9.3 k8s结合ELK实现日志收集
数据流:
logfile -> filebeat > kafka(依赖zookeeper)-> logstash -> elasticsearch -> kibana
1.部署zookeeper集群
1.1 主机IP规划
| hostname | IP |
|---|---|
| zk-kfk-1 | 192.168.2.26 |
| zk-kfk-2 | 192.168.2.27 |
| zk-kfk-3 | 192.168.2.28 |
3个服务器上都需要操作以下安装配置步骤
1.2 安装jdk11
apt install openjdk-11-jdk -y
1.3 下载安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
1.4 部署配置
tar xf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/
cd /usr/local
ln -s apache-zookeeper-3.7.0-bin/ zookeeper
cd conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /data/zookeeper-data
# 配置文件修改如下:
root@zk-kfk-1:/usr/local/zookeeper/conf# sed -e '/^#/d' -e '/^$/d' zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper-data
clientPort=2181
maxClientCnxns=150
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=192.168.2.26:2888:3888
server.2=192.168.2.27:2888:3888
server.3=192.168.2.28:2888:3888
1.5 启动服务并查看运行状态
# /usr/local/zookeeper/bin/zkServer.sh start
root@zk-kfk-1:# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
root@zk-kfk-2:# /usr/local/zookeeper/bin/zkServer.sh status
...
Mode: follower
root@zk-kfk-3:# /usr/local/zookeeper/bin/zkServer.sh status
...
Mode: leader
2.部署kafka
复用zookeeper集群3台服务器部署,以下操作3台服务器上都需要执行
2.1 下载安装包并解压
# 下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.0.0/kafka_2.13-3.0.0.tg
# 解压
tar xf kafka_2.13-3.0.0.tgz -C /usr/local/
cd /usr/local
ln -s kafka_2.13-3.0.0/ kafka
# 创建数据目录
mkdir -p /data/kafka-logs
2.2 修改配置文件
# vim /usr/local/kafka/config/server.properties
broker.id=26
listeners=PLAINTEXT://192.168.2.26:9092
log.dirs=/data/kafka-logs
zookeeper.connect=192.168.2.26:2181,192.168.2.27:2181,192.168.2.28:2181
2.3 启动服务
cd /usr/local/kafka && ./bin/kafka-server-start.sh -daemon config/server.properties
使用绝对路径启动会报错:
# /usr/local/kafka/bin/kafka-server-start.sh --daemon /usr/local/kafka/config/server.properties
[2021-10-28 08:51:14,097] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
[2021-10-28 08:51:14,455] ERROR Exiting Kafka due to fatal exception (kafka.Kafka$)
...
3.部署ES集群
复用zookeeper,kafka 3台服务器
3.1 下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.1-amd64.deb
3.2 安装
dpkg -i elasticsearch-7.15.1-amd64.deb
3.3 修改配置
集群中的另外2个节点的node.name,network.host 2个配置需按实际情况修改
# es node-1的配置
root@zk-kfk-1:/data# cat /etc/elasticsearch/elasticsearch.yml
cluster.name: k8s-elk
node.name: node-1
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 192.168.2.26
http.port: 9200
discovery.seed_hosts: ["192.168.2.26", "192.168.2.27","192.168.2.28"]
cluster.initial_master_nodes: ["192.168.2.26", "192.168.2.27","192.168.2.28"]
action.destructive_requires_name: true
# 创建数据和日志目录
mkdir -p /data/es/data
mkdir -p /data/es/logs
# 修改目录权限
chown -R elasticsearch:elasticsearch /data/es/
3.4 启动服务
systemctl start elasticsearch.service
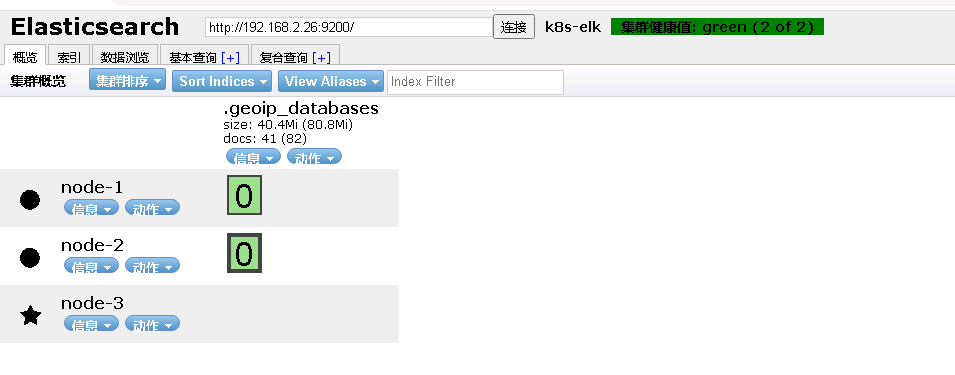
3.5 使用elasticsearch-head 查看es集群状态
chrome浏览器加载elasticsearch-head 插件参考:
https://blog.csdn.net/xiaolinzi176/article/details/105187311
4.pod中启动filebeat实现日志收集并输出到kafka
采用将filebeat和nginx放到一个容器里面方案
4.1 制作镜像
Dockerfile
FROM nginx:1.21.1
COPY nginx.conf /etc/nginx
COPY default.conf /etc/nginx/conf.d
COPY filebeat-7.15.1-amd64.deb /root
COPY start_filebeat.sh /docker-entrypoint.d
RUN rm -f /var/log/nginx/* \
&& dpkg -i /root/filebeat-7.15.1-amd64.deb \
&& rm -f /root/filebeat-7.15.1-amd64.deb
COPY filebeat.yml /etc/filebeat
filebeat.yaml配置文件
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
tail_files: true
tags: ["nginx-access"]
fields:
log_topics: nginx-access
setup.kibana:
host: "192.168.2.29:5601"
output.kafka:
enabled: true
hosts: ["192.168.2.26:9092","192.168.2.27:9092","192.168.2.28:9092"]
topic: '%{[fields][log_topics]}'
filebeat运行脚本
cat start_filebeat.sh
#/bin/bash
nohup /usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat 2>&1 &
镜像目录文件列表
filebeat-7.15.1-amd64.deb 可以在官网下载
总用量 35016
drwxr-xr-x 2 root root 4096 10月 29 14:42 ./
drwxr-xr-x 4 root root 4096 10月 28 18:59 ../
-rwxr-xr-x 1 root root 137 10月 29 14:39 build_command.sh*
-rw-r--r-- 1 root root 619 10月 28 18:59 default.conf
-rw-r--r-- 1 root root 317 10月 29 14:42 Dockerfile
-rw-r--r-- 1 root root 35821726 10月 28 18:59 filebeat-7.15.1-amd64.deb
-rw-r--r-- 1 root root 518 10月 29 14:27 filebeat.yml
-rw-r--r-- 1 root root 1270 10月 28 19:01 nginx.conf
-rwxr-xr-x 1 root root 207 10月 29 11:24 start_filebeat.sh*
build_command.sh 脚本
#!/bin/bash
TAG=$1
docker build -t 192.168.1.110/web/nginx-filebeat:${TAG} .
sleep 1
docker push 192.168.1.110/web/nginx-filebeat:${TAG}
生成镜像文件并上传到本地harbor
# ./build_command.sh 2021.10.29-144201
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.1.110/web/nginx-filebeat 2021.10.29-144201 8f011ec312e5 4 hours ago 312MB
使用docker run运行测试
# docker run -d -p 81:80 192.168.1.110/web/nginx-filebeat:2021.10.29-144201
root@k8-deploy:~/k8s-yaml/web/nginx_2/dockerfile# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
40dff03b2e4a 192.168.1.110/web/nginx-filebeat:2021.10.29-144201 "/docker-entrypoint.…" 4 hours ago Up 4 hours 0.0.0.0:81->80/tcp exciting_perlman
进入容器并查看nginx log
root@40dff03b2e4a:/# tail -f /var/log/nginx/*.log
==> /var/log/nginx/access.log <==
29/Oct/2021:06:44:57 +0000|172.17.0.1|localhost|GET / HTTP/1.1|200|612|0.000|905|76|-|-|curl/7.68.0
29/Oct/2021:06:51:43 +0000|127.0.0.1|localhost|GET / HTTP/1.1|200|612|0.000|905|73|-|-|curl/7.64.0
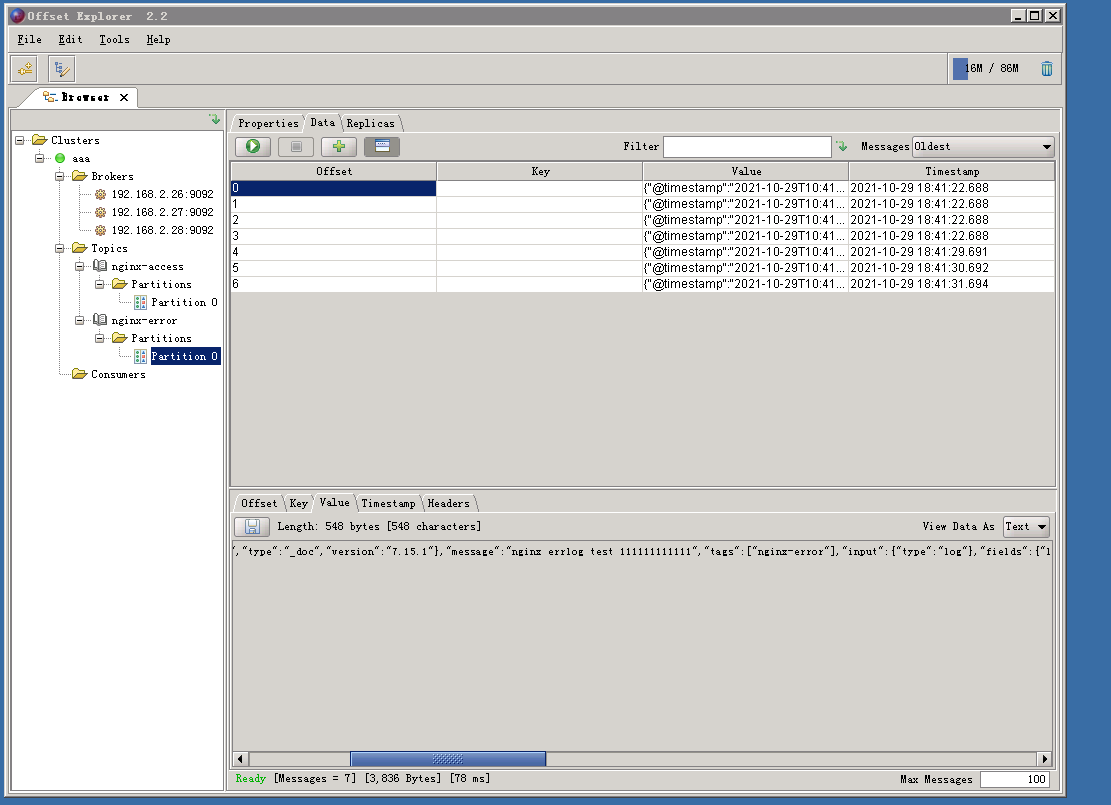
使用kafka客户端工具(offsetexplorer_64bit.exe)查看kafka中是否已经有数据
5.部署logstash将kakfa数据输出至elasticsearch集群
5.1 下载logstash安装包
https://artifacts.elastic.co/downloads/logstash/logstash-7.15.1-amd64.deb
5.2 安装
dpkg -i logstash-7.15.1-amd64.deb
5.3 编写logstash处理nginx日志的配置文件
配置文件路径:/etc/logstash/conf.d/kafka-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.2.26:9092,192.168.2.27:9092,192.168.2.28:9092"
auto_offset_reset => "latest"
topics=> ["nginx-access"]
consumer_threads => 2
decorate_events => "true"
}
}
#=============================================================================
filter {
json {
source => "message"
}
mutate{
split => ["message","|"]
add_field => { "time_local" => "%{[message][0]}" }
add_field => { "client_ip" => "%{[message][1]}" }
add_field => { "domain_name" => "%{[message][2]}" }
add_field => { "request" => "%{[message][3]}" }
add_field => { "status" => "%{[message][4]}" }
add_field => { "body_bytes_sent" => "%{[message][5]}" }
add_field => { "request_time" => "%{[message][6]}" }
add_field => { "bytes_sent" => "%{[message][7]}" }
add_field => { "request_length" => "%{[message][8]}" }
add_field => { "upstream_response_time" => "%{[message][9]}" }
add_field => { "http_referer" => "%{[message][10]}" }
add_field => { "user_agent" => "%{[message][11]}" }
remove_field => ["message", "log", "file", "offset", "ecs", "version", "path", "agent", "beat", "@version", "input", "prospector", "source", "offset"]
}
date {
match => [ "time_local","dd/MMM/YYYY:HH:mm:ss Z" ]
target => "@timestamp"
}
}
#=============================================================================
#调试用
output {
stdout { codec => rubydebug }
}
# 生产环境使用
#output {
# elasticsearch {
# hosts => [ "http://192.168.2.26:9200","http://192.168.2.27:9200","http://192.168.2.28:9200"]
# index => "%{tags}-%{+YYYY.MM.dd}"
# }
#}
测试配置文件
root@zk-kfk-1:/etc/logstash/conf.d# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka-to-es.conf -t
Using bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-10-29 19:05:14.181 [main] runner - Starting Logstash {"logstash.version"=>"7.15.1", "jruby.version"=>"jruby 9.2.19.0 (2.5.8) 2021-06-15 55810c552b OpenJDK 64-Bit Server VM 11.0.12+7 on 11.0.12+7 +indy +jit [linux-x86_64]"}
[INFO ] 2021-10-29 19:05:14.293 [main] writabledirectory - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-10-29 19:05:14.330 [main] writabledirectory - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-10-29 19:05:15.140 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-10-29 19:05:18.207 [LogStash::Runner] Reflections - Reflections took 166 ms to scan 1 urls, producing 120 keys and 417 values
[WARN ] 2021-10-29 19:05:20.035 [LogStash::Runner] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
Configuration OK
5.5 使用调试模式将logstash处理后的日志直接打印到屏
root@zk-kfk-1:/etc/logstash/conf.d# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka-to-es.conf
...
5.6 在nginx容器内重新写几条数据进行测试
root@40dff03b2e4a:/# curl 127.0.0.1
5.7 观察logstash是否有相关日志的输出
{
"request" => "GET / HTTP/1.1",
"client_ip" => "127.0.0.1",
"status" => "200",
"@timestamp" => 2021-10-29T11:07:16.000Z,
"request_length" => "73",
"http_referer" => "-",
"domain_name" => "localhost",
"user_agent" => "curl/7.64.0",
"bytes_sent" => "905",
"request_time" => "0.000",
"time_local" => "29/Oct/2021:11:07:16 +0000",
"fields" => {
"log_topics" => "nginx-access"
},
"host" => {
"name" => "40dff03b2e4a"
},
"upstream_response_time" => "-",
"tags" => [
[0] "nginx-access"
],
"body_bytes_sent" => "612"
}
5.7 测试没问题后,更改logstash的配置文件,将日志写入es集群,并重新以服务的方式启动logstash
# 修改配置文件 kafka-to-es.conf
#output {
# stdout { codec => rubydebug }
#}
output {
elasticsearch {
hosts => [ "http://192.168.2.26:9200","http://192.168.2.27:9200","http://192.168.2.28:9200"]
index => "%{tags}-%{+YYYY.MM.dd}"
}
}
# systemctl start logstash.service
6.部署kibana并验证数据
6.1 下载安装包并安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.15.1-amd64.deb
dpkg -i kibana-7.15.1-amd64.deb
6.2 修改配置文件如下参数
# 配置文件 /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.2.27"
elasticsearch.hosts: ["http://192.168.2.29:9200"]
i18n.locale: "zh-CN"
6.3 查看kibana监听端口
root@zk-kfk-2:~# netstat -ntlp |grep 5601
tcp 0 0 192.168.2.27:5601 0.0.0.0:* LISTEN 31969/node
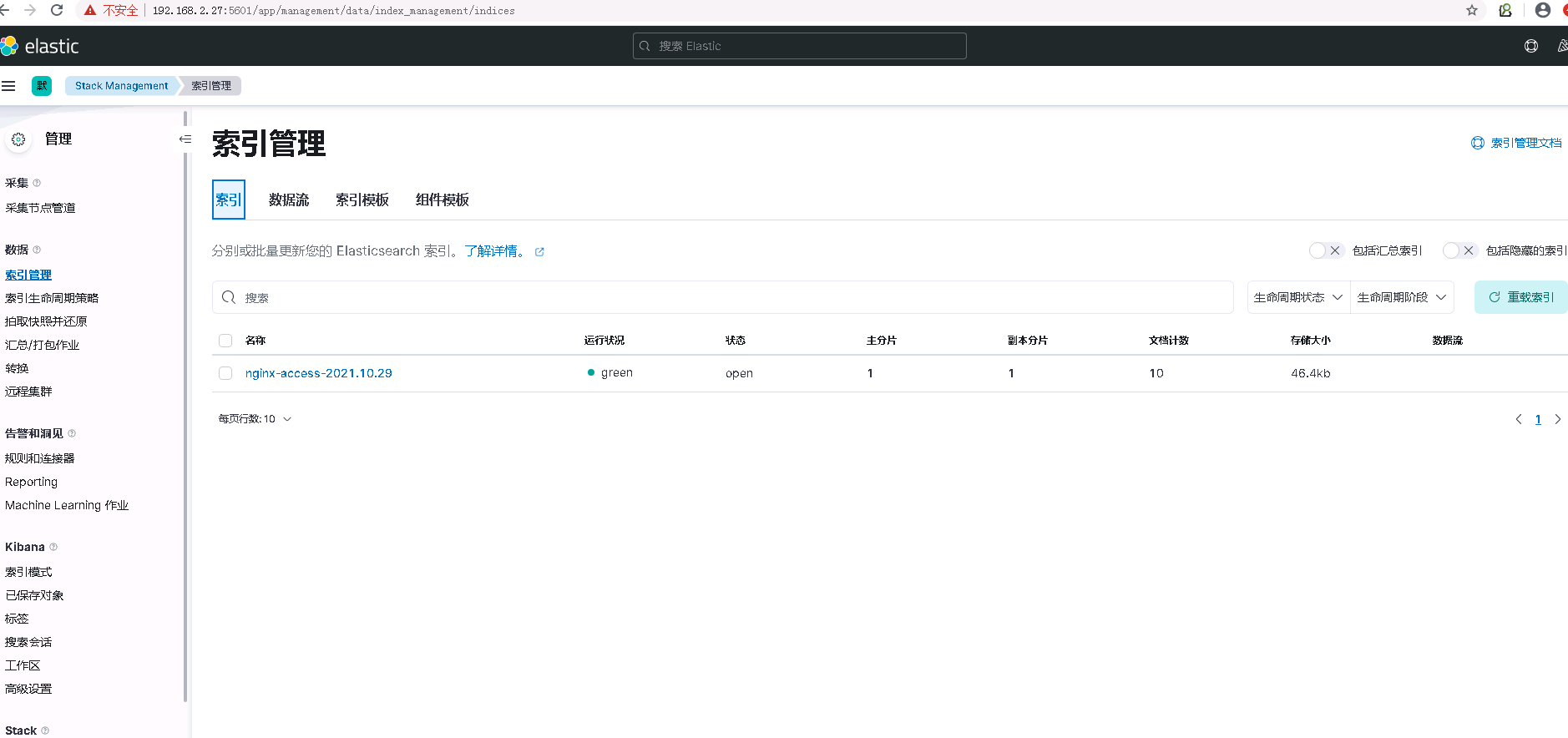
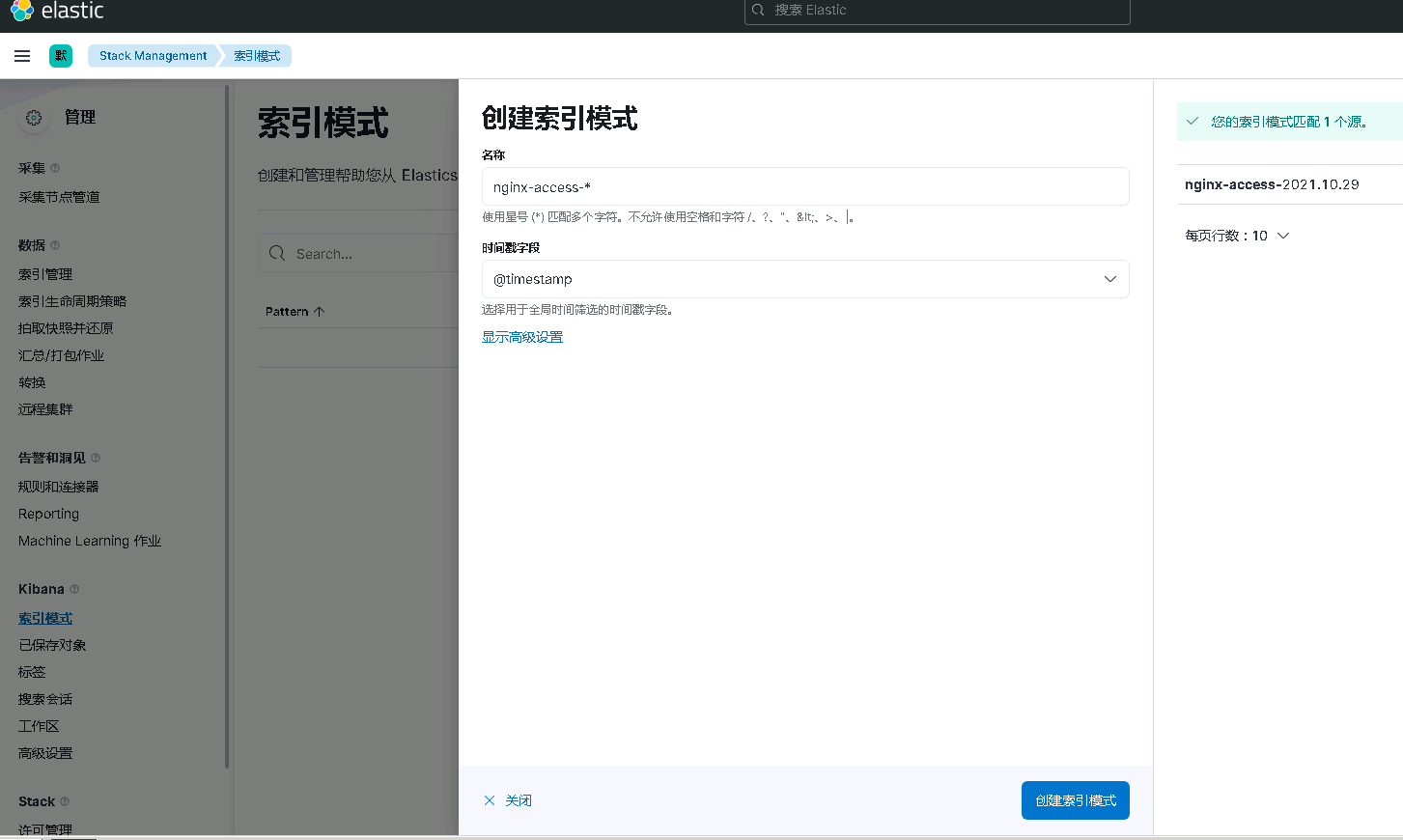
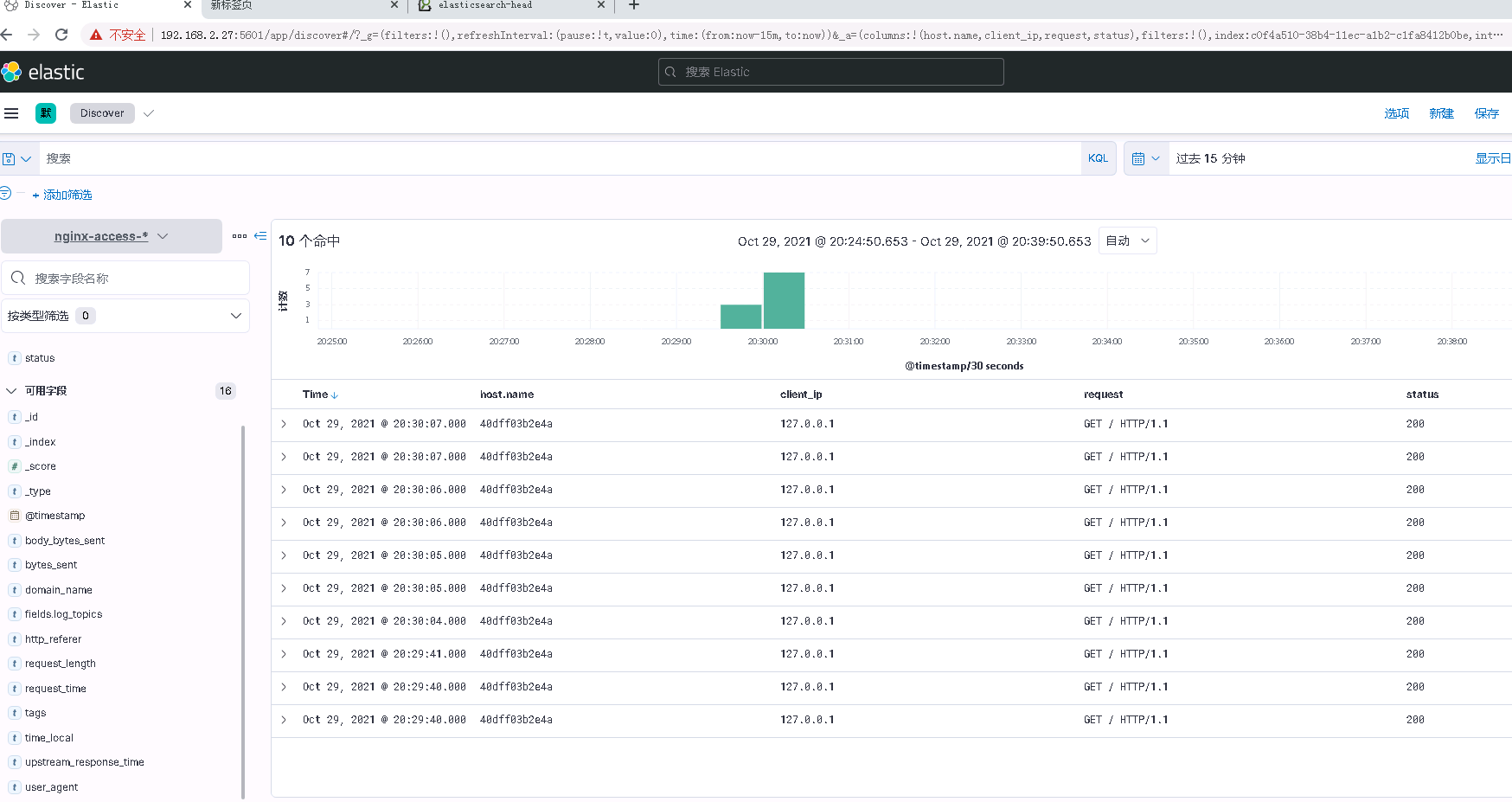
6.4 浏览器访问kibana并测试
9.3 k8s结合ELK实现日志收集的更多相关文章
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程)
@ 目录 StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程) 一.下载ELK的安装包上传并解压 1.Elasticsearch下载 2.Logstash下载 3.Kibana ...
- SpringBoot+kafka+ELK分布式日志收集
一.背景 随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用.那么随着节点的增多,各个 ...
- 关于K8s集群器日志收集的总结
本文介绍了kubernetes官方提供的日志收集方法,并介绍了Fluentd日志收集器并与其他产品做了比较.最后介绍了好雨云帮如何对k8s进行改造并使用ZeroMQ以消息的形式将日志传输到统一的日志处 ...
- 微服务下,使用ELK做日志收集及分析
一.使用背景 目前项目中,采用的是微服务框架,对于日志,采用的是logback的配置,每个微服务的日志,都是通过File的方式存储在部署的机器上,但是由于日志比较分散,想要检查各个微服务是否有报错信息 ...
- ELK+kafka日志收集
一.服务器信息 版本 部署服务器 用途 备注 JDK jdk1.8.0_102 使用ELK5的服务器 Logstash 5.1.1 安装Tomcat的服务器 发送日志 Kafka降插件版本 Log ...
- 传统ELK分布式日志收集的缺点?
传统ELK图示: 单纯使用ElK实现分布式日志收集缺点? 1.logstash太多了,扩展不好. 如上图这种形式就是一个 tomcat 对应一个 logstash,新增一个节点就得同样的拥有 logs ...
- ELK:日志收集分析平台
简介 ELK是一个日志收集分析的平台,它能收集海量的日志,并将其根据字段切割.一来方便供开发查看日志,定位问题:二来可以根据日志进行统计分析,通过其强大的呈现能力,挖掘数据的潜在价值,分析重要指标的趋 ...
- ELK/EFK——日志收集分析平台
ELK——日志收集分析平台 ELK简介:在开源的日志管理方案之中,最出名的莫过于ELK了,ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成.1)ElasticSea ...
随机推荐
- 内网渗透DC-5靶场通关
个人博客地址:点我 DC系列共9个靶场,本次来试玩一下一个 DC-5,只有一个flag,下载地址. 下载下来后是 .ova 格式,建议使用vitualbox进行搭建,vmware可能存在兼容性问题.靶 ...
- vue 解决axios请求出现前端跨域问题
vue 解决axios请求出现前端跨域问题 最近在写纯前端的vue项目的时候,碰到了axios请求本机的资源的时候,出现了访问报404的问题.这就让我很难受.查询了资料原来是跨域的问题. 在正常开发中 ...
- cunda 常用命令,删除,创建,换源
https://github.com/tensorflow/tensorflow/ conda create --name [虚拟环境名] python=3.7 创建一个环境 conda activa ...
- [技术博客]Django框架-后端的搭建
目录 Django框架-后端的搭建 前言 环境的部署 项目的创建 app的使用 创建app 修改配置文件 app中数据表的构建 前端接口 接口的路径 运行服务器 验证后端 Django框架-后端的搭建 ...
- Noip模拟76 2021.10.14
T1 洛希极限 上来一道大数据结构或者单调队列优化$dp$ 真就没分析出来正解复杂度 正解复杂度$O(q+nm)$,但是据说我的复杂度是假的 考虑一个点转移最优情况是从它上面的一个反$L$形转移过来 ...
- 字符串与模式匹配算法(三):KMP算法
一.KMP算法介绍 KMP算法与前面的MP算法一脉相承,都是充分利用先前匹配的过程中已经得到的结果来避免频繁回溯.回顾一下MP算法,如下图的模式串偏移,当前模式字符串P的左端的p0与目标字符串T中tj ...
- cf Learn from Life (简单贪心)
有N个人站在一楼.一个电梯最多承载K个人. 每个人都有一个想去的楼层.f[1]....f[N]. f[i]属于[2,2000] 从a层到b层需花费abs(a-b)秒. 问电梯送完所有人然后回到一楼至少 ...
- 开发笔记----- python3 小甜点
一.字典内容排序 1.根据 值大小排序,默认reverse=False:从小到大排序,True:从大到小排序.例: >>> dic1 = {'a1':4,'b1':12,'c1':1 ...
- 优客源创会 西安站 西邮Linux兴趣小组
2016年5月19日晚7:00,优客源创会西安站在西安邮电大学长安校区东区教学楼FF305如期举行,西安邮电大学计算机学院教授.西邮Linux兴趣小组指导老师陈莉君.王小银老师和来自开源中国的周凯先生 ...
- Jmeter 正则表达式提取Response Headers,Response Body里的值
实践过程中遇到需要提取Response Headers,Response Body里的值 一.获取Response Body的值,这里采用json提取器形式 1.Response Body返回值,如下 ...