Categorical Reparameterization with Gumbel-Softmax
概
利用梯度反向传播训练网咯几乎是深度学习的不二法门, 但是这往往要求保证梯度的存在, 这在一定程度上限制了一些扩展. 比如在VAE中, 虽然当\(q_{\phi}(z|x)\)是一个正态分布的时候, 我们可以利用reparameterization来保证梯度存在, 即:
\]
但是倘若中间变量是离散变量, 比如我们期望构建一个条件的VAE, 那么我们就没法用这种方式来解决了, 本文就提出了一个对离散分布的近似.
主要内容
Gumbel distribution
由gumbel distribution的性质可以知道, 从离散分布中采样\([\pi_1, \cdots, \pi_k]\)等价于
\]
又\(\arg \max\) 可的一个连续逼近为softmax, 即
\]
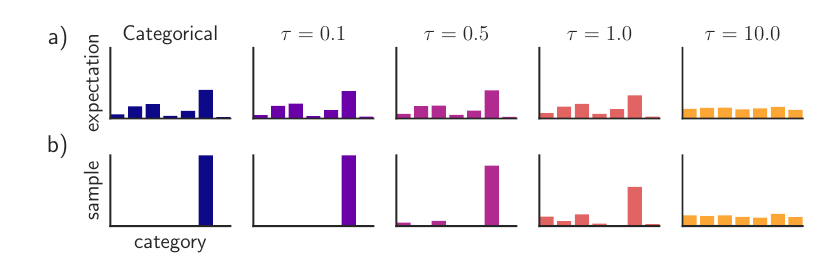
可以发现, 当\(\tau\)比较小的时候, Gumbel-Softmax分布的期望和离散分布的期望是一致的, 采样的情况也是相同的, 我们可以选择一个较小的\(\tau\)使得Gumbel-Softmax分布是离散分布的一个连续近似.
注: 作者偏爱先取一个较大的\(\tau\), 再退火至一个小的\(\tau=0.5\).
注: 作者在概率密度函数的推导过程中, 即公式(15)出有一个小错误, 应当是\(e^{-v}\)而非\(e^{x_k -v}\).
Categorical Reparameterization with Gumbel-Softmax的更多相关文章
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- Texygen文本生成,交大计算机系14级的朱耀明
文本生成哪家强?上交大提出基准测试新平台 Texygen 2018-02-12 13:11测评 新智元报道 来源:arxiv 编译:Marvin [新智元导读]上海交通大学.伦敦大学学院朱耀明, 卢思 ...
- (论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
目录 摘要 1.引言 2.相关工作 3.方法 3.1局部特征聚合的再思考 3.2 曲线分组 3.3 曲线聚合和CurveNet 4.实验 4.1 应用细节 4.2 基准 4.3 消融研究 5.总结 W ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
- Gumbel-Softmax Trick和Gumbel分布
之前看MADDPG论文的时候,作者提到在离散的信息交流环境中,使用了Gumbel-Softmax estimator.于是去搜了一下,发现该技巧应用甚广,如深度学习中的各种GAN.强化学习中的A2 ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- [Machine Learning] logistic函数和softmax函数
简单总结一下机器学习最常见的两个函数,一个是logistic函数,另一个是softmax函数,若有不足之处,希望大家可以帮忙指正.本文首先分别介绍logistic函数和softmax函数的定义和应用, ...
- 前馈网络求导概论(一)·Softmax篇
Softmax是啥? Hopfield网络的能量观点 1982年的Hopfiled网络首次将统计物理学的能量观点引入到神经网络中, 将神经网络的全局最小值求解,近似认为是求解热力学系统的能量最低点(最 ...
随机推荐
- day09搭建均衡负载和搭建BBS博客系统
day09搭建均衡负载和搭建BBS博客系统 搭建BBS博客系统 本次搭建bbs用到的技术 需要用到的: 1.Nginx+Django 2.Django+MySQL 环境准备 主机 IP 身份 db01 ...
- 24. 解决Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
第一种: sudo vim /etc/resolv.conf 添加nameserver 8.8.8.8 第二种: /etc/apt/sources.list 的内容换成 deb http://old- ...
- Notepad++【远程操作linux文件】
目录 目的 预期效果 操作步骤 1.打开插件 2.安装NppFTP 3.连接远程主机 注意 目的 通过Notepad++远程登录linux主机,修改配置文件 预期效果 在Notepad++上登录lin ...
- Lottie 使用
原文:https://mp.weixin.qq.com/s?__biz=MzIxNjc0ODExMA==&mid=2247485033&idx=1&sn=54dd477b4c4 ...
- tomcat源码1
Lifecycle:(接口) LifecycleBase:abstract:添加,删除Listener,各种init,start,stop,destory LifecycleMBeanBase:abs ...
- JDBC(2):JDBC对数据库进行CRUD
一. statement对象 JDBC程序中的Connection用于代表数据库的链接:Statement对象用于向数据库发送SQL语句:ResultSet用于代表Sql语句的执行结果 JDBC中的s ...
- vueAPI (data,props,methods,watch,computed,template,render)
data Vue 实例的数据对象.Vue 将会递归将 data 的属性转换为 getter/setter,从而让 data 的属性能够响应数据变化.实例创建之后,可以通过vm.$data来访问原始数据 ...
- Spring MVC与html页面的交互(以传递json数据为例)
一.导入相jar包 主要包括spring相关jar包和fastjson jar包,具体步骤略. 二.配置相关文件 1.配置web.xml文件 <?xml version="1.0&qu ...
- XML(可拓展标记语言)基本概念
一.XML文档基本结构 <?xml version="1.0" encoding="utf-8"?> <students> <st ...
- 【Spark】【RDD】从HDFS创建RDD
1.在HDFS根目录下创建目录(姓名学号) hdfs dfs -mkdir /zwj25 hdfs dfs -ls / 访问 http://[IP]:50070 2.上传本地文件到HDFS hdfs ...