目Alpha冲刺(1/10)
团队项目进行情况 1.昨日进展 因为是Alpha冲刺第一天,所以昨日进展无 2.今日安排 前端:完成前端页面的首页html+css部分 后端:搭建好SpringBoot项目以及完成实体类代码的编 ...
- JavaWeb网上图书商城完整项目--12.项目所需jquery函数介绍之ajax
jquery中使用ajax发送异步请求 下面的一个案例在input输入框失去焦点的时候发送一个异步的请求: 我们来看程序的案例: 这里要强调的是返回值最好选择是json,json对应的就是对象,Jav ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 关于for循环和Iterator遍历ArrayList的性能问题
今日看到@DriveMan的一篇博客,题为<ArrayList集合实现RandomAccess接口有何作用?为何LinkedList集合却没实现这接口?>,文中提到对于实现了RandomA ...
- html实体引用
原义字符 等价字符引用 < < > > " " ' ' & &
- Flutter —快速开发的IDE快捷方式
老孟导读:这是老孟翻译的精品文章,文章所有权归原作者所有. 欢迎加入老孟Flutter交流群,每周翻译2-3篇付费文章,精彩不容错过. 原文地址:https://medium.com/flutter- ...
- SpringBoot2.x入门:引入web模块
前提 这篇文章是<SpringBoot2.x入门>专辑的第3篇文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8. 主要介绍SpringBoot的web模 ...
- C++中string转换为char*类型返回后乱码问题
问题来源: 在写二叉树序列化与反序列化时发现序列化函数为char* Serialize1(TreeNode *root) 其函数返回类型为char*,但是我在实现的过程中为了更方便的操作添加字符串使 ...
- cmake的下载和安装
背景: 最近迷上了 vscode 编辑器, 快速便捷,而且插件丰富,使用起来很爽.既然这样,本身游戏也是用 mingw 加 cygwin 开发的, 可以配置一下,开搞. 实操: 1.登陆cmake官网 ...
- 攻防世界-新手篇(Mise)~~~
Mise this_is_flag 签到题flag{th1s_!s_a_d4m0_4la9} pdf 打开图片,flag值在图片底下,wps将pdf转为word格式后,将图片拉开发现flag flag ...