SQL Server 临时表和表变量系列之选择篇
原文地址:https://yq.aliyun.com/articles/69187
摘要: # 摘要 通过前面的三篇系列文章,我们对临时表和表变量的概念、对比和认知误区已经有了非常全面的认识。其实,我们的终极目的,还是今天要讨论的话题,即当我们面对具体的业务场景的时候,该选择临时表还是表变量? # 几种典型场景 以下是几种典型的场景,让我们看看到底该作何选择,以及做出最终选择的具体原因和考量。 ## 存储过程嵌套 在SQL Server中,使用存储过程的好处显而易见,往往会节约
摘要
通过前面的三篇系列文章,我们对临时表和表变量的概念、对比和认知误区已经有了非常全面的认识。其实,我们的终极目的,还是今天要讨论的话题,即当我们面对具体的业务场景的时候,该选择临时表还是表变量?
几种典型场景
以下是几种典型的场景,让我们看看到底该作何选择,以及做出最终选择的具体原因和考量。
存储过程嵌套
在SQL Server中,使用存储过程的好处显而易见,往往会节约存储过程执行计划编译时间,提高查询语句的执行效率。有时候,我们在构建存储过程多层次嵌套场景中,会有内层存储过程需要临时使用外层存储过程的“暂存”数据。在SQL Server暂存临时数据的方法可以使用临时表或者表变量,但是在这种场景中,仅临时表适合。比如,下面的例子:
-- Scenario 1: Nest Store Procedure
USE tempdb
GO
IF OBJECT_ID('tempdb..#UP_Inner', 'P') IS NOT NULL
DROP PROC #UP_Inner
GO CREATE PROC #UP_Inner
AS
BEGIN
SET NOCOUNT ON
UPDATE A
SET Comment = 'INNER'
FROM #temp AS A
WHERE RowID = 1;
END
GO IF OBJECT_ID('tempdb..#UP_Outer', 'P') IS NOT NULL
DROP PROC #UP_Outer
GO
CREATE PROC #UP_Outer
AS
BEGIN
SET NOCOUNT ON IF OBJECT_ID('tempdb..#temp', 'U') IS NOT NULL
DROP PROC #temp
CREATE TABLE #temp(
RowID INT IDENTITY(1, 1) NOT NULL PRIMARY KEY
,Comment VARCHAR(100) NULL) INSERT INTO #temp(Comment) VALUES(''),('OUTER') -- check the data before call inner SP
SELECT * FROM #temp
-- call the inner store procedure
EXEC #UP_Inner -- check the data after call inner SP
SELECT * FROM #temp
END
GO -- call the outer SP
EXEC #UP_Outer -- END Scenario 1: Nest Store Procedure
执行结果展示如下: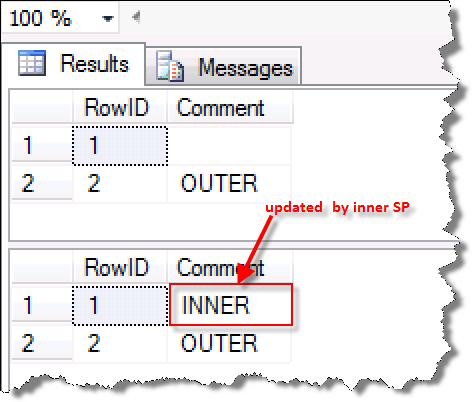
我们在内层存储过程将临时表#temp字段Comment更新为INNER;外层存储过程在调用内层存储过程前后分别查询临时表的数据。从这个结果来看,内层存储过程完全可以使用外层存储过程创建的临时表。这种场景无法使用表变量,因为内层存储过程会因为表变量没有定义而报错。
服务启动自动执行存储过程
有时候,我们需要在SQL Server Service启动完毕后,立马自动执行某个存储过程以获取某些重要的数据信息。比如:我们想知道SQL Server服务启动后,到底有哪些用户连接到了SQL Server服务器。我们可以选择使用全局临时表来暂存用户信息,而且其他进程也可以查看相应的数据信息。方法如下:
-- Scenario 2: auto execution SP when startup
USE master
GO
EXEC sys.sp_configure 'show advanced options', 1
GO
EXEC sys.sp_configure 'scan for startup procs', 1
GO
RECONFIGURE WITH OVERRIDE
GO -- create sp to call when sql server serivce startup
CREATE PROC dbo.UP_GetLoginUserWhenStartup
AS
BEGIN
SET NOCOUNT ON
IF OBJECT_ID('tempdb..##temp', 'U') IS NOT NULL
DROP TABLE ##temp
CREATE TABLE ##temp(
RowId INT IDENTITY(1, 1) NOT NULL,
LoginName varchar(200) NOT NULL
) INSERT INTO ##temp
SELECT DISTINCT loginame
FROM sys.sysprocesses END
GO -- registe to auto execution when startup
EXEC sys.sp_procoption 'UP_GetLoginUserWhenStartup', 'startup', 'on'
GO -- END Scenario 2: auto execution SP when startup
重启SQL Server Service,然后新开一个连接执行下面的语句,结果如下: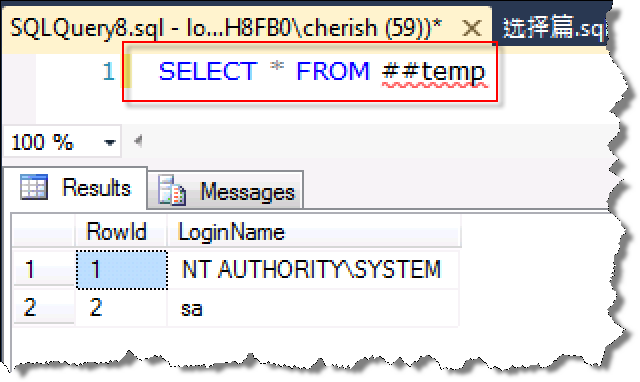
SQL Server Service重启完毕后,系统会自动执行Master数据库下的存储过程dbo.UP_GetLoginUserWhenStartup以获取到哪些用户连接到SQL Server。这个过程和Linux开机自动执行自定义脚本或者服务非常类似。由于其他进程需要查看抓取到的信息,在此使用全局临时表而不是表变量。
暂存大量数据
在很多场景我们需要暂存大量数据或者根本无法预估需要暂存的数据量。这里需要首先明确的一个问题是,到底暂存多大的数据量算大量?根据上一篇文章SQL Server 临时表和表变量系列之认知误区篇中的章节“表变量仅驻留在内存中”的内容,我们可以认为需要暂存的数据量大小接近或者超过SQL Server最大可以使用内存一半的时候,这个数据量就是大量数据。比如:当SQL Server的Max Server Memory设置为1GB,需要暂存的数据量接近或者超过512MB时,512MB就是大量数据;但是,当SQL Server Max Server Memory为10GB甚至更高,需要暂存512MB时,这个数据量又不算是大量数据。在大量数据需要暂存时,无论使用临时表或者表变量,SQL Server系统最终会将数据存在Tempdb的数据文件磁盘上。所以这个时候,请选择使用临时表来暂存数据,最好是能够根据业务场景为临时表创建合适的索引,以提高后续临时表查询语句的执行效率。
需要支持用户事务
有时候用户业务场景需要暂存的数据结构支持用户事务,在这种场景下,我们应该选择临时表。根据我们之前的文章SQL Server 临时表和变量系列之对比篇的“对事务支持”部分,我们知道,表变量不支持用户事务回滚,而临时表对用户事务的支持和正式表没有任何差异。所以,在这种场景下,我们需要选择临时表作为暂存数据结构。
表值函数的返回值
表值函数的返回值为表变量,这个场景中,是无法使用临时表来替换的。比如:我想要找出当前数据库下表名称中含有某个特定字符串的所有表信息,用表值函数来实现的方式如下:
-- Scenario: function returned temp variables
USE AdventureWorks2014
GO
IF OBJECT_ID('dbo.UTF_FindTables', 'TF') IS NOT NULL
DROP FUNCTION dbo.UTF_FindTables
GO
CREATE FUNCTION dbo.UTF_FindTables(
@partner sysname
) RETURNS @Tables TABLE(
RowID INT IDENTITY(1, 1) NOT NULL PRIMARY KEY
,tb_Object_ID BIGINT NULL
,database_name SYSNAME NULL
,schema_name SYSNAME NULL
,object_Name SYSNAME NULL
)
AS
BEGIN
INSERT INTO @Tables
SELECT object_id, DB_NAME(), SCHEMA_NAME(schema_id), name
FROM sys.tables
WHERE name like '%' + @partner + '%'; RETURN
END
GO -- Calling example
SELECT * FROM dbo.UTF_FindTables('Person')
-- END Scenario
执行结果如下所示: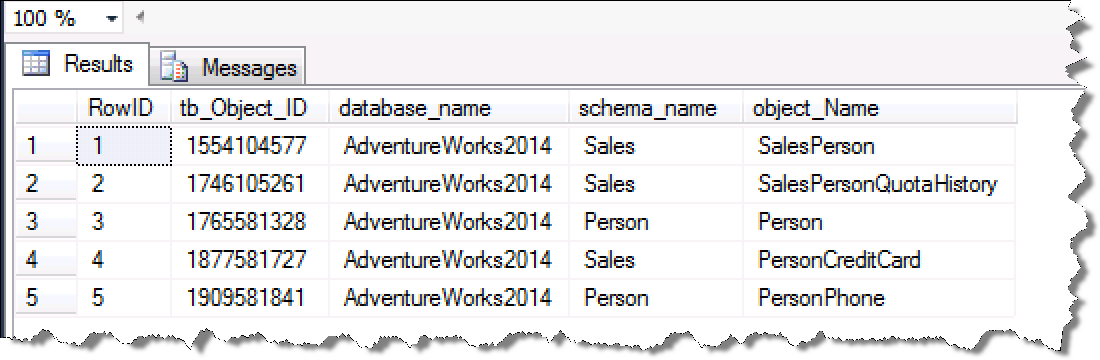
查找当前数据库下表名字中含有Person关键字的表详情。由于表值函数返回值仅支持表变量,所以这种场景中是无法使用临时表的。
高并发场景选择表变量
在SQL Server数据库高并发场景中,请慎重选择临时表的使用,建议使用表变量。对于这个场景的测试,我们会使用到SQLTest这个测试工具,关于这个工具的使用请参照我之前的文章SQLTest系列之INSERT语句测试。
首先,我们创建两个测试存储过程,它们的逻辑一模一样,唯一不同的是一个使用表变量,一个使用临时表。
USE AdventureWorks2014
GO
IF OBJECT_ID('dbo.UP_TableVariables', 'P') IS NOT NULL
DROP PROC dbo.UP_TableVariables
GO
CREATE PROC dbo.UP_TableVariables
AS
BEGIN
SET NOCOUNT ON
DECLARE @t1 TABLE(
c1 INT,
c2 INT,
c3 CHAR(2000)
) ;WITH DATA
AS(
SELECT *
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)) AS T(C)
)
INSERT INTO @t1
SELECT a.C, b.C, REPLICATE('A', 2000)
FROM DATA as a, data as b
END
GO IF OBJECT_ID('dbo.UP_TempTable', 'P') IS NOT NULL
DROP PROC dbo.UP_TempTable
GO
CREATE PROC dbo.UP_TempTable
AS
BEGIN
SET NOCOUNT ON
CREATE TABLE #t1 (
c1 INT,
c2 INT,
c3 CHAR(2000)
) ;WITH DATA
AS(
SELECT *
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)) AS T(C)
)
INSERT INTO #t1
SELECT a.C, b.C, REPLICATE('A', 2000)
FROM DATA as a, data as b
END
GO
接下来,我们使用两个Workload,每个Workload开启20个进程。Workload 1执行EXEC dbo.UP_TableVariables 100次;workload 2执行EXEC dbo.UP_TempTable 100次。测试代码如下:
USE AdventureWorks2014
SET NOCOUNT ON
DECLARE
@i INT
; SET
@i = 1
;
WHILE @i <= 100
BEGIN
EXEC dbo.UP_TableVariables --EXEC dbo.UP_TempTable
SET @i = @i + 1
END
GO
测试时间为120秒,测试的结果如下:
Workload 1:表变量在高并发场景的性能表现为:完成迭代340次,每一次数据库平均时间消耗为6.835秒。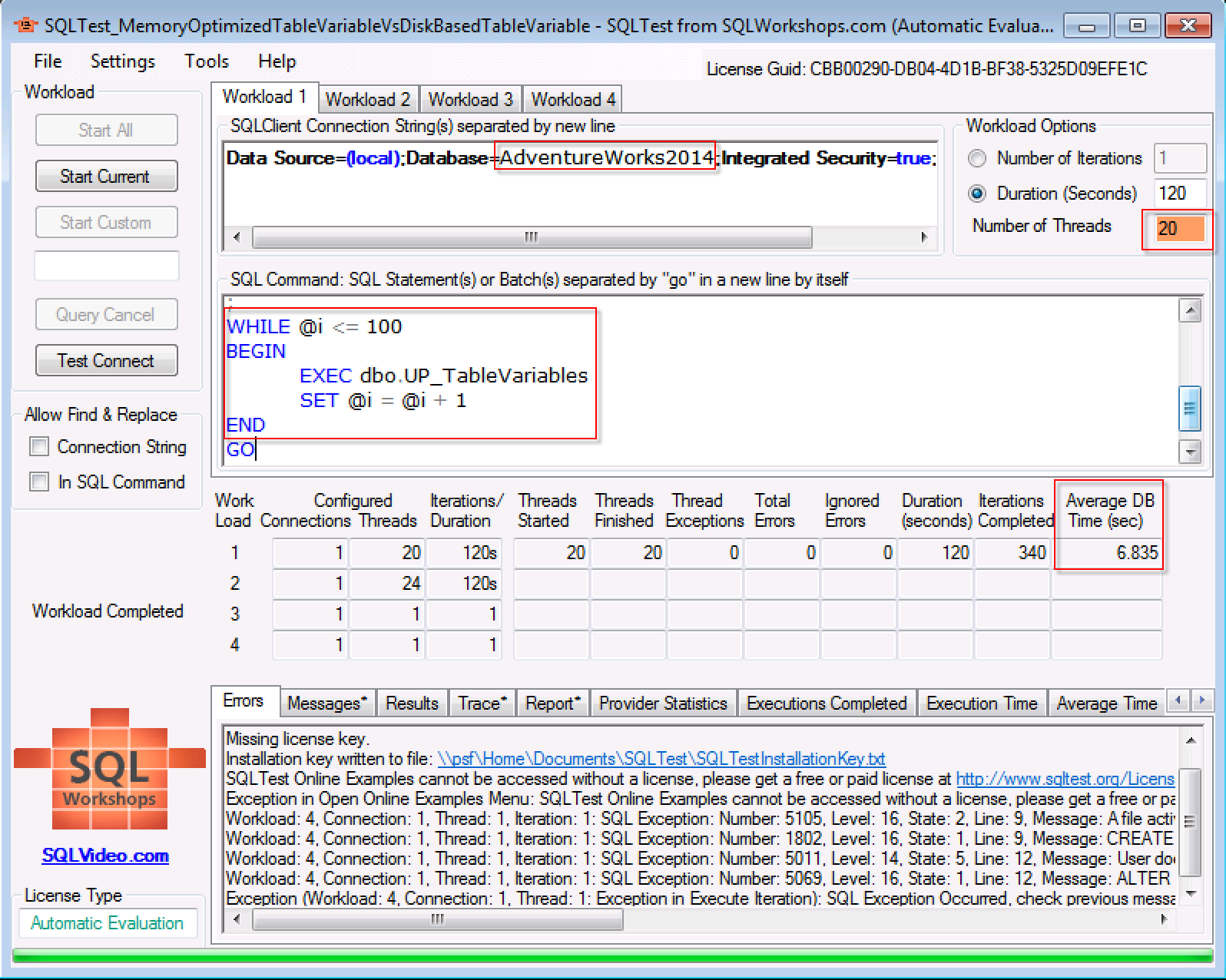
Workload 2:临时表在高并发场景下的性能表现为:完成迭代280次,每一次数据库平均时间消耗为8.321秒。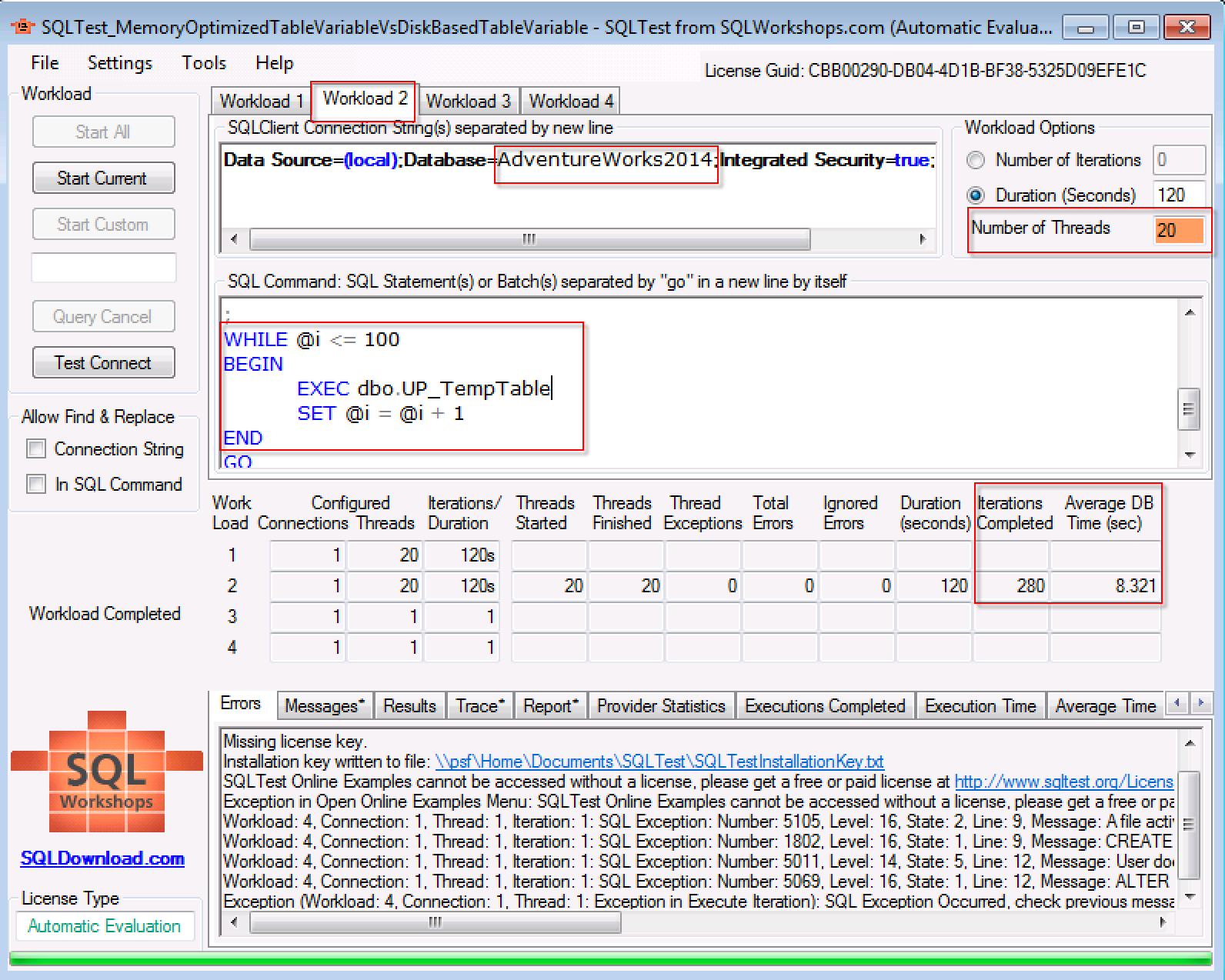
从我的测试机测试的结果来看,表变量在20个并发场景,迭代次数也有20%多的增加,相应的平均时间消耗比临时表有20%多的性能提升。基于这个测试结果来看,在高并发使用场景下,选择表变量而不是临时表。
SQL Server 临时表和表变量系列之选择篇的更多相关文章
- 小记sql server临时表与表变量的区别
临时表与表变量都可以起到“临时”的作用,那么两者主要的区别是什么呢? 这里不讨论创建方式,以及全局临时表.会话临时表这些,主要记录一下个人对两者的主要区别以及适用情况的看法,有什么不对或补充的地方,欢 ...
- SQL Server 临时表 Vs 表变量
开始 说临时表和表变量,这是一个古老的话题,我们在网上也找到很多的资料阐述两者的特征,优点与缺点.这里我们在SQL Server 2005\SQL Server 2008版本上通过举例子,说明临时表和 ...
- SQL Server 2014,表变量上的非聚集索引
从Paul White的推特上看到,在SQL Server 2014里,对于表变量(Table Variables),它是支持非唯一聚集索引(Non-Unique Clustered Indexes) ...
- Sql Server RowNumber和表变量分页性能优化小计
直接让代码了,对比看看就了解了 当然,这种情况比较适合提取字段较多的情况,要酌情而定 性能较差的: WITH #temp AS ( ...
- SQL Server 性能优化之——T-SQL 临时表、表变量、UNION
这次看一下临时表,表变量和Union命令方面是否可以被优化呢? 阅读导航 一.临时表和表变量 二.本次的另一个重头戏UNION 命令 一.临时表和表变量 很多数据库开发者使用临时表和表变量将代码分解成 ...
- SQL Server中的临时表和表变量 Declare @Tablename Table
在SQL Server的性能调优中,有一个不可比面的问题:那就是如何在一段需要长时间的代码或被频繁调用的代码中处理临时数据集?表变量和临时表是两种选择.记得在给一家国内首屈一指的海运公司作SQL Se ...
- SQL Server中的临时表和表变量
SQL Server中的临时表和表变量 作者:DrillChina出处:blog2008-07-08 10:05 在SQL Server的性能调优中,有一个不可比拟的问题:那就是如何在一段需要长时间的 ...
- [转]SQL Server中临时表与表变量的区别
[转]http://blog.csdn.net/skyremember/archive/2009/03/05/3960687.aspx 我们在数据库中使用表的时候,经常会遇到两种使用表的方法,分别就是 ...
- SQL Server进阶(十一)临时表、表变量
临时表 本地临时表 适合开销昂贵 结果集是个非常小的集合 -- Local Temporary Tables IF OBJECT_ID('tempdb.dbo.#MyOrderTotalsByYe ...
随机推荐
- 十大经典排序算法+sort排序
本文转自:十大经典排序算法,其中有动图+代码详解,本文简单介绍+个人理解. 排序算法 经典的算法问题,也是面试过程中经常被问到的问题.排序算法简单分类如下: 这些排序算法的时间复杂度等参数如下: 其中 ...
- 1.Django自学课堂
1.django manage.py startproject project_name -->创建工程 2.python manage.py startapp app_name --& ...
- mongodb 语句和SQL语句对应(SQL to Aggregation Mapping Chart)
SQL to Aggregation Mapping Chart https://docs.mongodb.com/manual/reference/sql-aggregation-compariso ...
- Http怎么处理长连接
http协议中有和keep alive特性,这个在http1.1中有, 可以保持浏览器和服务器之间保持着长连接,http本身是无连接的协议, 通过tcp实现数据的传输,处理长连接要注意什么时候数据服务 ...
- GAN笔记——理论与实现
GAN这一概念是由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题,GAN的变种更是有上千种,深度学习先驱之一的Yann LeCun就曾说,"GAN及其变种是数十 ...
- synchronized锁住的是代码还是对象
不同的对象 public class Sync { public synchronized void test() { System.out.println("test start" ...
- 【leet-code】712. 两个字符串的最小ASCII删除和
题目描述 给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和. 示例 1: 输入: s1 = "sea", s2 = "eat" ...
- InnoDB存储引擎--Innodb Buffer Pool(缓存池)
InnoDB存储引擎--Innodb Buffer Pool(缓存池) Innodb Buffer Pool的概念 InnoDB的Buffer Pool主要用于缓存用户表和索引数据的数据页面.它是一块 ...
- Extjs4.2+webAPI+EF实现分页以及webapi的数据传值
由于不明白分页的总数是怎么计算,不知道他的分页方式所以花费了好多功夫,现在弄出来了与大家分享下 1.首先是EF的简历,想必大家都清楚:添加-〉新建项-〉数据-〉Ado.net实体数据模型 2.就是后台 ...
- 【Java并发编程】18、PriorityBlockingQueue源码分析
PriorityBlockingQueue是一个基于数组实现的线程安全的无界队列,原理和内部结构跟PriorityQueue基本一样,只是多了个线程安全.javadoc里面提到一句,1:理论上是无界的 ...