5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01、02、03、04、05、06、07的分布式集群的HA测试
1) weekend01、02的hdfs的HA测试
2) weekend03、04的yarn的HA测试
1) weekend01、02的hdfs的HA测试

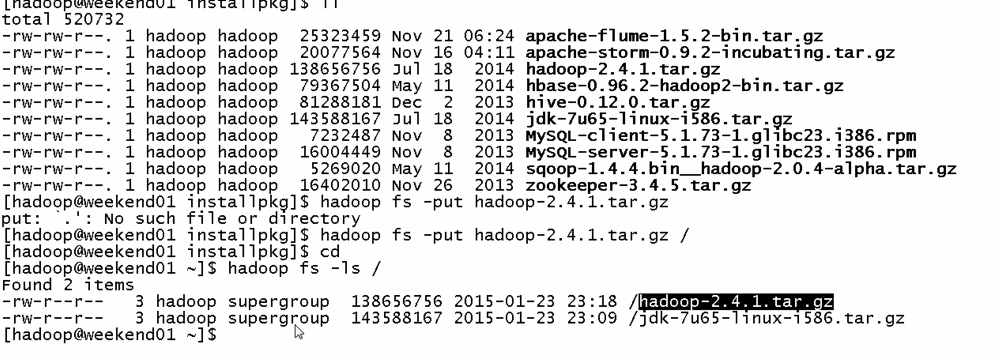
首先,分布式集群都是正常的,且工作的


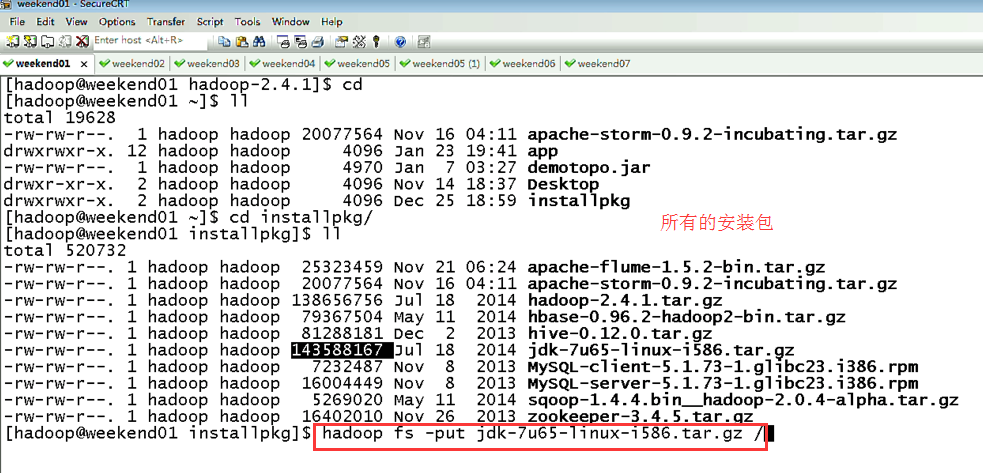

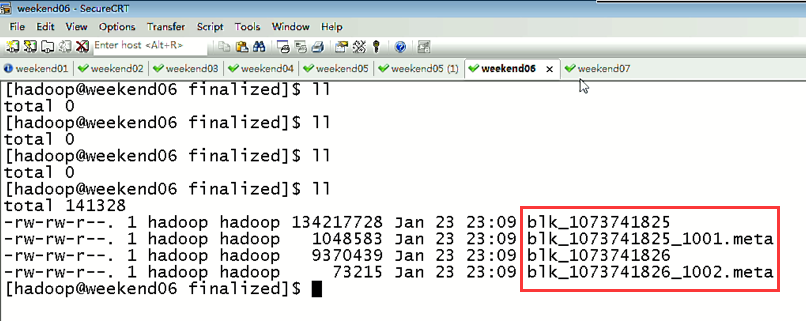
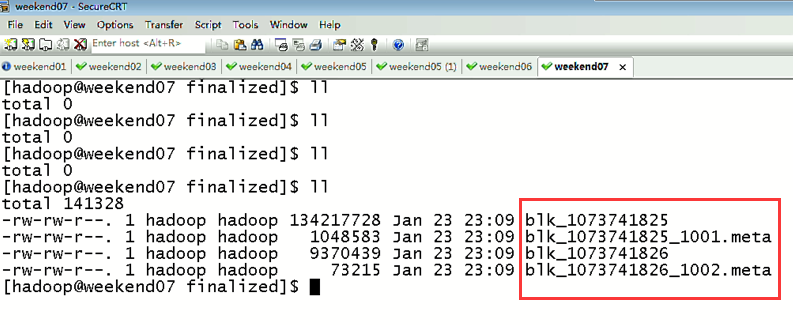
然后呢,
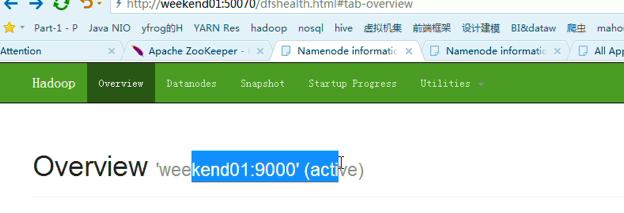


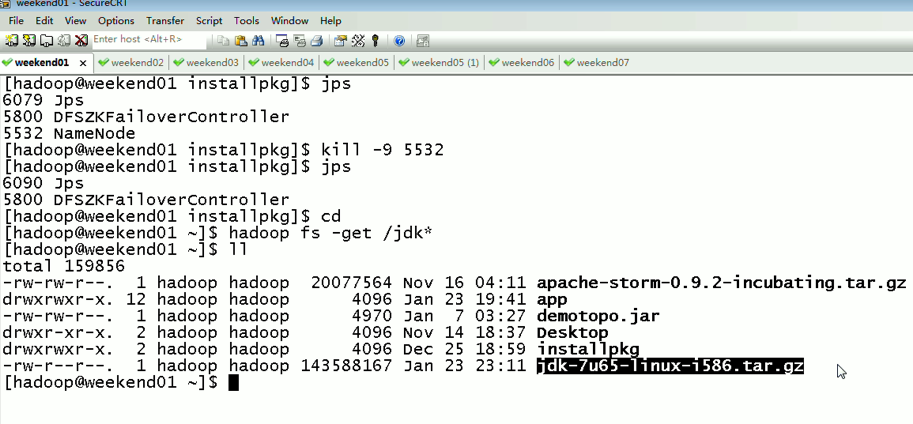
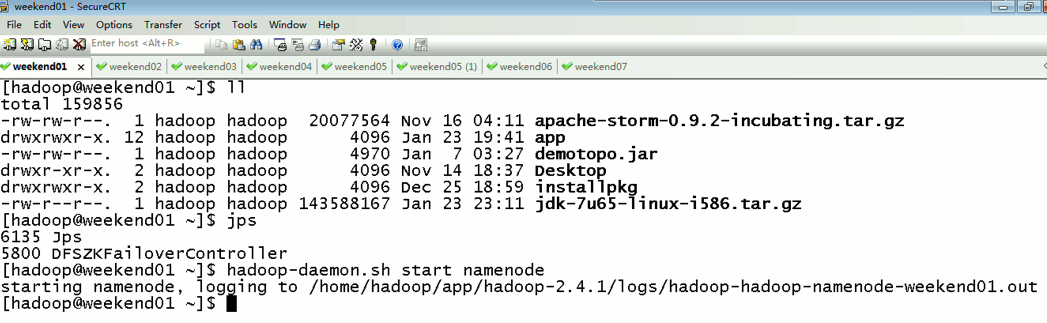
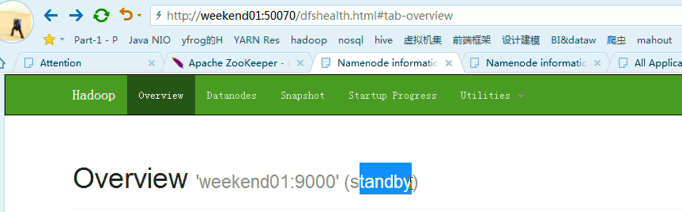
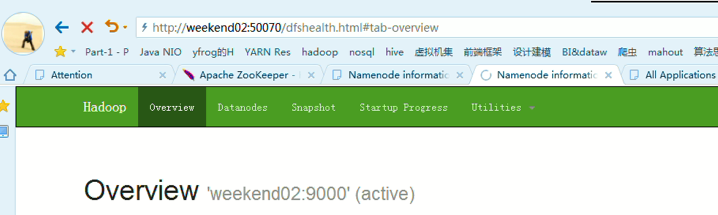
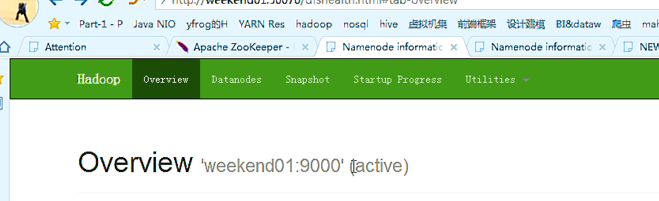
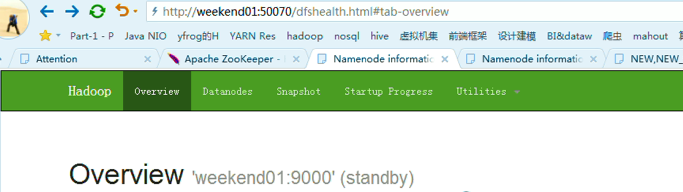
以上是,weekend01(active)、weekend02(standby)
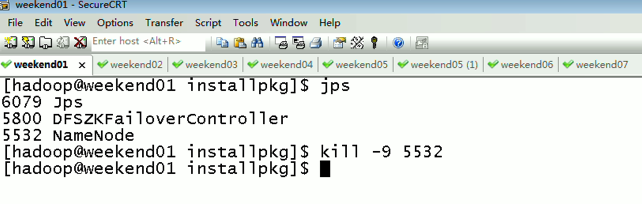
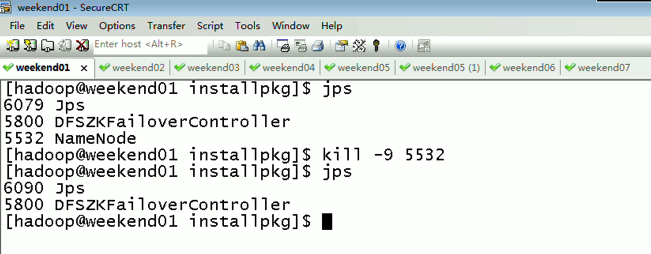
当weekend01给kill,
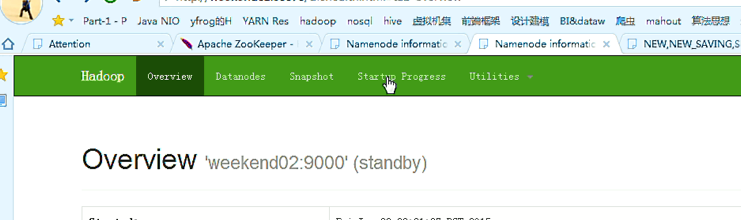
变成weekend01(standby)、weekend02(active)
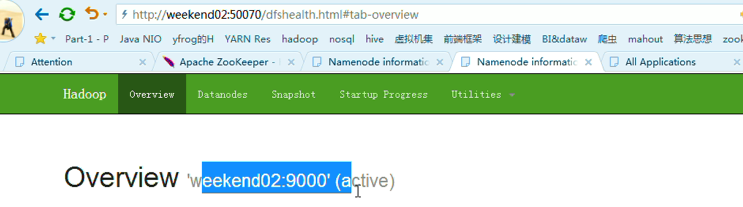
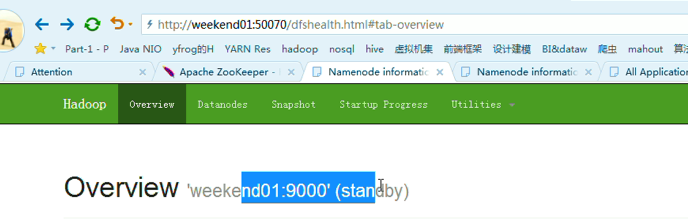

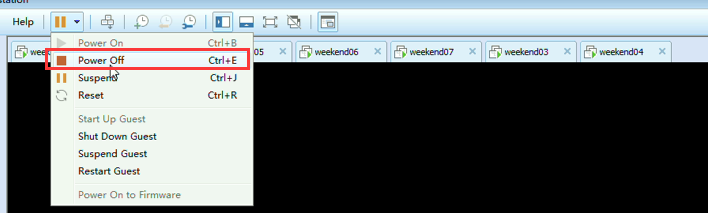
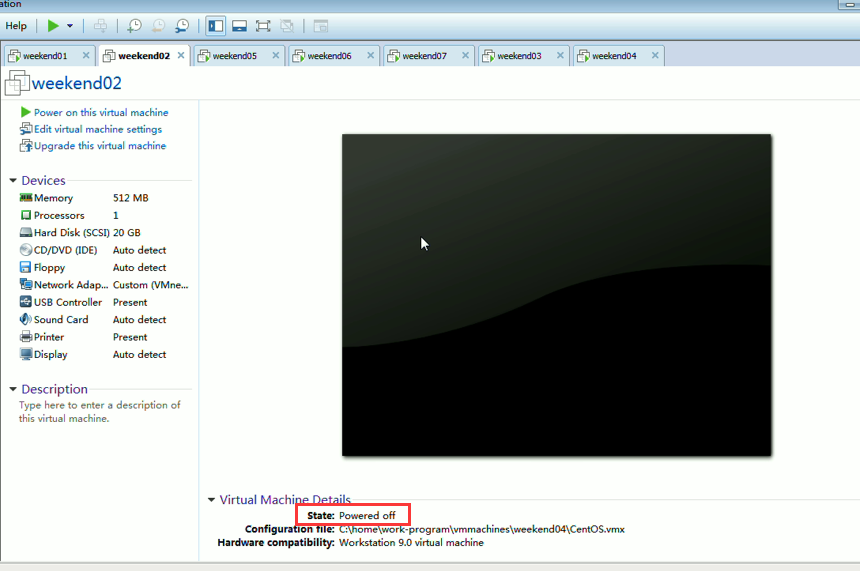
模拟weekend02断电


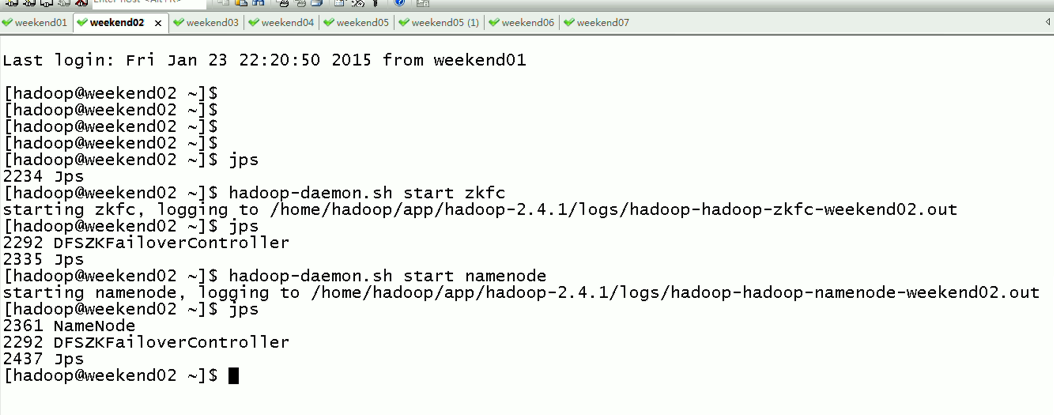
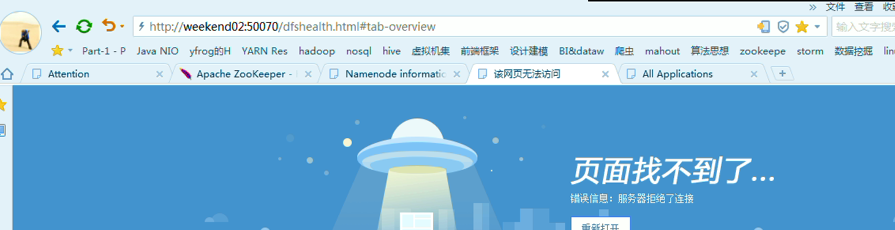
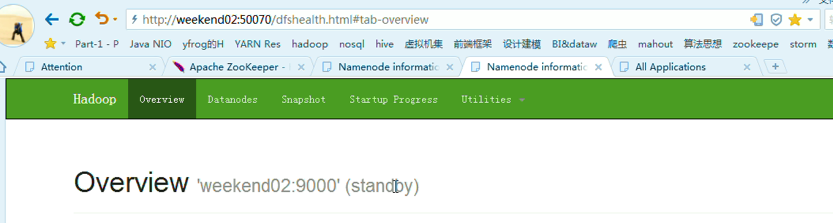
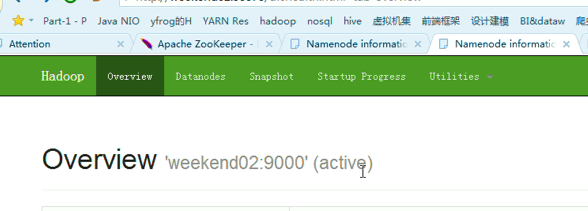
以上是weekend01(standby)、weekend02(active)
当weekend02断电后,再启动
weekend01(active)、weekend02(standby)
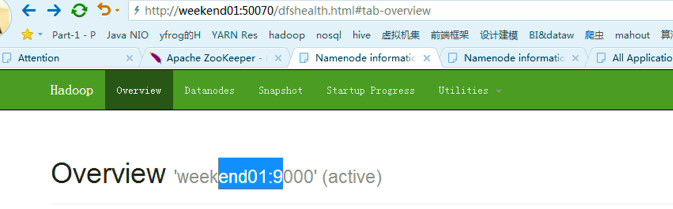


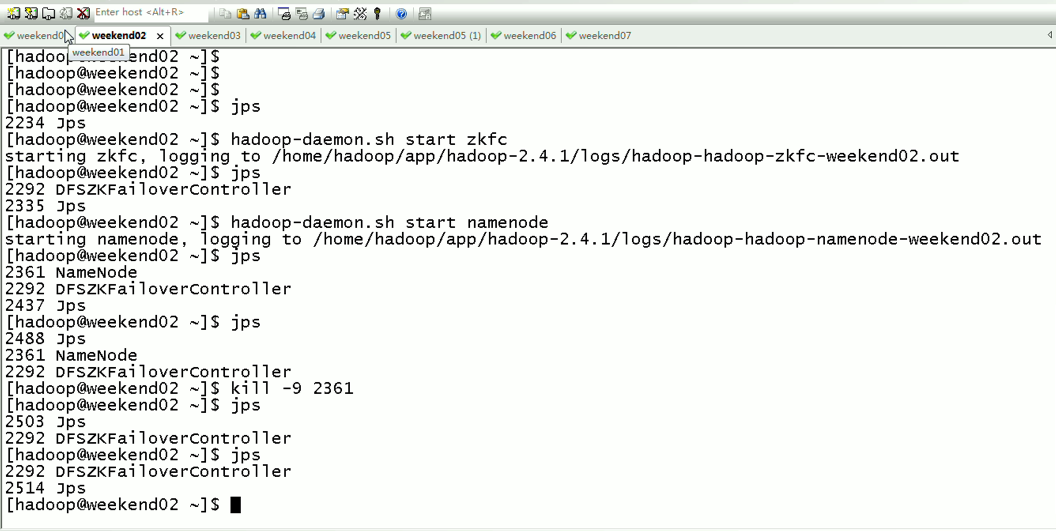
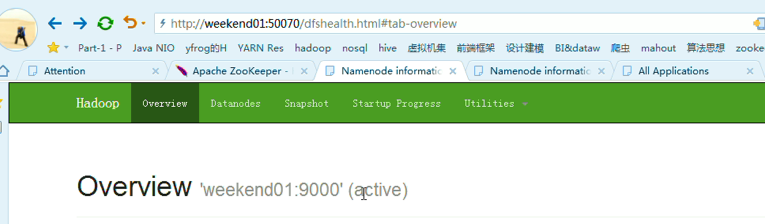
以上是weekend01(active)、weekend02(standby)
当weekend01在传文件时,weekend02杀掉namenode进程,
依然还是weekend01(active)、weekend02(standby)
以上是weekend01、02的hdfs的HA测试
下面,
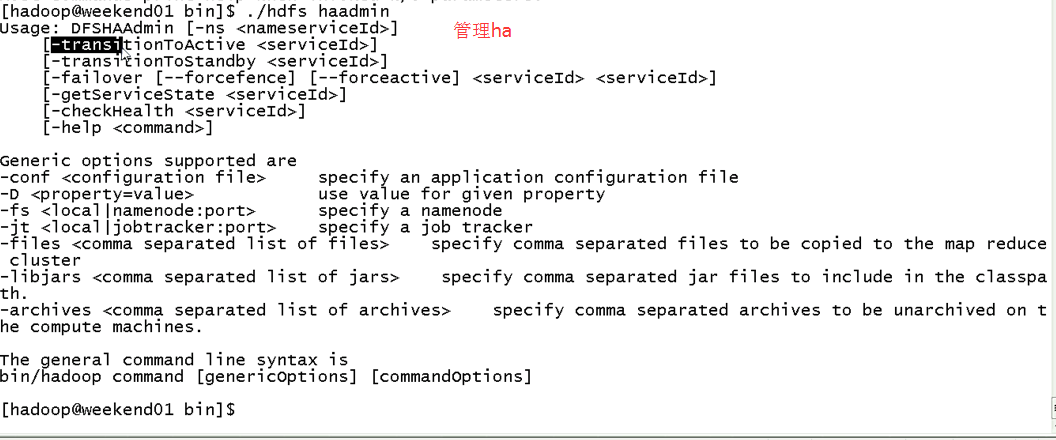

现在,用指令来切换
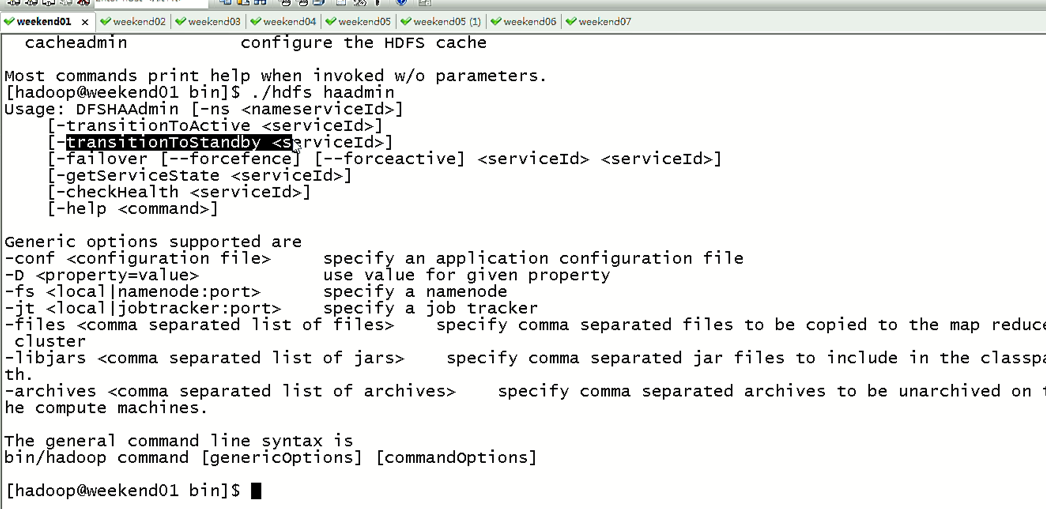
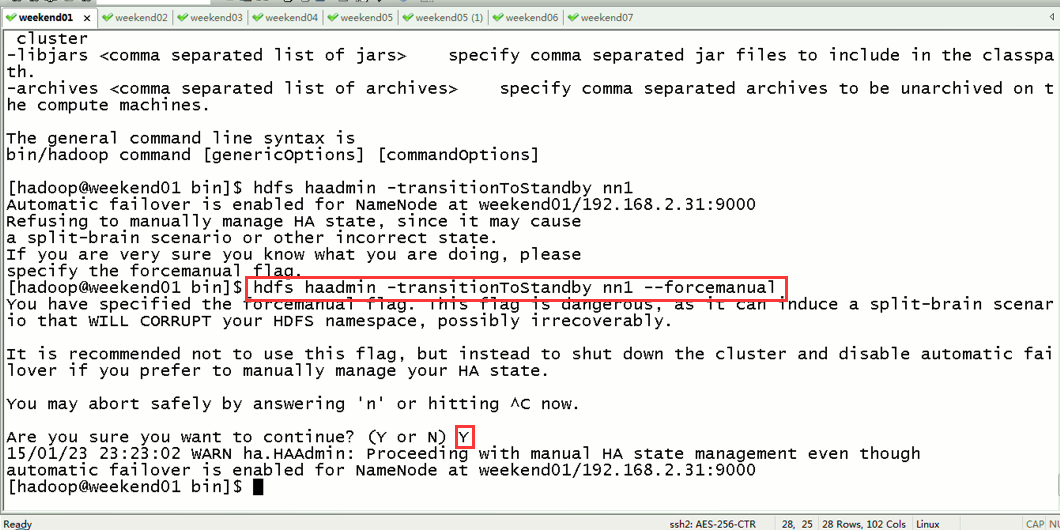
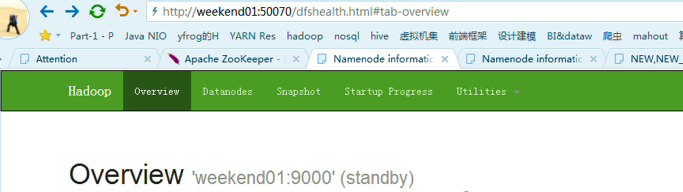
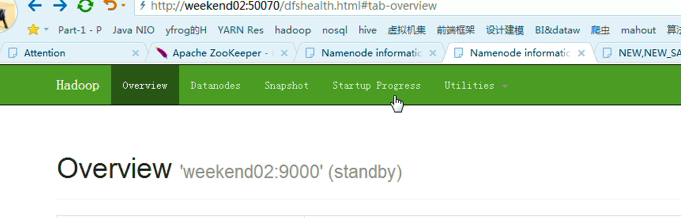
这样,是告诉我们,有时候会碰到,如weekend01、02都是standby时,来命令将其中一个切换成active
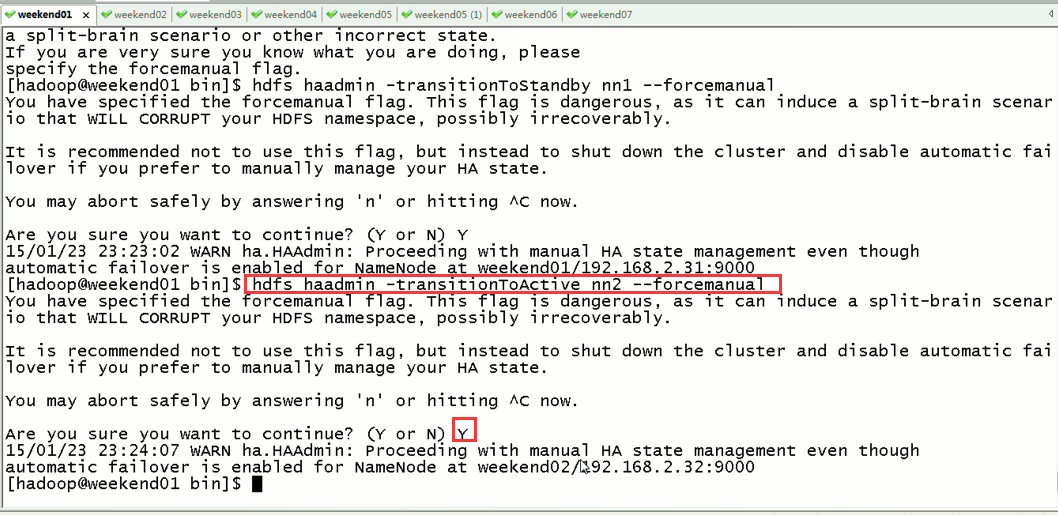

2) weekend03、04的resourcemanger的HA测试

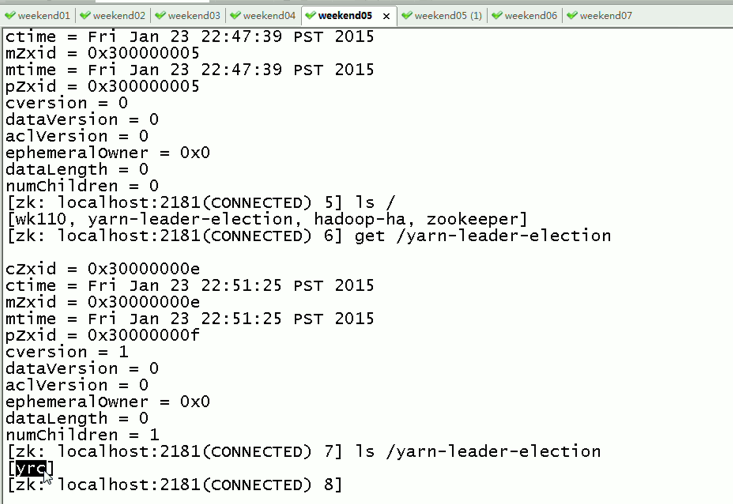
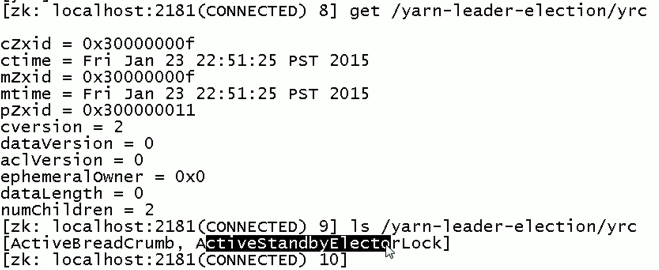
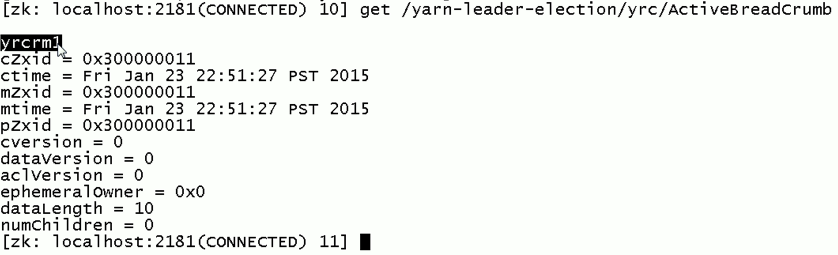
现在,来测试

会发现,yrcrm 变成 yrcrm
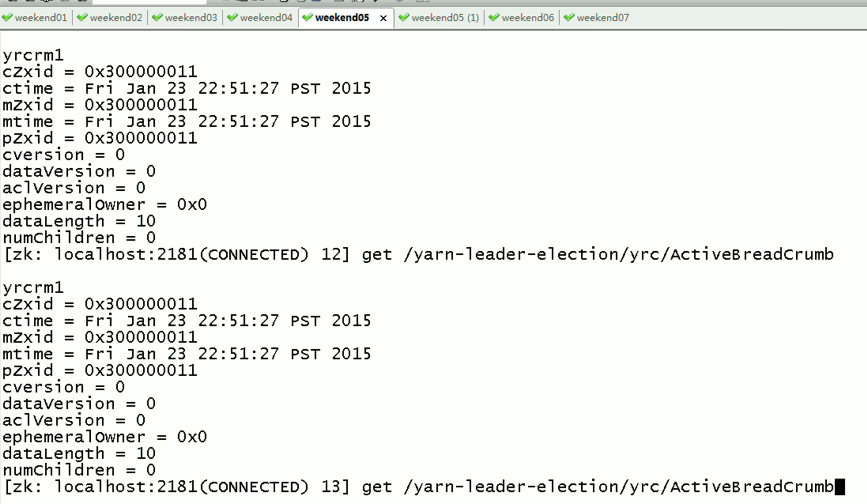
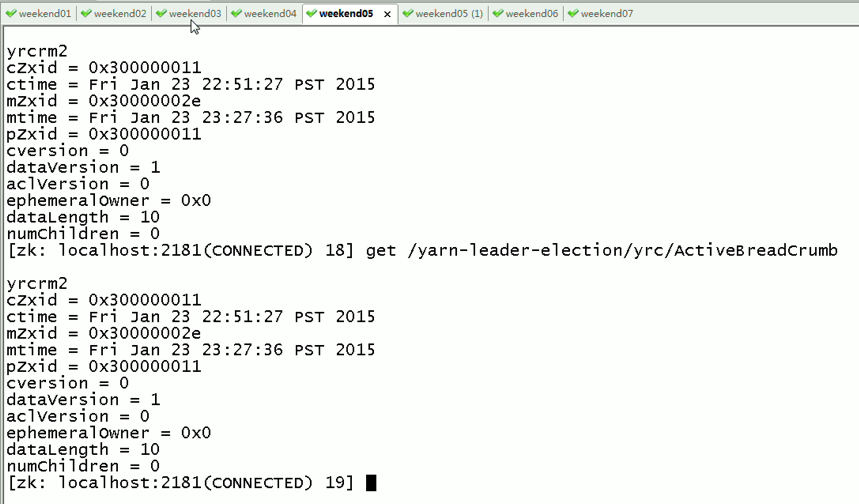
只是,resourcemanger的HA仅限于此,跟hdfs的HA不一样,
如weekend01(active)在上传文件,突然中断,weekend02(standby)
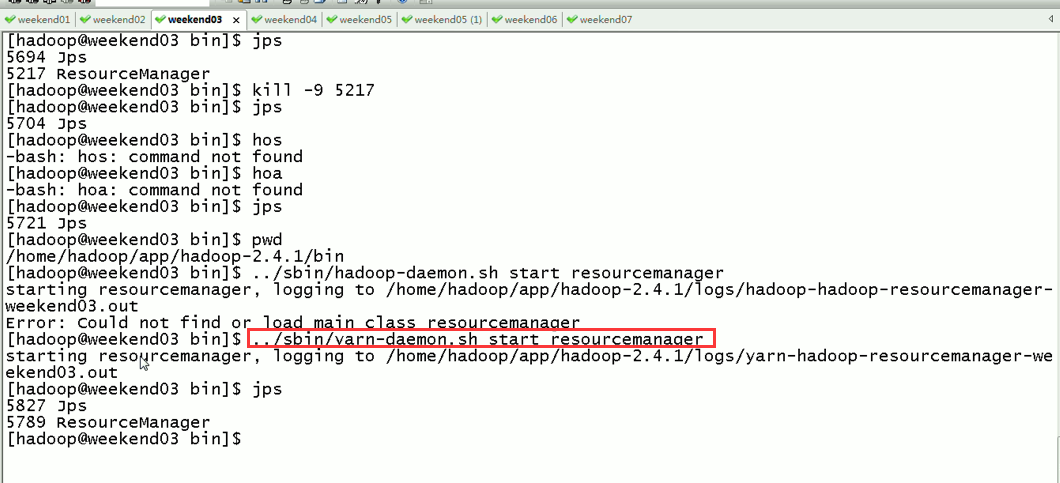

对于,weekend03、04的resourcemanager的HA,
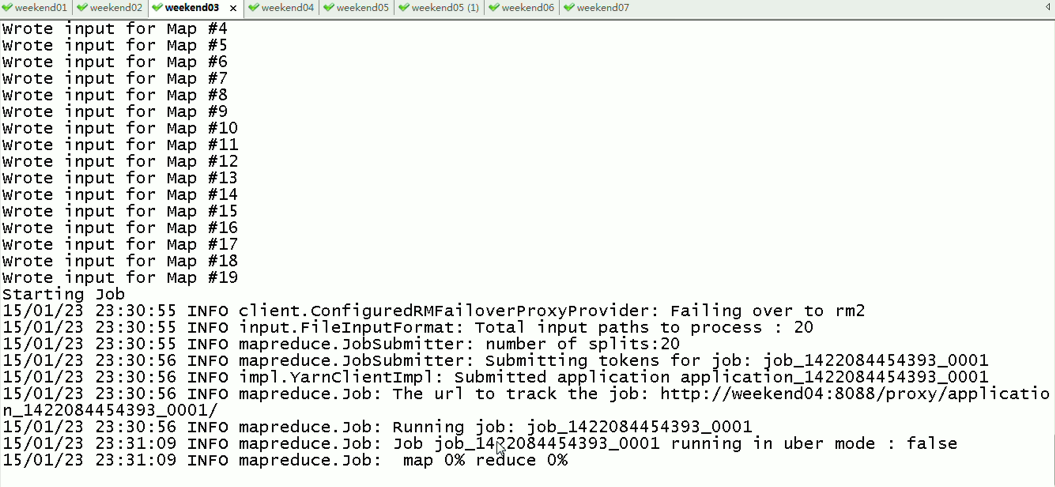
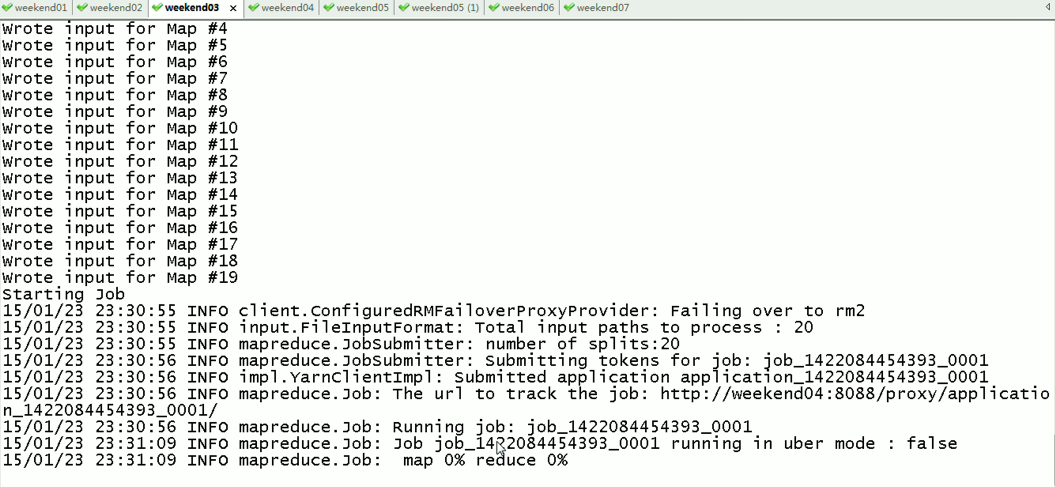
现在是,weekend03(standby)提交作业,weekend04(active)

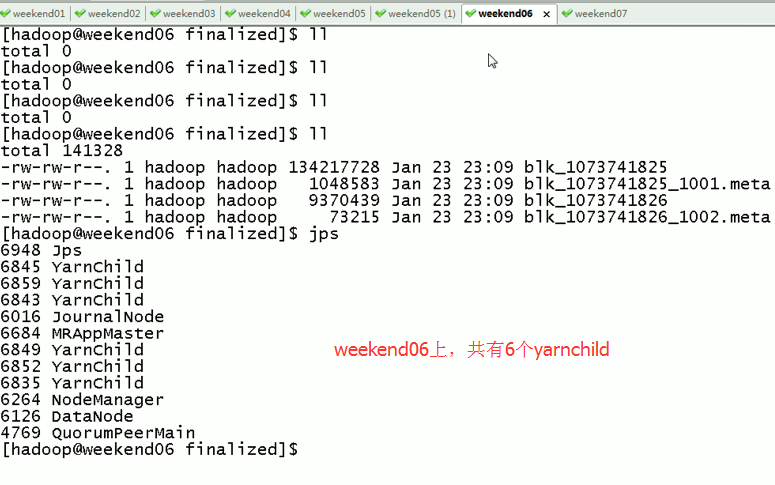
weekend07上,共有8个yarnchild,

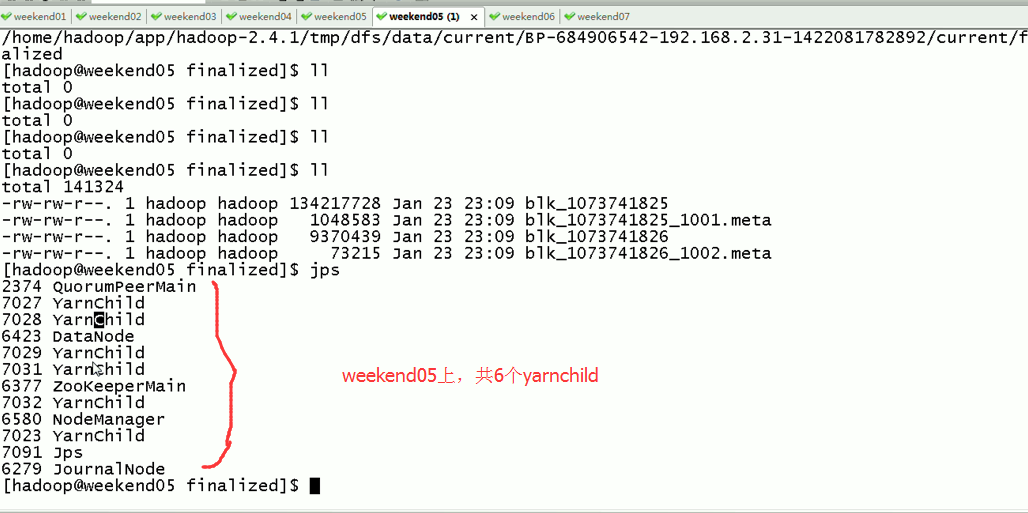
Weekend05、06、07一起,是20个yarnchild,跑作业的节点。

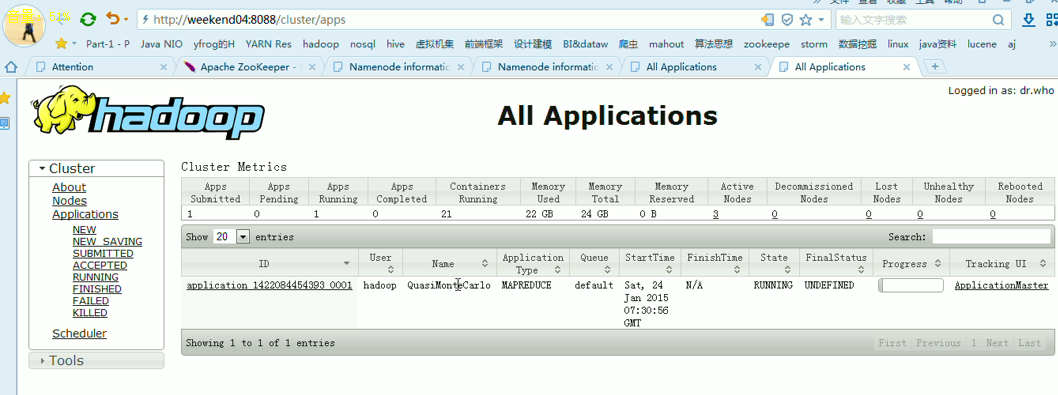
对于,weekend03、04的yarn的HA,
现在是,weekend03(standby)提交作业,weekend04(active)
现在依然还是,weekend03(standby)提交作业,weekend04(active)
以上是Weekend03、4的yarn的HA测试
总结:
以上是weekend01、02的hdfs的HA测试
Weekend03、4的yarn的HA测试
Weekend05、06、07是用来跑作业的,

关于hdfs的动态增加节点和副本数量管理,在视频里….
暂时,不赘述。
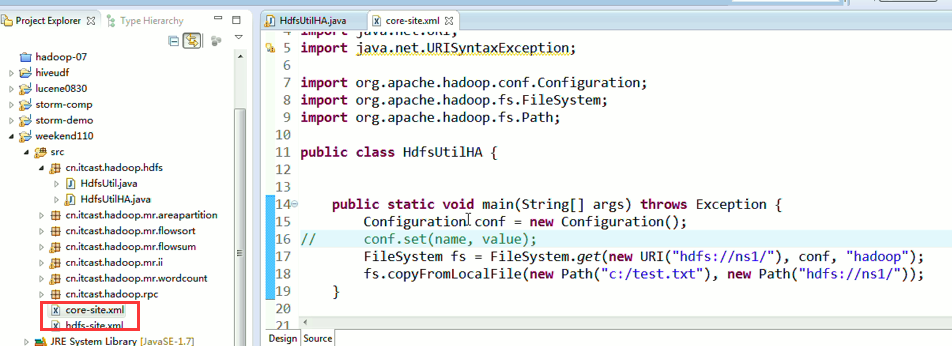
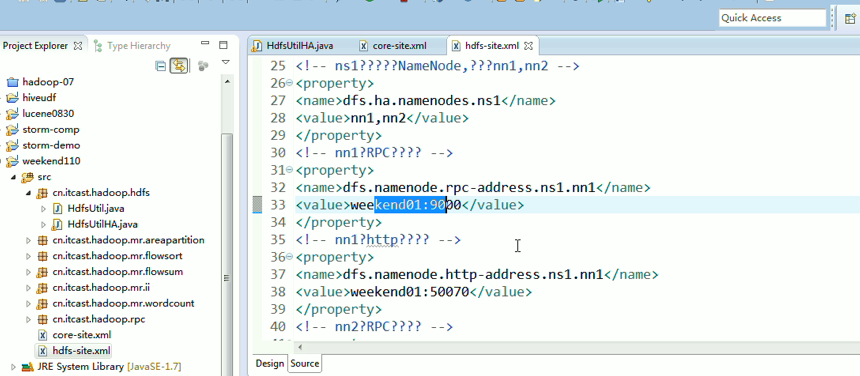
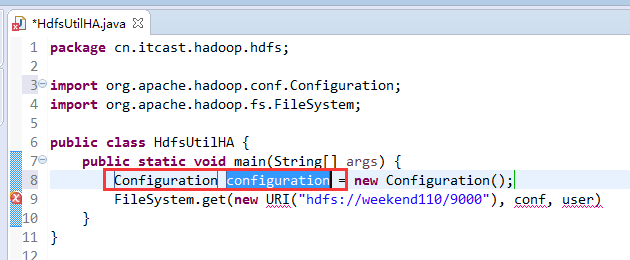
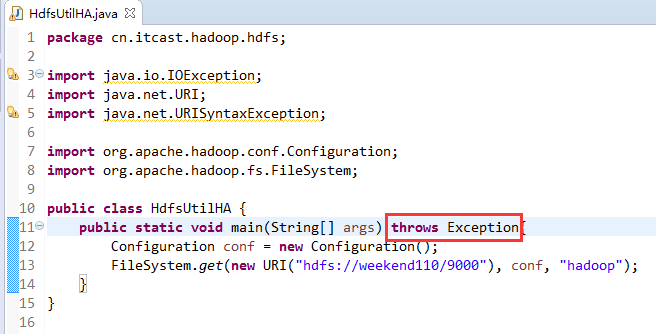
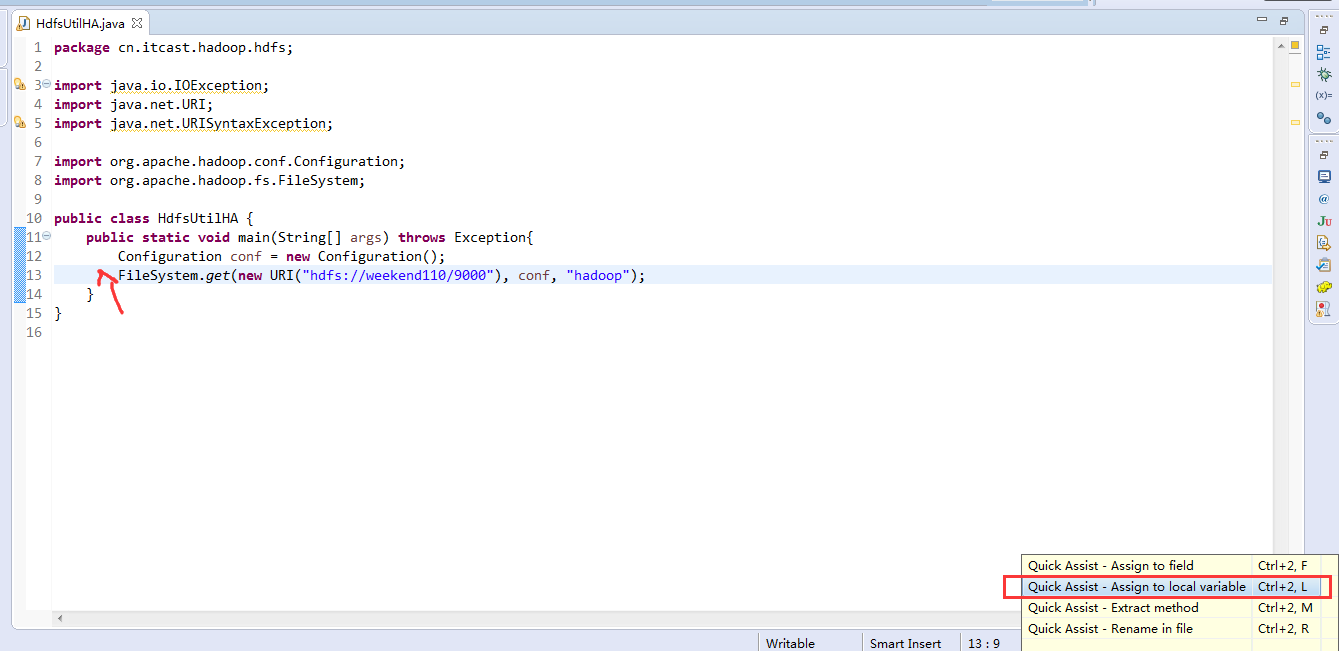
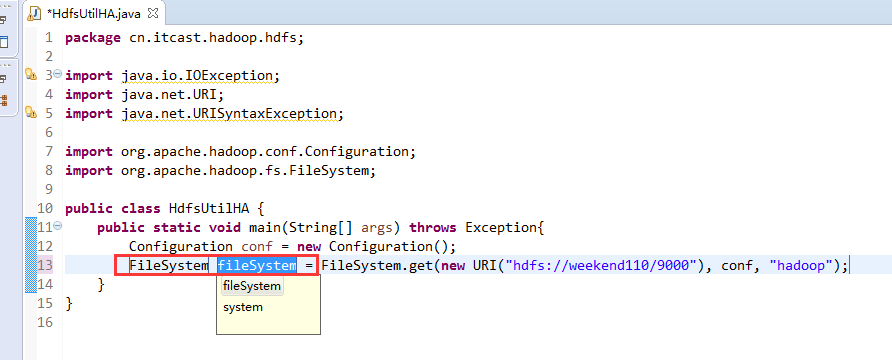
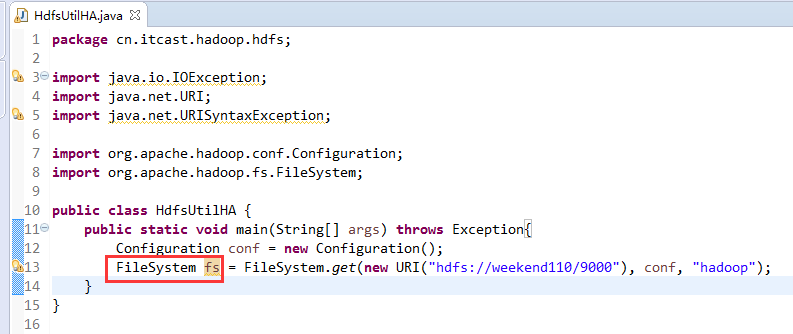
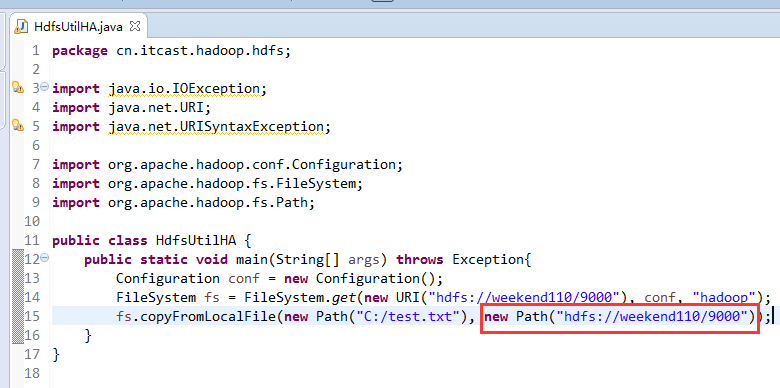
说明,下面是HA的java API访问,
所以,ns1和ns2,这里,是用ns1来访问。
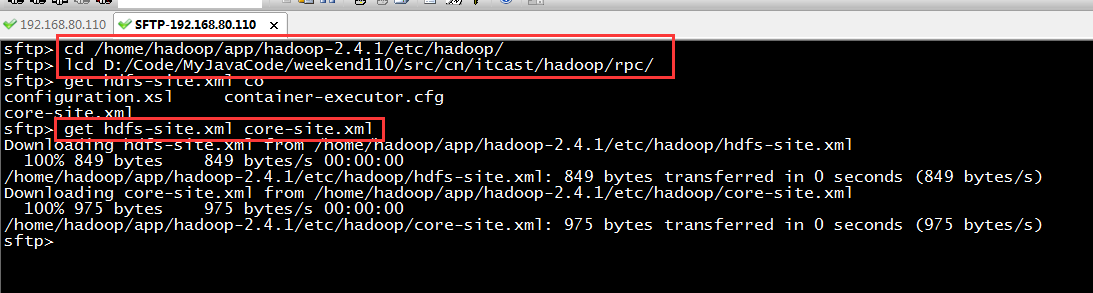
而我,自己当时想在weekend110里玩玩,出现了有错误。还没解决。
当然,这知识点,是要在ns1里的。
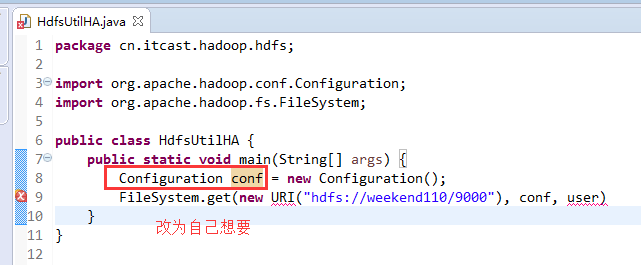
如果是视频里的话,则

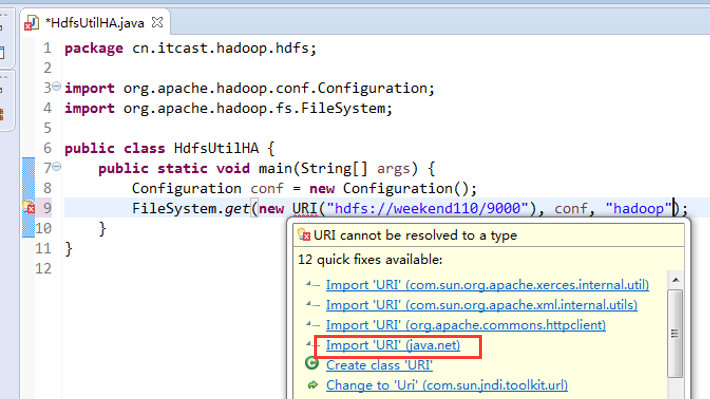
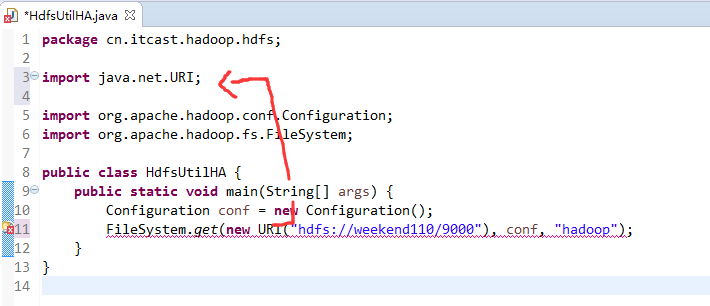
如果是自己玩玩的话,则

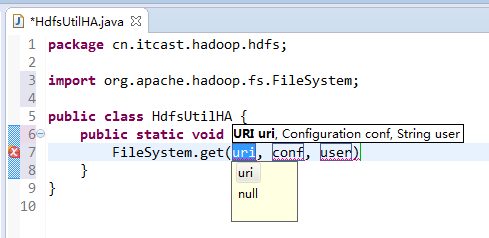
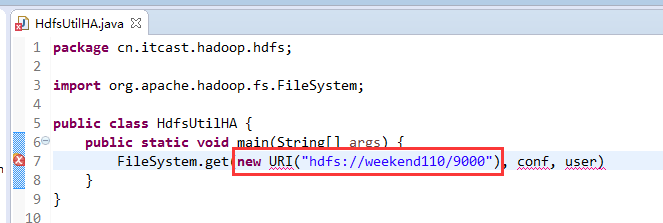
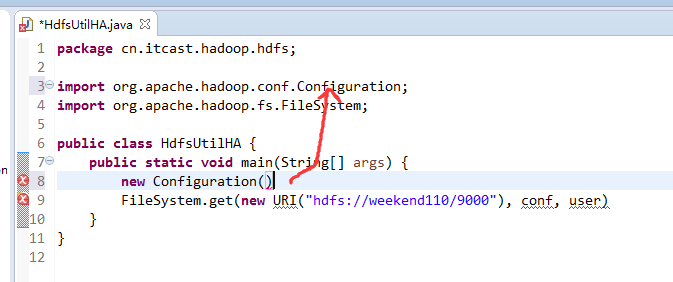


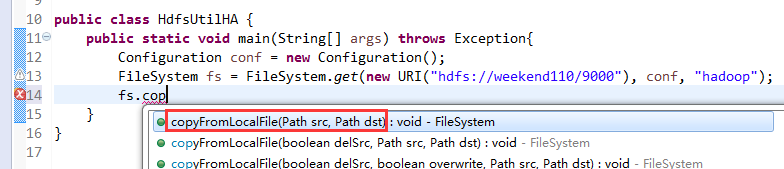
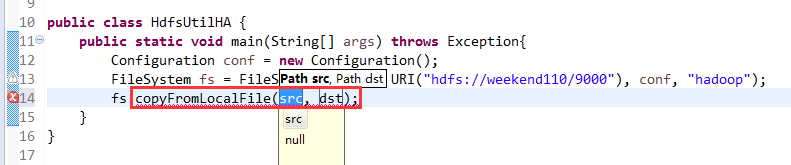
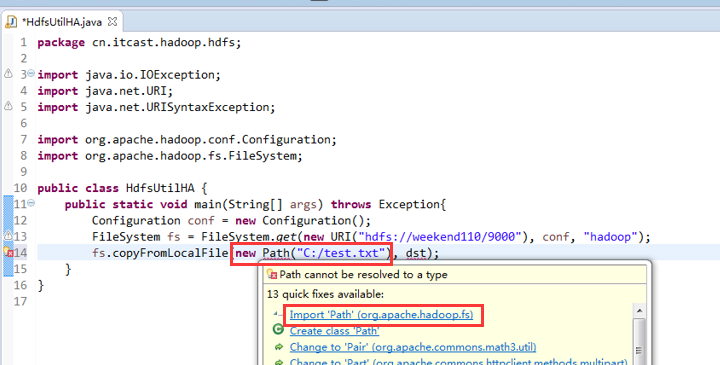
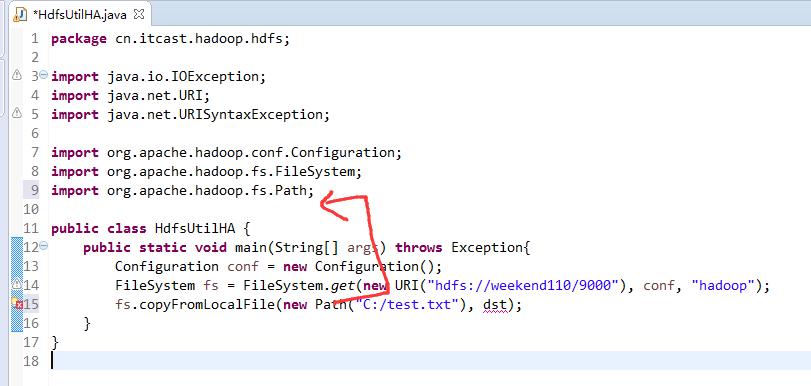
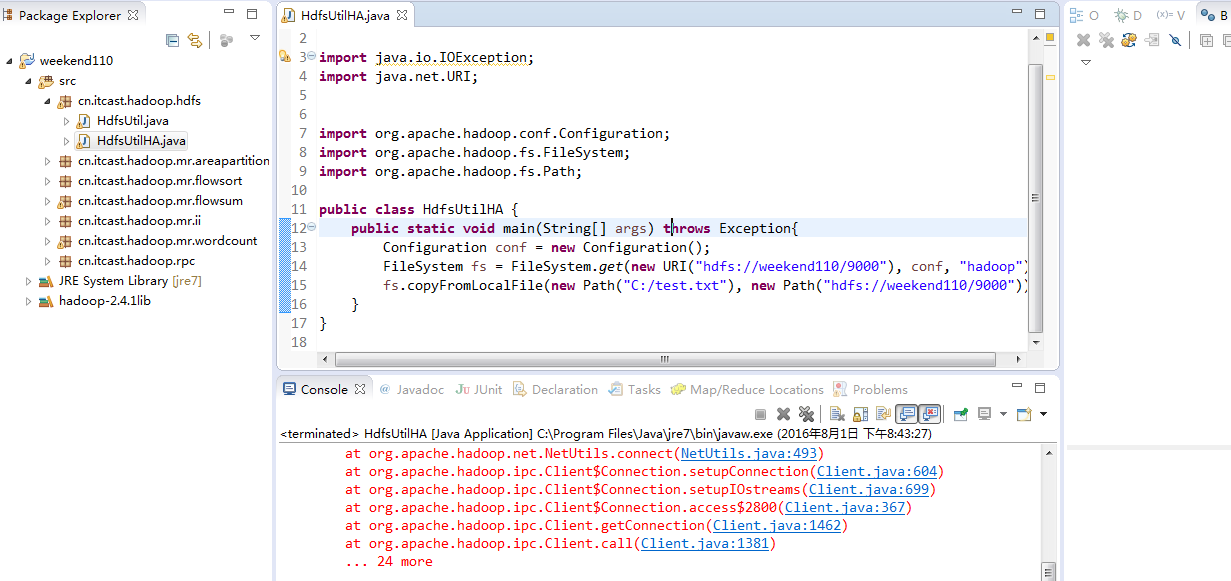
Exception in thread "main" java.net.ConnectException: Call From WIN-BQOBV63OBNM/192.168.56.1 to weekend110:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730)
at org.apache.hadoop.ipc.Client.call(Client.java:1414)
at org.apache.hadoop.ipc.Client.call(Client.java:1363)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:699)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1762)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398)
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:496)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:348)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:338)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1903)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1871)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1836)
at cn.itcast.hadoop.hdfs.HdfsUtilHA.main(HdfsUtilHA.java:15)
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:604)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:699)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1462)
at org.apache.hadoop.ipc.Client.call(Client.java:1381)
... 24 more
5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点的更多相关文章
- 3 视频里weekend05、06、07的可靠性 + HA原理、分析、机制 + weekend01、02、03、04、05、06、07的分布式集群搭建
现在,我们来验证分析下,zookeeper集群的可靠性 现在有weekend05.06.07 将其一个关掉, 分析,这3个zookeeper集群里,杀死了weekend06,还存活weekend05. ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 07、Spark集群的进程管理
07.Spark集群的进程管理 7.1 概述 Spark standalone集群模式涉及master和worker两个守护进程.master进程是管理节点,worker进程是工作节点.spark提供 ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- Ubuntu 16.04上搭建CDH5.16.1集群
本文参考自:<Ubuntu16.04上搭建CDH5.14集群> 1.准备三台(CDH默认配置为三台)安装Ubuntu 16.04.4 LTS系统的服务器,假设ip地址分布为 192.168 ...
- Ubuntu16.04搭建kubernetes v1.11.2集群
1.节点介绍 master cluster-1 cluster-2 cluster-3 hostname k8s-55 k8s-5 ...
随机推荐
- mac 下 sublime text 运行c++/c 不能使用scanf/cin
{ "cmd": ["g++", "${file}", "-o", "${file_path}/${file_ ...
- oracle安装,配置,启动
因为主要不是讲oracle这些,所以就略写. 注意安装的时候:确保以前安装过的卸载干净了.安装的路径不能包含中文.安装的时候需要创建两层数据库.因为在选择的安装目录的平行目录会产生文件. 确认卸载完可 ...
- 【python之旅】python的基础三
目录: 1.装饰器 2.迭代器&生成器 3.Json & pickle 数据序列化 4.软件目录结构规范 一.装饰器 定义:本质是函数,(装饰其他函数)就是为其他函数添加附加功能 原 ...
- 【python】python的二元表达式和三元表达式
二元表达式 x,y=4,3if x>y: s = yelse: s= x print s x if x<y else y 三元表达式: >>> def f(x,y): ...
- typedef与define基本使用
参考: typedef用法 http://www.cnblogs.com/ggjucheng/archive/2011/12/27/2303238.html#define用法:http://blog. ...
- C++ 11 笔记 (六) : 随机数
以前生成一个随机数都是这样: srand(time(NULL)); rand(); 在C++11中,标准库中增加了随机数引擎 std::default_random_engine 这个好东西,然后我们 ...
- 移动web HTML5使用photoswipe模仿微信朋友圈图片放大浏览
先来几张效果图: 点击其中一张照片可放大,可支持图片文字描述: 同时支持分享功能: 支持手势放大缩小 使用js框架是PhotoSwipe. PhotoSwipe是一个图片放大插件,兼容pc和移动端,经 ...
- Servlet的一些API使用介绍
final String rootPath = getServletConfig().getServletContext().getRealPath("/"); 获取项目运行的根 ...
- 2D image convolution
在学习cnn的过程中,对convolution的概念真的很是模糊,本来在学习图像处理的过程中,已对convolution有所了解,它与correlation是有不同的,因为convolution = ...
- vs2010 使用SignalR 提高B2C商城用户体验(一)
vs2010 使用SignalR 提高B2C商城用户体验(一) 1.需求简介,做为新时代的b2c商城,没有即时通讯,怎么提供用户粘稠度,怎么增加销量,用户购物的第一习惯就是咨询,即时通讯,应运而生.这 ...