k8s入坑之路(10)kubernetes coredns详解
概述
作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,那么就需要一个集群范围内的DNS服务来完成从服务名到ClusterIP的解析。
DNS服务在kubernetes中经历了三个阶段。
第一阶段,在kubernetes 1.2版本时,dns服务使用的是由SkyDNS提供的,由4个容器组成:kube2sky、skydns、etcd和healthz。etcd存储dns记录;kube2sky监控service变化,生成dns记录;skydns读取服务,提供查询服务;healthz提供健康检查
第二阶段,在kubernetes 1.4版本开始使用kubedns,有3个容器组成:kubedns、dnsmasq和sidecar。kubedns监控service变化,并记录到内存(存到内存提高性能)中;dnsmasq获取dns记录,提供dns缓存,提供dns查询服务;sidecar提供健康检查。
第三阶段,从kubernetes 1.11版本开始,dns服务有coredns提供,coredns支持自定义dns记录及配置upstream dns server,可以统一管理内部dns和物理dns。coredns只有一个coredns容器。下面是coredns的架构
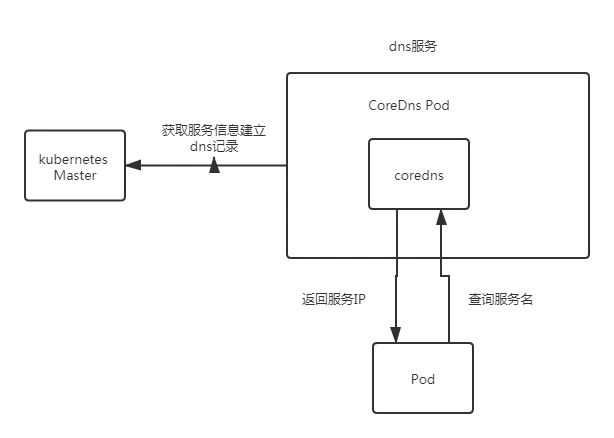
coredns配置解析
下面是coredns的配置模板


.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
172.23.1.3 hub.kellan.com
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
coredns配置模板
coredns的主要功能是通过插件系统实现的。它实现了一种链式插件的结构,将dns的逻辑抽象成了一个个插件。常见的插件如下:
- loadbalance:提供基于dns的负载均衡功能
- loop:检测在dns解析过程中出现的简单循环问题
- cache:提供前端缓存功能
- health:对Endpoint进行健康检查
- kubernetes:从kubernetes中读取zone数据
- etcd:从etcd读取zone数据,可以用于自定义域名记录
- file:从文件中读取zone数据
- hosts:使用/etc/hosts文件或者其他文件读取zone数据,可以用于自定义域名记录
- auto:从磁盘中自动加载区域文件
- reload:定时自动重新加载Corefile配置文件的内容
- forward:转发域名查询到上游dns服务器
- proxy:转发特定的域名查询到多个其他dns服务器,同时提供到多个dns服务器的负载均衡功能
- prometheus:为prometheus系统提供采集性能指标数据的URL
- pprof:在URL路径/debug/pprof下提供运行是的西能数据
- log:对dns查询进行日志记录
- errors:对错误信息镜像日志记录
Pod的dns策略
上面已经描述了dns的服务端,那么pod有什么策略呢
目前的策略如下:
- Default: 继承Pod所在宿主机的DNS设置
- ClusterFirst:优先使用kubernetes环境的dns服务,将无法解析的域名转发到从宿主机继承的dns服务器
- ClusterFirstWithHostNet:和ClusterFirst相同,对于以hostNetwork模式运行的Pod应明确知道使用该策略
- None: 忽略kubernetes环境的dns配置,通过spec.dnsConfig自定义DNS配置
自定义Dns配置可以通过spec.dnsConfig字段进行设置,可以设置如下信息- nameservers:一组dns服务器的列表,最多可设置3个
- searchs:一组用于域名搜索的dns域名后缀,最多6个
- options:配置其他可选参数,例如ndots、timeout等
例如:
1 spec:
2 dnsPolicy: "None"
3 dnsConfig:
4 nameservers:
5 - 1.2.3.4
6 searchs:
7 - xx.ns1.svc.cluster.local
8 - xx.daemon.com
9 options:
10 - name: ndots
11 values: "2"
pod被创建后,容器内的/etc/resolv.conf会根据这个信息进行配置
nodelocaldns
架构图如下
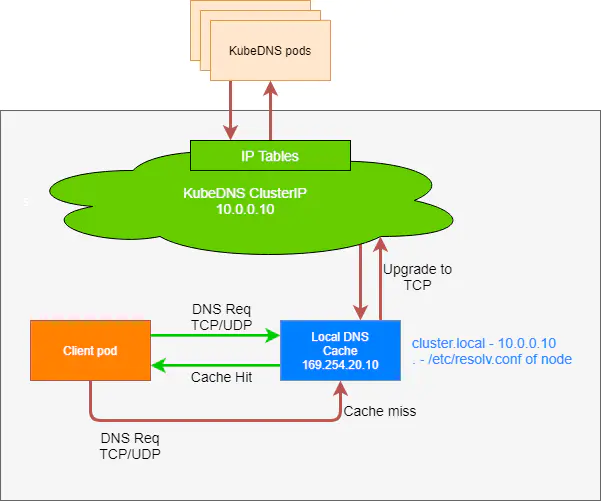
下面是nodelocaldns的configmap的示例
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
health 169.254.25.10:9254
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . /etc/resolv.conf
prometheus :9253
}
但是这里要进一步说明下,通过配置可以看出除了cluster.local(即kubernetes集群的解析)外都使用节点的/etc/resolv.conf文件的nameserver。如果将自定义解析加到coredns上是没有效果的,所以需要修改nodelocaldns的配置,将其他域名的解析转到coredns上才行。
1 #forward . /etc/resolv.conf
2 forward . 10.233.0.3 {
3 force_tcp
4 }
Service
Service 通过标签选择 pod,将各 pod 的 ip 保存到它的 endpoints 属性中。Service 的收到的请求会被均摊到这一组 endpoints 上。
DNS
在 k8s 中做服务发现,最常用的方式是通过 DNS 解析。
在我们的 k8s 集群配置了 dns 服务(最常用的是 coredns)的前提下,我们就可以直接通过全限定域名(FQDN)来访问别的服务。
全限定域名的格式如下:
1 # 格式
2 <service-name>.<namespace>.svc.cluster.local # 域名 .svc.cluster.local 是可自定义的
3
4 # 举例:访问 default 名字空间下的 nginx 服务
5 nginx.default.svc.cluster.local
如果两个服务在同一个名字空间内,可以省略掉后面的 .<namespace>.svc.cluster.local,直接以服务名称为 DNS 访问别的服务
P.S. DNS 服务发现的实现方式:修改每个容器的 /etc/resolv.conf,使容器访问 k8s 自己的 dns 服务器。而该 dns 服务器知道系统中的所有服务,所以它能给出正确的响应。
SRV 记录
Service 除了会使用最常见的 A 记录做 Pod 的负载均衡外,还提供一种 SRV 记录,这种类型的服务被称为 Headless Service.
将 Service 的 spec.ClusterIP 设为 None,得到的就是一个 Headless Service。
普通的 Service 拥有自己的 ClusterIP 地址,service name 会被 DNS 解析到这个虚拟的 ClusterIP(A 记录或 CNAME 记录),然后被 kubectl proxy 转发到具体的 Pod。
而 Headless Service 没有自己的 ClusterIP(这个值被指定成了 None),service name 只提供 SRV 记录的 DNS 解析,返回一个 Pods 的 ip/dns 列表。
SRV 记录最常见的用途,是在有状态集群中,给集群的所有 Pod 提供互相发现的功能。
最佳实践
- 总是使用 Deployment,避免直接使用 ReplicaSet/Pod
- 为 Pod 的 Port 命名(比如命名成 http/https),然后在 Service 的 targetPort 中通过端口名称(http/https)来指定目标端口(容器端口)。
- 更直观,也更灵活
- 应用通过 dns 查找/发现其他服务
- 同一名字空间下的应用,可以直接以服务名称为域名发现别的服务,如通过
http://nginx访问 nginx
- 同一名字空间下的应用,可以直接以服务名称为域名发现别的服务,如通过
- Service 配置会话亲和性为 ClientIP 可能会更好(会话将被同一个 pod 处理,不会发生转移)
- 配置 externalTrafficPolicy: Local 可以防止不必要的网络跳数,但是可能会导致 pod 之间的流量分配不均。
k8s入坑之路(10)kubernetes coredns详解的更多相关文章
- k8s入坑之路(4)kubenetes安装
三种安装方法: 1.kubeadm 2.kubespray 3.二进制安装 kubespray安装kubernetes集群 优点: 1.kuberspray对比kubeadm更加简洁内部集成了kube ...
- k8s入坑之路(7)kubernetes设计精髓List/Watch机制和Informer模块详解
1.list-watch是什么 List-watch 是 K8S 统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能等等,为声明式风格的API 奠定了良好的基础,它是优雅的通信方式,是 ...
- k8s入坑之路(16)kubernetes中CICD/基于宿主机jenkins
cicd的结合组件 需要代码仓库如gitlab.github.包构建工具Maven等,持续集成工具如jenkins,github/cicd.结合自己脚本实现重复式任务自动化. 传统服务发布流程: 提交 ...
- k8s入坑之路(15)kubernetes共享存储与StatefulSet有状态
共享存储 docker默认是无状态,当有状态服务时需要用到共享存储 为什么需要共享存储: 1.最常见有状态服务,本地存储有些程序会把文件保存在服务器目录中,如果容器重新启停则会丢失. 2.如果使用vo ...
- k8s入坑之路(13)kubernetes重要资源(namespace隔离 resources资源管理 label)
Namespace --- 集群的共享与隔离 语言中namespace概念 namespace核心作用隔离 以上是隔离的代码.namespace隔离的是: 1.资源对象的隔离:Service.Depl ...
- k8s入坑之路(11)kubernetes服务发现
kubernetes访问场景 1.集群内部访问 2.集群内部访问外部 3.集群外部访问内部 1.集群内部访问 1.pod之间直接ip通讯(利用calico通过路由表经过三层将ip流量转发)由于容器之间 ...
- k8s入坑之路(2)kubernetes架构详解
每个微服务通过 Docker 进行发布,随着业务的发展,系统中遍布着各种各样的容器.于是,容器的资源调度,部署运行,扩容缩容就是我们要面临的问题. 基于 Kubernetes 作为容器集群的管理平 ...
- 【转载】k8s入坑之路(2)kubernetes架构详解
每个微服务通过 Docker 进行发布,随着业务的发展,系统中遍布着各种各样的容器.于是,容器的资源调度,部署运行,扩容缩容就是我们要面临的问题. 基于 Kubernetes 作为容器集群的管理平台被 ...
- k8s入坑之路(14)scheduler调度 kubelet管理及健康检查 更新策略
kubelet 主要功能 Pod 管理 在 kubernetes 的设计中,最基本的管理单位是 pod,而不是 container.pod 是 kubernetes 在容器上的一层封装,由一组运行在同 ...
随机推荐
- P1013 [NOIP1998 提高组] 进制位
解析 看到这道题时,有没有想到搜索?然后就是一通码......然后过了. 但是,真的要用搜索吗? 我们可以观察一下.对于n进制中的数ii,如果ii加上某一个数jj会变成两位数,那么可以得到如下不等式: ...
- linux帐户安全管理与技巧
实验环境 CentosOS5.6试验台. 任务一:建立与删除普通用户账户,管理组 1)创建一个新用户user1 useradd user1 查看用户是否创建成功 2)创建一个新组group1 grou ...
- 常用的ppt技巧
取色器 对齐 形状使用
- 常用的word技巧
自动生成标题 自动生成目录 显示导航列 修订 查看最终版本
- docker启动jenikns,提示 :This image is for research only, DO NOT USE
下载的jenkins镜像有问题?
- css 背景图片路径问题
背景图片路径找寻失败问题 1.加~ background-image: url("~@/assets/login/login-bg.png"); background-size: ...
- P3706-[SDOI2017]硬币游戏【高斯消元,字符串hash】
正题 题目链接:https://www.luogu.com.cn/problem/P3706 题目大意 给出 \(n\) 个长度为 \(m\) 的 \(H/T\) 串. 开始一个空序列,每次随机在后面 ...
- ES5新增方法--查找方法--forEach(),filter(),some()区别
1.forEach方法 迭代(遍历)数组 var arr = [1, 2, 3]; var sum = 0; arr.forEach(function (value, index, array) { ...
- Geocoding Tools(地理编码工具)
地理编码工具 # Process: 创建地址定位器 arcpy.CreateAddressLocator_geocoding("", "", "&qu ...
- uoj279题目交流通道(dp)
题目大意: 神犇星球有 \(n\) 座小城.对于任意两座小城 \(v,u\)\((v≠u)\),吉米多出题斯基想在 \(v,u\) 之间建立一个传送时间为 \(w(v,u)\)的无向传送通道,其中 \ ...