机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数
RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,
n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。
这一节主要讲解RandomForestClassifier,随机森林分类器。
1 重要参数
1.1 控制基评估器的参数

这些参数在随机森林中的含义,和我们在上决策树时说明的内容一模一样,单个决策树的准确率越高,随机森林的准确率也会越高,因为装袋法是依赖于平均值或者少数服从多数原则来决定集成的结果的。
1.2 n_estimators
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。
但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
n_estimators的默认值在现有版本的sklearn中是10,但是在即将更新的0.22版本中,这个默认值会被修正为100。这个修正显示出了使用者的调参倾向:要更大的n_estimators。
来建立一片森林吧
树模型的优点是简单易懂,可视化之后的树人人都能够看懂,可惜随机森林是无法被可视化的。
所以为了更加直观地让大家体会随机森林的效果,我们来进行一个随机森林和单个决策树效益的对比。我们依然使用红酒数据集。
1. 导入我们需要的包
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
2. 导入需要的数据集
wine = load_wine() wine.data
wine.target
3. 复习:sklearn建模的基本流程
from sklearn.model_selection import train_test_split Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest) print("Single Tree:{}".format(score_c)
,"Random Forest:{}".format(score_r)
)
4. 画出随机森林和决策树在一组交叉验证下的效果对比
#目的是带大家复习一下交叉验证
#交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法 from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10) clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10) plt.plot(range(1,11),rfc_s,label = "RandomForest")
plt.plot(range(1,11),clf_s,label = "Decision Tree")
plt.legend()
plt.show() #====================一种更加有趣也更简单的写法===================# """
label = "RandomForest"
for model in [RandomForestClassifier(n_estimators=25),DecisionTreeClassifier()]:
score = cross_val_score(model,wine.data,wine.target,cv=10)
print("{}:".format(label)),print(score.mean())
plt.plot(range(1,11),score,label = label)
plt.legend()
label = "DecisionTree" """
5. 画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = [] for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label = "Random Forest")
plt.plot(range(1,11),clf_l,label = "Decision Tree")
plt.legend()
plt.show() #是否有注意到,单个决策树的波动轨迹和随机森林一致?
#再次验证了我们之前提到的,单个决策树的准确率越高,随机森林的准确率也会越高
6. n_estimators的学习曲线
#####【TIME WARNING: 2mins 30 seconds】##### superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()
1.3 random_state
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决原则来决定集成评估器的结果。
在刚才的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。
单独一棵决策树对红酒数据集的分类准确率在0.85上下浮动,假设一棵树判断错误的可能性为0.2(ε),那20棵树以上都判断错误的可能性是:
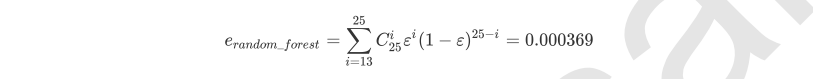
其中,i是判断错误的次数,也是判错的树的数量,ε是一棵树判断错误的概率,(1-ε)是判断正确的概率,共判对25-i次。采用组合,是因为25棵树中,有任意i棵都判断错误。
import numpy as np
from scipy.special import comb np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()
可见,判断错误的几率非常小,这让随机森林在红酒数据集上的表现远远好于单棵决策树。
那现在就有一个问题了:我们说袋装法服从多数表决原则或对基分类器结果求平均,这即是说,我们默认森林中的每棵树应该是不同的,并且会返回不同的结果。
设想一下,如果随机森林里所有的树的判断结果都一致(全判断对或全判断错),那随机森林无论应用何种集成原则来求结果,都应该无法比单棵决策树取得更好的效果才对。
但我们使用了一样的类DecisionTreeClassifier,一样的参数,一样的训练集和测试集,为什么随机森林里的众多树会有不同的判断结果?
问到这个问题,很多小伙伴可能就会想到了:sklearn中的分类树DecisionTreeClassifier自带随机性,所以随机森林中的树天生就都是不一样的。我们在讲解分类树时曾提到,决策树从最重要的特征中随机选择出一个特征来进行分枝,因此每次生成的决策树都不一样,这个功能由参数random_state控制。
随机森林中其实也有random_state,用法和分类树中相似,只不过在分类树中,一个random_state只控制生成一棵树,而随机森林中的random_state控制的是生成森林的模式,而非让一个森林中只有一棵树。
rfc = RandomForestClassifier(n_estimators=20,random_state=2)
rfc = rfc.fit(Xtrain, Ytrain) #随机森林的重要属性之一:estimators,查看森林中树的状况
rfc.estimators_[0].random_state for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)
我们可以观察到,当random_state固定时,随机森林中生成是一组固定的树,但每棵树依然是不一致的,这是用”随机挑选特征进行分枝“的方法得到的随机性。并且我们可以证明,当这种随机性越大的时候,袋装法的效果一般会越来越好。用袋装法集成时,基分类器应当是相互独立的,是不相同的。
但这种做法的局限性是很强的,当我们需要成千上万棵树的时候,数据不一定能够提供成千上万的特征来让我们构筑尽量多尽量不同的树。因此,除了random_state。我们还需要其他的随机性。
1.4 bootstrap & oob_score
要让基分类器尽量都不一样,一种很容易理解的方法是使用不同的训练集来进行训练,而袋装法正是通过有放回的随机抽样技术来形成不同的训练数据,bootstrap就是用来控制抽样技术的参数。
在一个含有n个样本的原始训练集中,我们进行随机采样,每次采样一个样本,并在抽取下一个样本之前将该样本放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集n次,最终得到一个和原始训练集一样大的,n个样本组成的自助集。由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的基分类器,我们的基分类器自然也就各不相同了。
bootstrap参数默认True,代表采用这种有放回的随机抽样技术。通常,这个参数不会被我们设置为False。
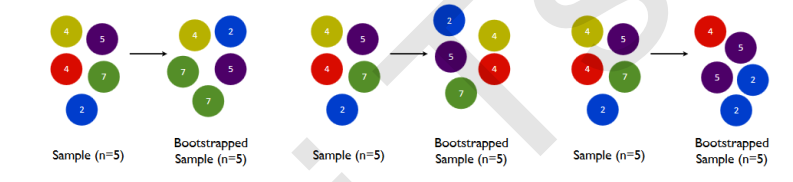
然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能
被忽略,一般来说,自助集大约平均会包含63%的原始数据。因为每一个样本被抽到某个自助集中的概率为:
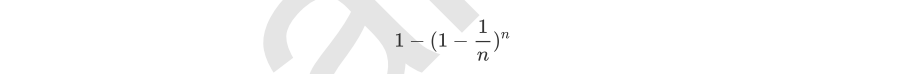
当n足够大时,这个概率收敛于1-(1/e),约等于0.632。因此,会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。除了我们最开始就划分好的测试集之外,这些数据也可以被用来作为集成算法的测试集。
也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据来测试我们的模型即可。
当然,这也不是绝对的,当n和n_estimators都不够大的时候,很可能就没有数据掉落在袋外,自然也就无法使用oob数据来测试模型了。
如果希望用袋外数据来测试,则需要在实例化时就将oob_score这个参数调整为True,训练完毕之后,我们可以用
随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果:
#无需划分训练集和测试集 rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
rfc = rfc.fit(wine.data,wine.target) #重要属性oob_score_
rfc.oob_score_
机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数的更多相关文章
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 机器学习实战基础(十六):sklearn中的数据预处理和特征工程(九)特征选择 之 Filter过滤法(三) 总结
过滤法总结 到这里我们学习了常用的基于过滤法的特征选择,包括方差过滤,基于卡方,F检验和互信息的相关性过滤,讲解了各个过滤的原理和面临的问题,以及怎样调这些过滤类的超参数.通常来说,我会建议,先使用方 ...
- Android项目实战(三十五):多渠道打包
多渠道打包: 可以理解为:同时发布多个渠道的apk.分别上架不同的应用商店.这些apk带有各自渠道的标签,用于统计分析各个商店的下载次数等数据. 实现步骤 一.添加友盟渠道标签 添加位置:app目录下 ...
- 机器学习实战基础(十九):sklearn中数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在 ...
- leecode第二百三十五题(二叉搜索树的最近公共祖先)
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
随机推荐
- pip 安装使用国内镜像
pip国内的一些镜像 阿里云 https://mirrors.aliyun.com/pypi/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple ...
- Spring源码系列(一)--详解介绍bean组件
简介 spring-bean 组件是 IoC 的核心,我们可以通过BeanFactory来获取所需的对象,对象的实例化.属性装配和初始化都可以交给 spring 来管理. 针对 spring-bean ...
- 面试必问:分布式锁实现之zk(Zookeeper)
点赞再看,养成习惯,微信搜索[三太子敖丙]关注这个互联网苟且偷生的工具人. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的 ...
- matplotlib作图一例
知识点都在这个例子里面: plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt ...
- 西门子S7-300 PLC视频教程(百度网盘)收集于网络-供参考学习
百度网盘地址: 西门子300 PLC视频教程 群文件里面可以找到. 下载: https://blog.csdn.net/txwtech/article/details/93016190
- SpringCloud之初识Feign
在前面的学习中,我们使用了Ribbon的负载均衡功能,大大简化了远程调用时的代码: String baseUrl = "http://user-service/user/"; Us ...
- 07.Easymock的实际应用
第一步下载对应的java包添加到工程中 并静态导入所需要的j类 import static org.easymock.EasyMock.*; 这里有的注意点 package com.fjnu.serv ...
- redis基础二----操作List类型
1.lpush的使用方法 2.rpsuh的使用方法 3.删除元素 lrem中2值的是删除2个集合中的“b”元素 4. 通过上面的分析,redis中的list比较类型java的qunue队列
- 如何下载 Ubuntu 镜像文件?
Ubuntu,是一款基于 Debian Linux 的以桌面应用为主的操作系统,内容涵盖文字处理.电子邮件.软件开发工具和 Web 服务等,可供用户免费下载.使用和分享. 但是对于国内的用户来说如果直 ...
- 当我们创建HashMap时,底层到底做了什么?
jdk1.7中的底层实现过程(底层基于数组+链表) 在我们new HashMap()时,底层创建了默认长度为16的一维数组Entry[ ] table.当我们调用map.put(key1,value1 ...